
Здравствуйте, дорогие друзья. Поздравляю вас с наступлением весны. Вот и отступила зима с метелями, морозами и холодными ветрами, и пришел солнечный март с его масленичными днями, капелью и весенними мелодиями. Я до сих пор помню, как в детстве мне как раз весной подарили пластинку с песнями, музыку к которым сочинил В.Шаинский. Я заслушивался песнями с этой пластинки (они мне очень нравились ), среди которых была песенка с такими странными словами:
Что это такое — зима без "ма",
Это всё равно, что каток без "ток".
И ,конечно, если игра без "ра",
Это что угодно, только вовсе не игра.
Слова странные, хотя мелодия очень классная, мне нравилась и сейчас нравится. И вот сегодня я проснулся и подумал... а серьезно, что это такое - зима без "ма" с точки зрения программирования. Кроме того, мы с вами давно не брали в руки Python, настала пора немного вспомнить и этот язык программирования, набирающий всё большую популярность...и поработать на нем со словами.
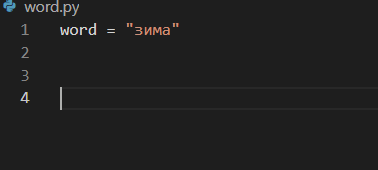
Итак, открываем visual studio code, открываем новую папку File - Open Folder и создаем новый файл word.py. Начинаем работать в нем.
Создаем переменную word, в которую заносим слово, с которым будем работать (пусть это будет слово "зима"). Это будет наше исходное слово, с ним и будем работать.
Сколько букв в зиме?
Давайте посчитаем, сколько букв в нашем исходном слове. Изменим нашу программу так:
Пишем в терминале или в командной строке python word.py и получаем результат:
Отлично, букв в слове "зима" 4. Вот какой у нас умный python, мы может теперь определять длину строки
Зимы много не бывает
А теперь давайте перепишем нашу программку вот так:
Обращает на себя последняя строка. С любым другим языком вы бы мне сказали: "Автор, да тебе что, контейнер с ssd-накопителями на голову упал? Мыслимое ли дело - производить операции умножения над строковой переменной? Ошибка ведь выйдет". И были бы правы.
Но... мы же на python. Запускаем нашу программу, и... ошибки нет:
Первый результат - это понятно, количество букв в нашем слове так и осталось четыре. Но дальше... он просто записал наше слово три раза подряд, и получилась какая-то волшебная нескончаемая "зимазимазима". Значит...в python можно проводить какие-либо арифметические операции со строками.
Что же, давайте попробуем суммировать две строки:
Как видим, две наших строки сложились в одну, и получилось "зима закончилась". Это явление называется конкатенация, то есть сложение строк.
А если произвести вычитание, то есть в буквальном смысле получить "зима" без "ма"? Попробуем, что мы теряем:
Здесь получилась ошибочка - вычитания строки из строки не предусмотрено. Первая наша попытка получить "зима" без "ма" провалилась.
Выводим часть слова
Но не всё так печально, может сказать мне более опытный программист, читающий эти строки. Ведь можно вывести часть слова "зима". И будет абсолютно прав. Но прежде, чем нам перейти к этому, давайте рассмотрим доступ к каждой букве нашего слова по индексу. В языке python доступ к каждому элементу строки осуществляется точно также как к элементам массива (начиная с элемента 0 ):
Когда у нас с вами получился доступ к каждой позиции по индексу, то мы можем получить часть слова, т.е. срез. Извлечение среза производится следующим образом: [X:Y]. X – начало среза, а Y – окончание среза. То есть word[0:2] - это часть слова с нулевой по вторую позицию. Давайте проверим это:
Вот мы и получили наше искомое "зима" без "ма" !
Работает это, правда своеобразно, и в "обратной проекции" : если в качестве индекса позиции поставить отрицательное число, буква тоже выйдет, но позиции будут считаться с конца слова.
Что же будет, если добавить отрицательные числа в срезы? Посмотрим:
Отрицательный второй параметр наоборот убирает у исходного слова символы... столько символов, сколько единиц содержит второй параметр.
Словесная динамика.
Возникает вопрос, а может ли python искать контекст в строке, заменять его, переводить всю строку в заглавные буквы или наоборот в маленькие, строчные и т.д. Конечно может. И мы это всё сейчас опробуем. Но для этого заменим наше слово "зима" на более длинное. Пусть это будет слово "масленица".
Поиск контекста
Итак, поиск контекста. Помнится, Шерлок Холмс определил, из какой статьи "Таймс" были вырезаны слова для записки-предупреждения об опасности торфяных болот. Сможем ли мы найти в нашем длинном-предлинном слове найти имеющиеся буквы или словосочетания? И покажет ли нам программа, что такого слова, буквы или сочетания букв в данном слове нет? Используем для такого поиска функцию find:
Всё сработало. Функция find помогла нам выявить, что слог "ле" находится на третьей позиции в слове "масленица" (если считать, что первая позиция - 0). А при поиске "щ" функция нам вывела -1. Это не значит, что буква "щ" скрывается на минус первой строке. Индекс -1 указывает там, что такого символа в слове нет.
Замена символов.
Как-то в "Комсомольской правде" я вычитал шутку, что если в слове хлеб сделать четыре ошибки, получится слово пиво. А можем ли мы в слове зима сделать четыре ошибки, чтобы получить слово лето? Давайте попробуем (вы если хотите, можете экспериментировать со словами хлеб и пиво).
А ведь заменилось. А вы говорите - по щучьему велению...
Строчные буквы, прописные буквы и имена собственные
Прежде чем колдовать над словами, превращая все буквы в этом слове то в строчные, то в прописные, давайте разберемся сначала, что означают эти понятия. Я если честно тоже частенько путаюсь. Заглавные (большие) и маленькие буквы - это еще с раннего детства понятно, а строчные и прописные... тут как-то для детского ума не так явно всё. Давайте обратимся к википедии:
Итак, прописная буква, заглавная буква, большая буква - это одно и то же. То есть буква в верхнем регистре. А что такое строчная буква?
Строчная - это соответственно маленькая (буква в нижнем регистре). Разобрав это, вернемся к программированию.
Итак, функция upper переводит все буквы в верхний регистр, функция lower - в нижний (правда у нас и так всё было в нижнем), а title делает первую букву заглавной, остальные - строчными (то что надо для имен собственных. Шикарная вещь, если в таком виде нужно печатать фамилии, имена, города, - можно не заморачиваться с регистром, программа сделает всё что надо сама).
А есть еще и swapcase:
Функция swapcase переводит буквы нижнего регистра в верхний, а верхнего - в нижний.
Этими функциями работа со словами конечно не ограничивается. Python имеет широкий функционал работы со строками в плане определения наличия цифр, символов, а также форматирования, экранирования символов, обработки текста и т.д. При наличии обратной связи с вашей стороны, уважаемые читатели, мы обязательно вернемся к работе со строками и рассмотрим их.
Пара слов к тем, кто программирует на C#. В сети достаточно много сравнивают программирование на C# и python, причем есть конструктив, а есть и холивар. Я люблю программировать и на си шарпе, и на питоне, и обещаю вам, что статья, как работать со строками на C# и .net выйдет в ближайшее время. Подписывайтесь и следите за публикациями.
P.s. Ну и я не хочу отказывать себе и вам в удовольствии еще раз послушать ту песенку, о которой я говорил в начале. Слушаем:
#python #csharp