
Привет!
Меня зовут Евгений и больше года назад я писал в этом блоге о том, что такое Stable Diffusion. Хотя скорее о том, как я все это дело понимаю и использую. Ведь сварщик я не настоящий и практически все делаю просто интуитивно.
За этот год утекло много воды, многое в моей жизни изменилось, а что-то осталось прежним. Ну вы понимаете, все как у всех.
Однако, за этот год, да что там за год... В феврале я снова начинаю погружаться в мир нейрогенераций, день-ночь сменяют друг друга, множатся папки с генериками на разные темы на моем жестком диске и за это время я ловлю сразу несколько обновлений. Год назад я колупался в версии SD 1.5, а 1.6 "сыровата". Сегодня версия XL, а пока я просто вникаю в workflow - люди начинают накидывать примеры генераций из обновления Cascade и труляля, OpenAI выкатывает SD версии 3.0 и все это у меня на глазах, пока я только вспоминаю что к чему. И это я вам еще про SVD не упомянул.
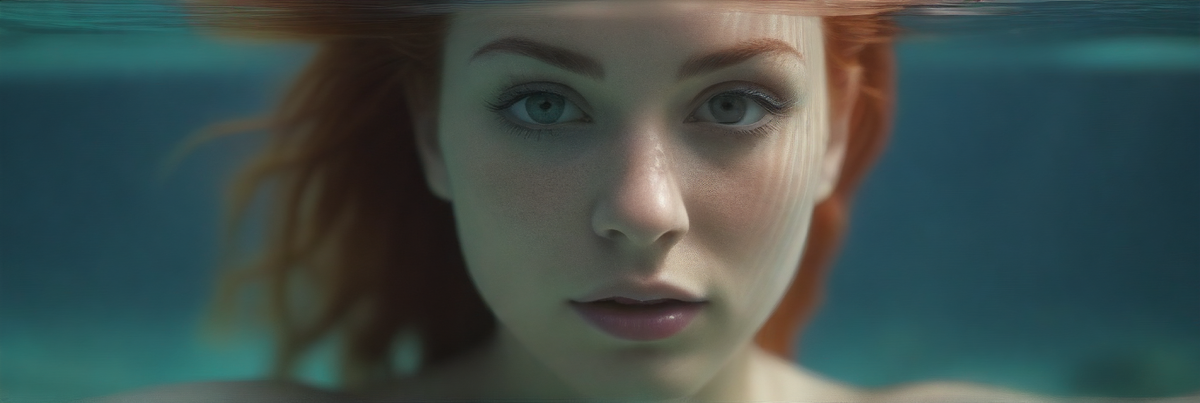
Немного теории от диванного эксперта.
Но давайте начнем с начала.
Stable Diffusion — программное обеспечение, создающее изображения по текстовым описаниям, с открытым исходным кодом.
В конце своей прошлогодней заметки я прикрепил несколько картинок, генериков на тему, как SD может проиллюстрировать, что такое Stable Diffusion. Вот одна из них.
Почему такая иллюстрация? Потому что так "работает" нейронка. Снова напомню, что материал этот написан с обывательской позиции. Я ничего не знаю о терминах, о науке или исследованиях в этой области. Я просто вижу инструмент, пытаюсь разобраться в деталях и научиться его использовать. Сегодня мне хочется просто сделать краткое "итого", я же блогер, как никак) А значит можно и в блоге написать об этом несколько строк.
Итак, идем дальше. Вот так, как я понимаю, работает SD. Сначала создается простое изображение цветного шума. Поэтом это изображение "перетряхивается" и сканируется на предмет обнаружения совпадений.
Получается нечто схожее на такую картинку. Еще раз повторюсь, да, это я себе так представляю работу нейронки. Надо почитать научные статьи на эту тему, но... зачем читать? Сразу пиши! :)
Диффу́зия — неравновесный процесс перемещения вещества из области с высокой концентрацией в область с низкой концентрацией, приводящий к самопроизвольному выравниванию концентраций по всему занимаемому объёму.
Итак, изображение "перетряхивается" и нейронка пытается "найти" во всей этой какофонии что-то похожее на подсказку в промте. Лицо человека, птица, бегемот или дерево. Леопард, чешуя или доспехи рыцаря. Нейросеть "обучена" на тысячах тысяч фото. Помните, каждый раз, когда мы проходим капчу и указываем на какой картинке велосипед или мост - вот так мы помогаем нейронке. Вот эта херовина - велик, а вот это космический корабль. Ведь с точки зрения пикселов они между собой отличаются только компоновкой. И вот так внутри нейросети распределяются "веса" и коэффициенты. Вот это с высокой вероятностью глаз, а вот здесь трава.
Дальше в дело вступает магия работа ПО. Картинка перетряхивается снова и снова, оптимизируется, компонуется и в итоге мы получаем готовое изображение.
Собственно, версии ПО и версии обученных моделей будут отличаться. Развитие - это процесс изменения от простого к сложному. Собственно, наращивая опыт, увеличивая количество повторений - мы развиваемся. Точно так же и нейросети. Как маленький ребенок. Каждый день, каждый час, каждую минуту соприкасаясь с информацией из окружающего мира. Зрительная, слуховая, тактильная, внутренние ощущения. Все это настраивает и обучает нашу нейросеть. Так мы познаем Мир и даем этому миру свои определения. Вот это с большей вероятностью дом, а вот это буква Щ. Это плюшевая игрушка, а это папина щетина.
Допустим, стало немного яснее. Пиксели перемешиваются, а работа ПО помогает найти нужные комбинации и скомпоновать их таким образом, чтобы в итоге получилось то, что нужно. Поэтому нейронка не создает новое, но и не копирует старое. Она просто собирает маленькие пикселы в сочетания того, что я попросил "собрать". Чем лучше обучена модель, чем больше в процессе своего обучения она "увидела" примеров глаза. Чем детальнее было это обучение и с точки зрения деталей глаза, и с точки зрения количества и разнообразия глаз - тем лучше будет ее способность собрать свой вариант глаза.
Теория и практика.
На сегодняшний день существует масса способов попробовать работу нейронки. Платные и бесплатные. Существуют сайты, приложения, боты в телеграм и везде суть работы примерно одинакова. Пользователь пишет promt - подсказку, отправляет ее и получает результат.
Вот так, к примеру, промт: a man in a space suit sits on a flowering hill and looks at the sky of an unknown planet on which several moons rise and stars, galaxies and clusters are visible - "видит" Алиса из Яндекса.
Или вот вам еще вариант, но уже с другого сайта.
Есть еще discord с Midjourney:
В итоге, если я начну перечислять все доступные нейросети - список будет огого. Важный момент для понимания в том, что есть нейросеть, а есть интерфейс, с помощью которого вы пользуетесь нейросетью. Сама нейросеть - это программное обеспечение, находится оно на жестких дисках сервера, который стоит где-то и через интерфейс этим ПО можно пользоваться. Боты в телеграм, дискорд, ваш браузер - все это как мобильный телефон, который позволяет вам пользоваться возможностями сотовой связи. Разные кнопочки крутилочки, размер экрана или возможности приложений - это детали интерфейса, которые позволяют использовать на максимум все возможности мобильной передачи данных.
Поэтому я выбрал Stable Diffusion. Открытый код позволяет использовать данные и создавать нужные приложения, энтузиасты пишут код и создали интерфейсы, которые можно поставить на какой угодно компьютер и получить автономность. SD - это программное обеспечение. Это код, упакованый в файлы, которые я могу скопировать на свой компьютер и начать использовать. Другие нейросети позволяют вам через интерфейсы работать с ПО, которое находится на серверах.
Какая разница? Разница в контроле. Я могу попробовать использовать разные варианты ПО, более оптимизированные или "заточенные" на определенные действия. Я могу отключить интернет, сесть в поле с ноутбуком и снова, и снова, и снова генерировать нужные мне картинки. Плюсы и минусы - имеются. И поэтому хорошо, что есть выбор. Лично мне так удобнее.
ComfyUI и Stable Diffusion.
Еще точнее, я работаю в интерфейсе ComfyUI, который позволяет мне вот таким образом "видеть" процесс генерации.
В прошлый раз я пользовался "Автоматиком":
Сегодня это "ноды" - блоки, которые связываются между собой в цепочку. Ноды разные и выполняют разные функции. Поэтому собирая свою цепочку - я могу контролировать результат.
Это не легче или не сложнее, как мне кажется, чем другие интерфейсы, это просто выглядит так, как мне удобнее. Так я легче воспринимаю происходящее.
Например, вот такая схема. Начиная сверху, из левого угла: первая нода загружает нужное изображение. Вторая - вырезает область из изображения, для следующей ноды, которая находит и анализирует лицо. Внизу, из маленького превью делается ресайз - изменение размера, потом так же обрезается в вертикальный формат. Дальше анализируется и нейронка считывает окружение, чтобы в моей генерации так же нарисовать зелень и пальмы. В этой конкретной схеме была ошибка. Одна из нодов считывала картинку и собирала ключи, которые в дальнейшем использовались для генераци нового изображения. И эта нода ошибочно выдавала мне ключ "man" вместо "young woman" - поэтому в итоге портрет мужчины.
Но я нашел эту ошибку и победил. Наделав вот таких генераций:
Итак, в качестве выводов.
Наверняка многие уже давно погрузились в эту тему и информация для них не представляет никакого интереса. Я понимаю, но больше ориентировался на себя, изложил свое понимание для тех, кто находится на таком же уровне, а может вообще только узнал о генерациях и начинает свое путешествие в этот удивительный мир.
Более того, я не написал ничего конкретного, нет каких-то ссылок или даже намека на мой обучающий курс по работе с нейросетями. Ха-ха. Я даже не использовал нейронку, чтобы написать эту статью. Все сам! :)
Однако.
Первое: нейросети - это ПО, которое из шума генерирует новое изображение по подсказке.
Второе: нейросеть, в виде файлов, может лежать на сервере где-то в интернете, а может работать на вашем компьютере.
Третье: С нейросетью нужно работать. Она не делает из одного слова сразу идеально подходящую генерацию (хоть такое и случается), нужно экспериментировать. Пробовать и изучать. Изучать не только нейронку, как она реагирует на то или другое слово. Но и все, что вокруг. ПО, интерфейсы, железо.
Четвертое: Для того, что бы заниматься генерациями - нужно четко понимать задачу. С какой целью, какая конкретно картинка, что на ней должно быть - все это помогает создать правильный промт-подсказку для инструмента, который из шума создаст то самое, волшебное изображение.
Учитывая тот факт, что прошлый материал на тему нейросетей в моем блоге был написан год назад, ожидать скорых обновлений в этой рубрике не приходится))
Буду откровенен, не хватает времени и ресурса. Хочется сфокусироваться на чем-то одном, но этого одного очень много в моей жизни. Семья, дети. Надо доделывать дом. Скважина и электричество. Масса дел в этом направлении. Суды с застройщиком. Работа, фотографии для заказчиков тоже никуда не исчезли. Видео - эта тема мне все так же интересна и занимает огромную часть времени. Нейронки расталкивают плечами и отодвигают в стороны творческие проекты, хотя пока в обнимку с работой со стоками. Есть общие интересы, так скажем. Я еще про стримы и игры не рассказывал, а детям каждый день надо, чтоб я поиграл в Icarus или таки купил уже им Майнкрафт на айпады...
В общем, если вам интересно и есть вопросы, можно написать мне здесь в комменты, можно написать мне в телегу: вот тут мой канал по нейронкам и фотографии, можно зайти в тему нейронки и там спросить у меня оперативно. Сразу вижу и сразу отвечаю.
Надеюсь, что было полезно и мне удалось раскрыть какие-то темные моменты в нейросетках, ну и надеюсь, что не буду останавливаться на достигнутом, а генерировать не только картинки, но и статьи в этот раздел своего блога)) Картинки и видео уже точно можно смотреть))
На связи!