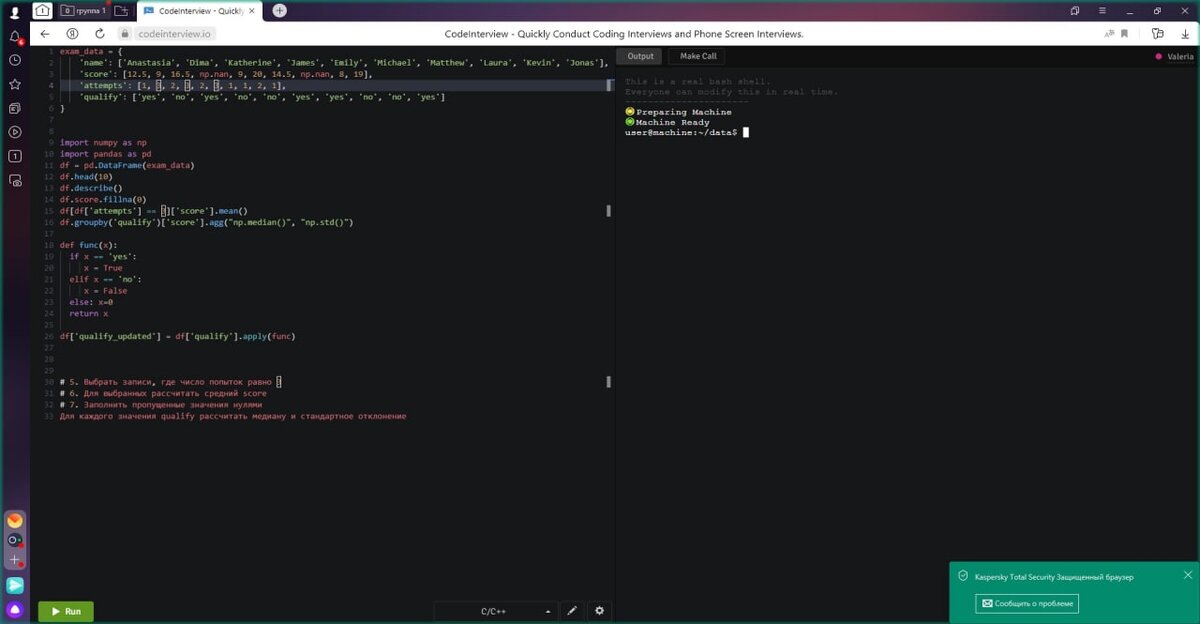
Однажды у меня было собеседование с живым кодингом. Даже не буду скрывать компанию. Это был Сбербанк. Они искали аналитика данных со знанием Питона, SQL и опытом проведения A/B тестов в команду для улучшения их банковских приложений.
У меня не было опыта A/B тестов, но я все равно откликнулась ради опыта. Вообще, хочу порекомендовать проходить как можно больше собеседований и относиться к ним как к квесту. Чем больше в вашей копилке прохождений, тем больше опыта и больше вопросов, ответы на которые вы будете потом гуглить, чтобы знать к следующей “битве”!
Итак, эйчар из Сбера предупредила, что это будет живой кодинг, я дала добро и назначили время.
Тестирование было на сайте http://codeinterview.io/
Мне сбросили ссылку, и я зашла.
Задания были следующие:
✅Создать датафрейм из данных, которые загнаны в словарь exam_data {} из кортежей []
df = pd.DataFrame(exam_data)
✅Выбрать записи, где число попыток = 3
df[df['attempts'] == 3]['score']
✅Для выбранных рассчитать средний score
df[df['attempts'] == 3]['score'].mean()
✅Заполнить пропущенные значения нулями (это часто везде просят)
df.score.fillna(0)
Я не присвоила df['score'] изменения, поэтому тут данные изменятся, но в таблице не сохранятся, нужно вот так, чтобы они остались в таблице:
df['score'] = df.score.fillna(0)
✅Для каждого значения qualify рассчитать медиану и стандартное отклонение
Вот тут я не смогла быстро сориентироваться, так как опыта было мало, но мне подсказали, что нужно вот так через библиотеку Numpy:
df.groupby('qualify')['score'].agg("np.median()", "np.std()")
Самое прикольное, что так у меня не сработало, но я нашла как нужно уже после собеса.
В Питоне уже есть встроенные функции и медианы (median) и стандартного отклонения (std). Так что Numpy нам тут не нужен.
df.groupby('qualify')["score"].agg(['median', 'std'])
Я сохранила для вас ноутбук с этим кодом тут
Скачивайте, тренируйтесь и экспериментируйте!