По умолчанию команда "pip install llama-cpp-python" поставит llama-cpp-python без поддержки ускорения на GPU.
Для поддержки различных вариантов необходимо использовать переменные окружения (документация на github https://github.com/abetlen/llama-cpp-python):
OpenBLAS (CPU): CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS"
cuBLAS (CUDA): CMAKE_ARGS="-DGGML_CUDA=on"
CLBlast (OpenCL): CMAKE_ARGS="-DLLAMA_METAL=on"
и тд.
Так как производится сборка llama.cpp необходимо установить Cmake, использовал установку через VisualStudio (скачать можно тут https://visualstudio.microsoft.com/ru/downloads/):
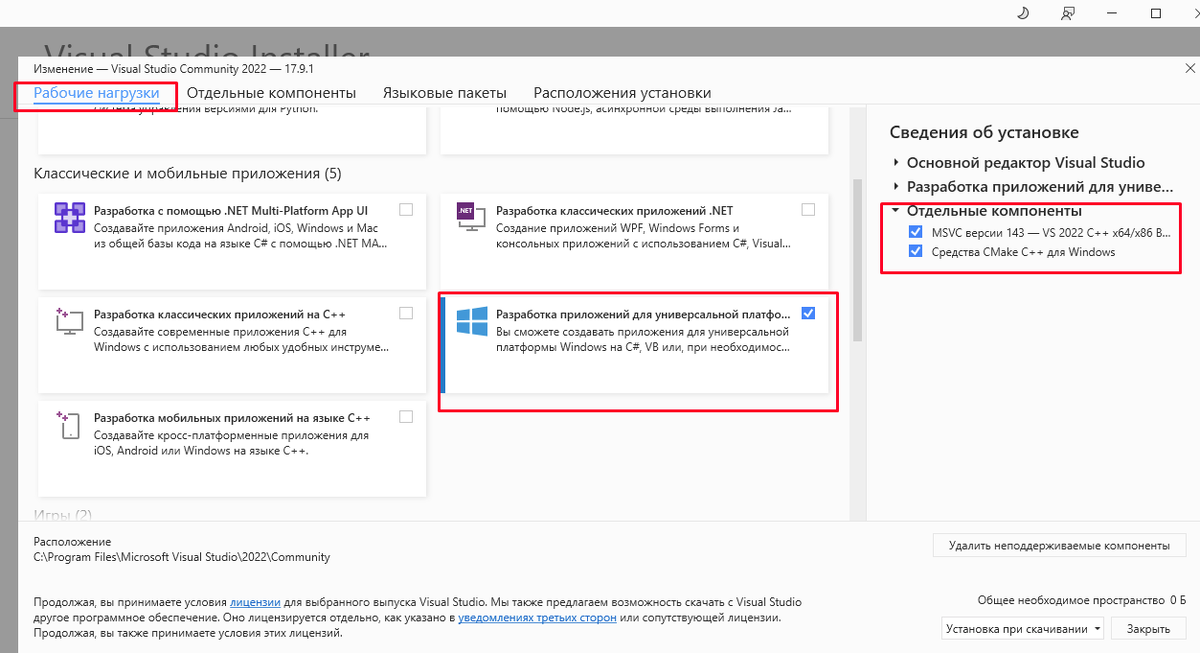
Для корректной сборки необходимо установить CUDA Toolkit(https://developer.nvidia.com/cuda-downloads?target_os=Windows), обновить драйвер видеокарты
Установку производил в виртуальное окружение Conda:
1. Добавляю переменные окружения PowerShell:
set-Item -Path env:CMAKE_ARGS -Value "-DGGML_CUDA=on"
set-item -Path env:FORCE_CMAKE -Value 1
*Вторая нужня для пересборки, если ранее уже производилась сборка с другими флагами
2. Запускаю сборку:
pip install llama-cpp-python --upgrade --force-reinstall --no-cache-dir --verbose
*Ключи --upgrade --force-reinstall --no-cache-dir нужны, если ранее уже производилась установка пактеа, --verbose добавляет детализированный вывод процесса сборки.
Если все настроено верно в логах сборки будут строки про CUDA

В конце сборки получается такой вывод: