Сложность данной задачи 20%, поэтому я в деле :)
Задача

Решение
Для начала я составлю базу из кусков чисел. Условия задачи очень многое облегчают, так как числа могут быть только 4-значные.
Если число, к примеру, равно 2512, то 25 будет головой, а 12 хвостом. У одной головы может быть несколько разных хвостов. Это чаще всего случается с треугольными числами. Например, 1035 и 1081. Но хвостов у одной головы не может быть более 3-х, на крайний случай 4-х :)
Поэтому я сделал такую структуру для хранения:
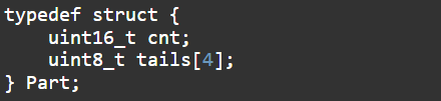
Поле cnt это количество хвостов, а массив tails[] содержит собственно хвосты. А где же голова? Головой будет сам индекс, по которому в массиве будет лежать данная структура.
К примеру, возьмём треугольные числа. Головы могут принимать значения от 10 до 99 (меньше 10 не подходят по условиям). Так что можно создать массив из 100 элементов, где индексу 10 соответствует значение головы 10, индексу 11 значение головы 11 и т.д. Индексы 0..9 пусть пропадают зря, чтобы не усложнять адресацию.
Итого массив содержит 100 элементов, где каждый элемент имеет размер 6 байт, всего получаем 600 байт. Делаем такие же массивы для 4-угольных, 5-угольных и т.д. чисел, получаем 6 массивов и всего 3600 байт. Совсем немного.
Объединяем все эти массивы в один массив, где будем выбирать нужный сегмент, зная, что первые 100 чисел треугольные, следующие 100 чисел четырёхугольные и т.д.:
#define PL_MAX_CNT 6
#define PARTS_SIZE 100
Part parts[PL_MAX_CNT * PARTS_SIZE];
Для удобства я ввожу перечислимый тип уровней фигурных чисел от 3 до 8:
Теперь заполним массив рассчитанными значениями чисел.
Здесь последовательно рассчитываются треугольные, четырёхугольные и т.д. числа. В дело идут только числа, которые больше 1009 и меньше 10000, но цикл один на всех. Каждая последовательность растёт с разной скоростью. Поэтому в какой-то момент одна последовательность уже "отстрелялась", а другие ещё нет. Чтобы это отслеживать, я делаю битовую маску busy_mask. У каждой последовательности в этой маске есть индивидуальный бит.
#define PL_ALL_BITS (1 | 2 | 4 | 8 | 16 | 32)
Первоначально активны все биты, но они гасятся по мере того как последовательности достигают своих пределов. Пока хоть один бит активен, маска не равна нулю и цикл продолжается.
Посмотрим, как работает функция регистрации числа register_part():
В неё передаётся указатель на массив parts, само число num, и уровень последовательности poly_level.
Если num > 9999, то функция возвращает маску, в которой выключен бит данной последовательности. Эта маска применяется к busy_mask, выключая там бит:
busy_mask &= register_part(...);
Если num > 1009, это подходящий диапазон, тогда я делю num на 2 части: head и tail. Заранее известно, что число 4-значное, поэтому тут можно без всяких помех получить из него нужные куски. (Гуру-питонисты, возможно, переведут его в строку, а потом разделят строку на 2 половины.)
Получив head и tail, вычисляем местоположение структуры в массиве parts:
uint16_t offset = poly_level * PARTS_SIZE + head;
Ну и далее кладём туда tail, увеличивая счётчик.
parts[offset].tails[cnt] = tail;
parts[offset].cnt++;
В результате все подходящие числа всех последовательной разбиты на головы и хвосты. Хвосты привязаны к головам. У голов есть прямые ссылки в виде индексов.
Для чего это всё было нужно?
Теперь будем перебирать последовательности по уровням от PL_3 до PL_8. В каждой последовательности будем перебирать головы. Для каждой головы будем перебирать хвосты.
Пока нормально, да?
Для каждого хвоста будем искать голову, равную этому хвосту, во всех других последовательностях. Найдя голову, будем снова перебирать её хвосты и искать головы в других последовательностях...
А кто это у нас? А это у нас рекурсия!
Сначала основной цикл, который перебирает изначальные данные и затем вызывает рекурсивную функцию:
Цикл по poly_level перебирает уровни последовательностей PL_3...PL_8. На каждом уровне проверяем головы head с индексами от 10 до 99. Если у структуры по индексу головы счётчик хвостов равен 0, значит её в данной последовательности просто нет и мы идём дальше. Иначе перебираем хвосты в ещё одном цикле по i.
Для каждого хвоста нужно найти голову из другой последовательности. Поэтому мы вызываем функцию find_chain(). Пока не будем её разбирать, а сосредоточимся на основном цикле. В функцию передаются: ссылка на хранилище parts, текущий уровень последовательности poly_level, текущий хвост p.tails[i] (который далее должен стать новой головой), текущая голова head (она нужна, чтобы потом закончить цепочку, так как с неё всё начинается), и наконец уже знакомая нам маска занятости с установленным соответствующим битом (1 << poly_level). По этой маске будет определяться, какие уровни уже участвуют в цепочке.
Предположим, функция find_chain() вернула ненулевой результат – это успех и надо заканчивать вообще всё. Я нахулиганил и применил конструкцию goto, чтобы выйти из трёх циклов сразу. Иначе пришлось бы писать ещё 2 условия с break, а я просто не хочу загромождать иллюстрации. Но если будет интересно, мы рассмотрим альтернативные решения этой проблемы.
В целом работает вот так, а теперь можно рассмотреть саму функцию find_chain():
Мы теперь смотрим на ситуацию из контекста функции, которой что-то передали: ссылка на массив parts, уровень последовательности poly_level, текущая голова (снаружи это был хвост, но тут он уже новая голова) head, финальная голова target, к которой мы должны прийти, и маска занятости busy_mask.
Задача функции: в любом уровне последовательностей найти голову с индексом head. Для этого она тоже организует цикл по уровням pl, но обратим внимание, что сюда уже передана маска занятости от внешнего уровня. Поэтому, если в маске занятости есть бит уровня self_mask, этот уровень пропускается. Затем мы делаем новую маску занятости bm, добавляя self_mask к busy_mask.
Находим структуру с хвостами по индексу head.
Part p = parts[pl * PARTS_SIZE + head];
Перебираем хвосты, если они есть. И тут возможны два варианта:
Если текущая маска занятости bm равна PL_ALL_BITS, значит все уровни последовательностей исчерпаны, этот – последний. Значит, именно на этом уровне какой-то хвост головы должен совпасть с target. Если это произошло, мы возвращаем результат в виде текущего найденного числа, которое вычисляется как head * 100 + target. Рекурсия завершилась.
Если же остались свободные уровни, значит текущий хвост надо сделать новой головой и вызвать функцию рекурсивно, передавая хвост как новую голову и маску bm. Обратите внимание, что в bm уже занят бит текущего уровня, и будет оставаться занятым до возврата из рекурсии. Поэтому при каждом рекурсивном вызове занятых уровней становится на один больше, пока не придём к финалу.
Получив результат из рекурсии, функция складывает его с собственным найденным числом и возвращает выше по цепочке, где происходит то же самое до полного выхода из всех вызовов.
Для наглядности можно посмотреть на лог вызовов:
Финальная проверка (final check) расположена самой первой, потому что именно с неё начинается возврат назад. Она произошла на уровне 2 (PL_5). Вызов происходил с уровня 3 (PL_6), в свою очередь он был вызван с уровня 5 (PL_8) и т.д., а родоначальником всех вызовов (root check) был уровень 0 (PL_3).
Ссылка на онлайн-компилятор языка C с текстом программы
Заключение
- Рекурсию сложно объяснять, но радостно понимать. Если не понимаете, старайтесь – день, два, неделю, сколько нужно. Оно придёт.
- Задача оказалась довольно лёгкой, хотя поначалу казалась ещё легче. Тут прямо-таки полный перебор всего-всего, но ввиду малого количества данных всё работает очень быстро, так что думать над оптимизациями не стал.
- Возможно получить правильный ответ при неправильно работающей программе. Я задачу поначалу так и решил, но сумма у меня была не из 6, а из 7 чисел. Так что получение правильного ответа, увы, ещё не признак рабочей программы. Хотелось бы, чтобы критерии правильности ответов в проекте Эйлер были более строгие.
Подборка всех задач: