Noise shaping (формирование шума) – смещение спектральной плотности шума в не слышимую человеком область частот. Реализуется в устройствах аналого-цифрового преобразования в виде особого фильтра.
Суть в том, что ЦАПу неведомо (и в общем-то, по барабану), с какой частотой дискретизации через него проходит цифровой сигнал, кодированный в расхожем PCM. Хоть 48 кГц, хоть 24 кГц. Лишь бы внутренние "ключи" успевали переключаться. Поэтому оцифровать посредством АЦП с 48 кГц, а потом в ЦАПе обработать, как будто сигнал имеет частоту 192 кГц – раз плюнуть. В результате слышимый шум, оп-ля, станет неслышимым. Это упрощённое толкование, но смысл проясняет.
Слух у человека существенно не линеен. На краях слышимого частотного диапазона чувствительность значительно загрублена. Т.е. самые низкие и самые высокие частоты человек слышит хуже. Так устроено природой.
Знаменитые кривые Флетчера-Мунсона, полученные эмпирически, свидетельствуют о том, что звук низкой частоты большой амплитуды (акустического давления) воспринимается одинаково громко со звуком гораздо меньшей амплитуды средней частоты. Максимальная чувствительность слуха – в области 4 кГц, минимальная – 20 Гц. На высоких частотах картина ещё более запутанная: в области 10 кГц слух притуплён, тут нашему (мозгу?) требуется более мощный сигнал. На частоте примерно 16 кГц слух обостряется, а дальше резко теряет чувствительность.
![[https://en.wikipedia.org/wiki/Equal-loudness_contour]](https://avatars.dzeninfra.ru/get-zen_doc/271828/pub_661042bd119706162b3a18c4_661042ea03750c0049bfff2d/scale_1200)
Из людей мало кто слышит до 20 кГц, а тем более до 22 кГц. Но такие индивиды встречаются: на вскидку, один на миллион. Поэтому выше 25 кГц заведомо хоть в колокола бей прямо над ухом – любой человек просто не услышит.
Гипотеза, что ультразвуковые составляющие (гармоники) музыкальных звуков влияют на слуховое восприятие, внятного подтверждения не получила. По крайней мере, более-менее равномерно распределённый в ультразвуковой области шум человек точно не слышит, в том числе при костной проводимости, т.е. не через барабанную перепонку.
Короче, в тех областях частот, где слух имеет меньшую чувствительность (например на 10 кГц), шумок можно подмешивать смело.
Про нойз-шейпинг очень толково расписано здесь – без воды и доступно для понимания. Чувствуется, чел – в теме, а не тырит копипастингом чужое.
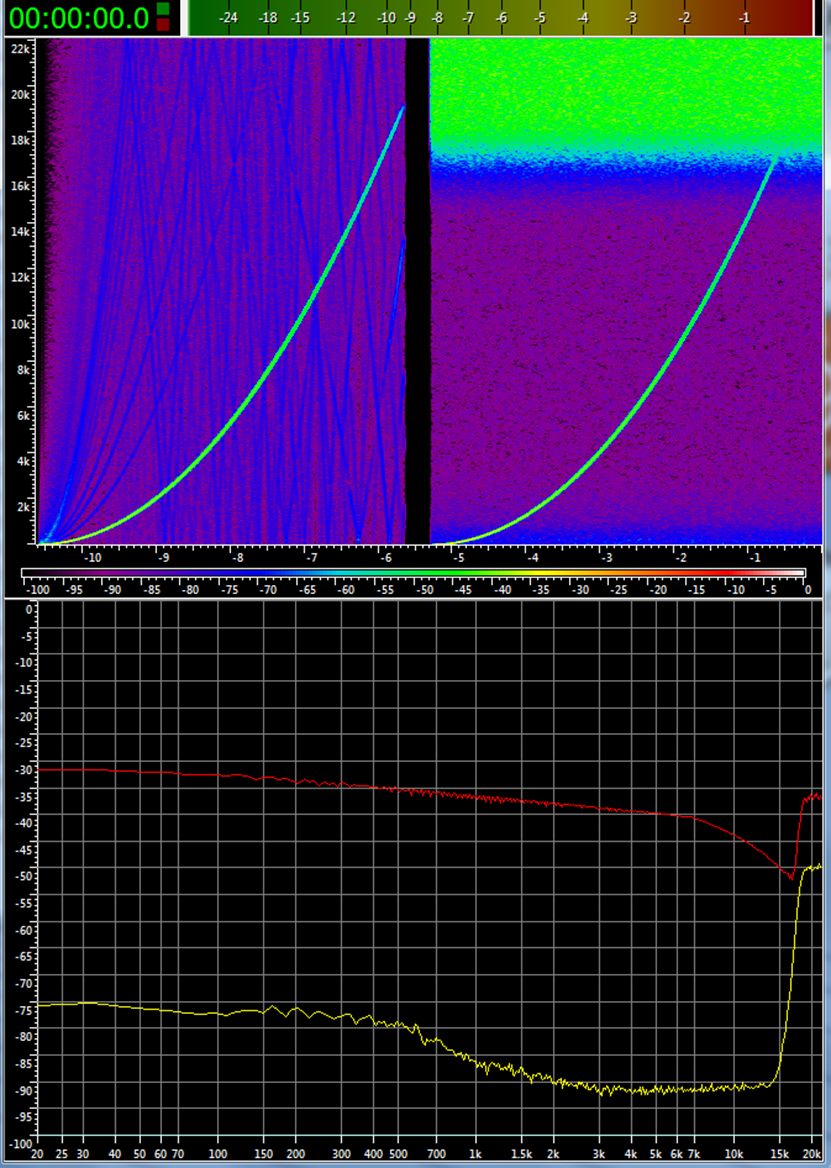
С помощью нойз-шейпинга огрехи дискретизации смещаются в неслышимую человеком область частот, т.е., как правило, выше 20-25 кГц (на данном примере – специально выше лишь 15 кГц). Особенно технология распоясалась для малобитной дискретизации. Все так называемые 1 битные ЦАПы (MASH и тп), как и все современные дельта-сигма преобразователи, фактически, ловкий обман слуха человека. Дёшево и не сердито. Просто бизнес и ничего личного.
Те же АЦП последовательного приближения (SAR) баснословно дороги, зато если и 16 бит, то честные. Так, в особо ответственных приложениях использую модули National Instruments 9223, в которых реализовано 4 канала параллельно до 1 МГц сэмплирования.
Особенности звучания TDA-1540 лучше передать с помощью оцифровки таким АЦП (с запасом 24-192), используя тестовый файл из фирменной подборки (если хотим продвинутся в аудио экспертизе, то ТРЕНИРУЕМ СЛУХОВУЮ ПАМЯТЬ!):
Конечно, услышать разницу Вы сможете только на достаточно качественных ЦАП-ах. Впрочем, в хороших современных смартфонах оные вполне вполне.
Нойз-шейпинг связки TDA1540+SAA7030 оказался чрезвычайно удачным: за
счёт вырезанных двух младших разрядов подчищаются мелкие огрехи исходной записи, в том числе привнесённый дискретизацией в 16 бит 44.1 кГц, а за 25 кГц выносятся практически все нежелательные "шумы" (точнее, огрызки от выраженных импульсных музыкальных сигналов).
Самое интересное, что TDA1540+SAA7030 раскрашивает (контрастирует) звук в слышимой области. Причём делает это на редкость своеобразно...
В чём же секрет? В нойз-шейпинге? Если нет, то в чём именно? Думается, нойз-шейпинг, даже распрекрасно реализованный, это только полдела.
Отмечу, фильтр SAA7030 работает на 4х кратной частоте передискретизации, т.е. на 176400 Гц (и борозда с жёлтыми отвалами в области 88.2 кГц на спектрограмме выше это его след). Ни один современный ЦАП оную не поддерживает, поэтому услышать в первоисточнике при программной эмуляции мы не сможем. Единственное, запрограммировать TDA1540+SAA7030 в FPGA, но это очень дорогое удовольствие.
Вглядимся-ка в спектрограмму внимательнее. В районе 15 кГц при мощных музыкальных всплесках TDA1540+SAA7030 озвучиваемый сигнал подсглаживает (красные участки), а при тихих - подтягивает (синие участки). Получается, некий динамический частотнозависимый компрессор?
[продолжение следует]
======================================================
Липшиц, Стэнли П.; Вандеркуй, Джон (2001-05-12). "Почему 1-битное сигма-дельта преобразование не подходит для высококачественных приложений" (PDF). Заархивировано (PDF) с оригинала 2023-04-30
https://en.wikipedia.org/wiki/Noise_shaping
https://aliexpress.ru/item/1005003088261307.html?sku_id=12000024007513605