Неожиданная связь числа операндов со общим количеством действий в программе
Перед Вами обычная схема вычислений – левее всего расположены операнды (исходные данные, их 2 шт.), в центре непосредственно эти данные обрабатывающий оператор и правее всего находится результат операции.

Удивительная связь (конечно, оценочная!) общего числа операций (а значит, и время обработки данных) при вычислениях определяется числом операндов (входных данных), обрабатываемых машинной командой (миниатюра выше).
Традиционно система команд современных компьютеров в основном повторяет набор арифметико-логических функций в современной математике, обладающих а́рностью (числом входных операндов для обработки) не более 2-х (есть одноа́рные – напр., тригонометрические). Это определяет нижний предел числа срабатываний вычислителей в вычислительной системе как log2(N), где N – общее число исходных данных для расчёта по данному алгоритму. Т.о. подтверждается, что последовательность действий определяется причинно-следственными соотношениями – каждое действие может быть выполнено только после окончания предшествующих действий, обеспечивающих получение (вычисление) операндов для совершения данного. При многотактовой работе придётся подумать над местом хранения промежуточных результатов вычислений (в простейшем случае – в общей для всех вычислителей памяти, но разумнее – в регистровой памяти вычислителей или в кэше).
Попробуем, памятуя сказанное, выявить параллелизм в произвольном (несложном, конечно) алгоритме. Никакого сложного математического анализа производить не будем – все выкладки удастся сделать на “в голове”. Кстати, мы поднимаемся всё выше по уровню сложности – уже используется слово (термин) АЛГОРИТМ..!
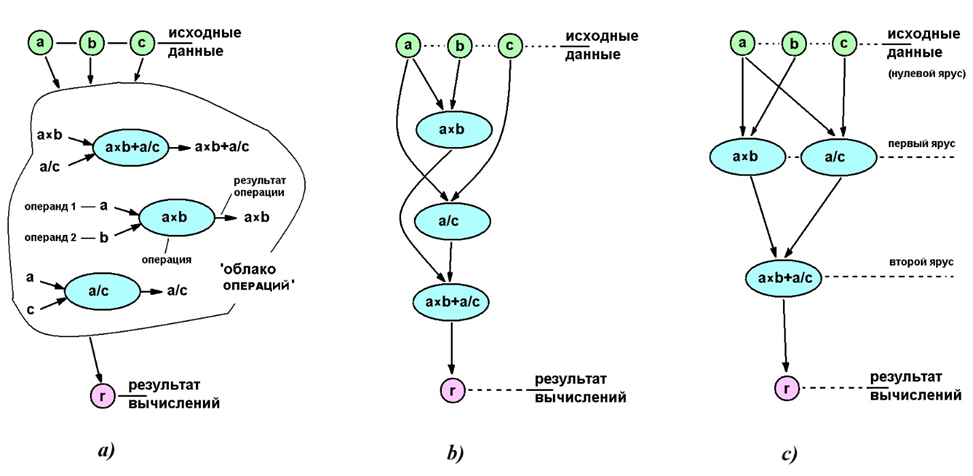
Будем анализировать вычисления согласно формулы a×b+a/c, этапы анализа показаны на рис. 4). На рис. 4 a) приведён результат декомпозиции алгоритма (этих действий 3 шт. – два предварительных действия a×b, a/c и, наконец, вычисление результата a×b+a/c). План последовательного вычисления приведён на рис. 4 б); считая время вычислений каждого действия одинаковым, получаем общее время вычислений в 3 единицы (такта). На рис. 4 в) приведён план параллельного вычисления (т.к. алгоритм вычислений предельно прост, обратная декомпозиция действие проведено “в уме”); благодаря совмещению по времени первых 2-х действий вычисление результата получаем за 2 единицы времени (2 такта). Мы в самом деле получили эффект оп параллелизмами – сократили время выполнения программы в 1,5 раз! Однако платой за подобное убыстрение вычислений заключается в ощутимом усложнении вычислительной системы – требуется 2 параллельных вычислителя (и соответствующее усложнение схем обслуживания.
Самое время продолжить писать форму́лы. Логично ввести количественную характеристику ускорения (убыстрения) процесса вычислений при параллельной обработке в форме коэффициента ускорения (или просто ускорения) вычислений kускор.:
где tпосл. и tпарр. - время выполнения вычислений при последовательном и параллельном варианте вычислений.
Соответственно эффективность параллелизации вычислений kэфф. в каждом случае может быть оценена в виде:
где P – количество параллельных вычислителей, требуемых для достижения полученного ускорения вычислений. Значение kэфф. можно использовать в качестве количественного показателя эффективности распараллеливания – при kэфф.>1 распараллеливание эффективно (ускорение вычислений превышает увеличение количества параллельных вычислителей – грубо говоря, возрастание стоимости оборудования) и при kэфф.<1 – наоборот.
Вопросы эффективности и неэффективности распараллеливания
Подводя итоги проведённого анализа заметим, что для повышения скорости вычислений по заданному алгоритму в 1,5 раза требуется не менее чем двукратное усложнение вычислительной системы - эффективность 1,5/2=0,75 согласно выражению (3), что менее единицы и “не есть очень хорошо”. Для разных алгоритмов величина ускорения вычислений при параллелизации может оказаться различной, однако для каждого конкретного алгоритма существует некоторое вполне определённое количество параллельных вычислителей, при котором ускорение вычислений максимально и в дальнейшем не увеличивается. Можно сказать, что именно при таком количестве вычислителей полностью исчерпывается внутренний потенциал параллелизма данного алгоритма и дальнейшее увеличение производительности невозможно. Дальнейшее ускорение вычислений возможно лишь при изменении алгоритма (и, соответственно, плана параллельного вычисления). Кстати, и разобранная выше формула (алгоритм) может быть преобразована по правилам арифметики, в некоторых случаях при этом возможно повышение эффективности вычислений.
Понравился ли Вам проведённый “в уме” анализ нахождения параллелизма в алгоритме и полученный результат (практическое использование параллелизма)? А можно ли результат улучшить?
Суета вокруг закона Амдаля
Закон Амдаля (Gene Amdahl, 1967) связывает потенциальное ускорение вычислений при распараллеливании с до́лей операций, выполняемых априори последовательно; формулировка его S≤1/[f+(1-f)/p+c], где S – ускорение вычислений вследствие распараллеливания, f - часть операций алгоритма, которую распараллелить не представляется возможным (0<f<1), p – число параллельных вычислителей, с - коэффициент сетевой деграда́ции вычислений (c=cw+ct=(Wc×tc)/(W×t), где Wc – количество передач данных, W – общее количество вычислений в системе, tc – среднее время одной передачи данных, t – время выполнения одной операции; при c≠0 говорят о сетево́й версии закона, при c≡0 - обычной). Суть закона – при разделении задачи на фрагменты суммарное время её выполнения на параллельной вычислительной системе не может быть меньше времени выполнения самого медленного (обычно последовательного) её фрагмента. Понятно, что предел функции S=1/[f+(1-f)/p] при p→∞ равен 1/f.
Крайне заманчиво было бы использовать значение f в качестве показателя уровня (качества) распараллеливания конкретной программы. Всё это очень хорошо в теоретическом смысле, но практическое применение формулы Амдаля в действительности невозможно (хотя бы потому, что крайне затруднительно определить часть операций, которые можно или нет распараллелить).
…А по данным запусков программы на разном количестве вычислительных узлов попробовать оценить значение f (до́лю нераспараллеленных вычислений)? На вышеприведённой миниатюре показаны данные серии экспериментов на кластере SCI-MAIN НИВЦ МГУ на задаче умножения матриц по ленточной схеме (размерность 1’000×1’000 вещественных чисел двойной точности, опыты марта 2005 г.). Экспериментальные данные наилучшим образом (использован метод наименьших квадратов) соответствуют формуле Амдаля при f=0,051 (вывод: данный алгоритм распараллелен эффективно, т.к. доля параллельных операций составляет 95%, что вполне удовлетворительно для алгоритма). Т.е. ждать более чем 20-ти кратного увеличения производительности при выбранном способе распараллеливания данного алгоритма не следует!
Авторские ресурсы:
Информация о канале вообще и его оглавление…
- В работе мы будем использовать специализированное авторское программное обеспечение (фактически исследовательские инструменты), предназначенное для выявления в произвольных алгоритмах параллелизма и его рационального использования при вычислениях.
В.М.Баканов. Практический анализ алгоритмов и эффективность параллельных вычислений. ISBN 978-5-98604-911-3. 2023. LitRes.ru