Наконец-то разметил 100 страниц манги для тренировки второй версии детектора. Первая версия неплохо детектировала текстовые блоки (даже лучше easyocr), но в том виде, в котором был результат удалял слишком много информации. Что было нежелательно, так как я планировал восстанавливать фон, а там чем меньше удаляешь - тем, в теории, лучше результат.

Во вторую версия я заложил возможность распознавания 4 типов данных. Баблы обычные, баблы квадратные, баблы "солнышко" и просто текст на фоне. Но для того нужно было переразметить датасет. Если датасет для первой версии я разметил где-то за полтора часа, то вот на этот... В общем несколько дней я на это потратил.
Не полный день, естественно, но ушло много. В среднем на нармальную разметку бабла нужно от минуты до пяти (а на некторые и больше). Звучит немного, но на странице может быть до 10 баблов, что в результате дает приличное количество времени. Несколько примеров ниже.

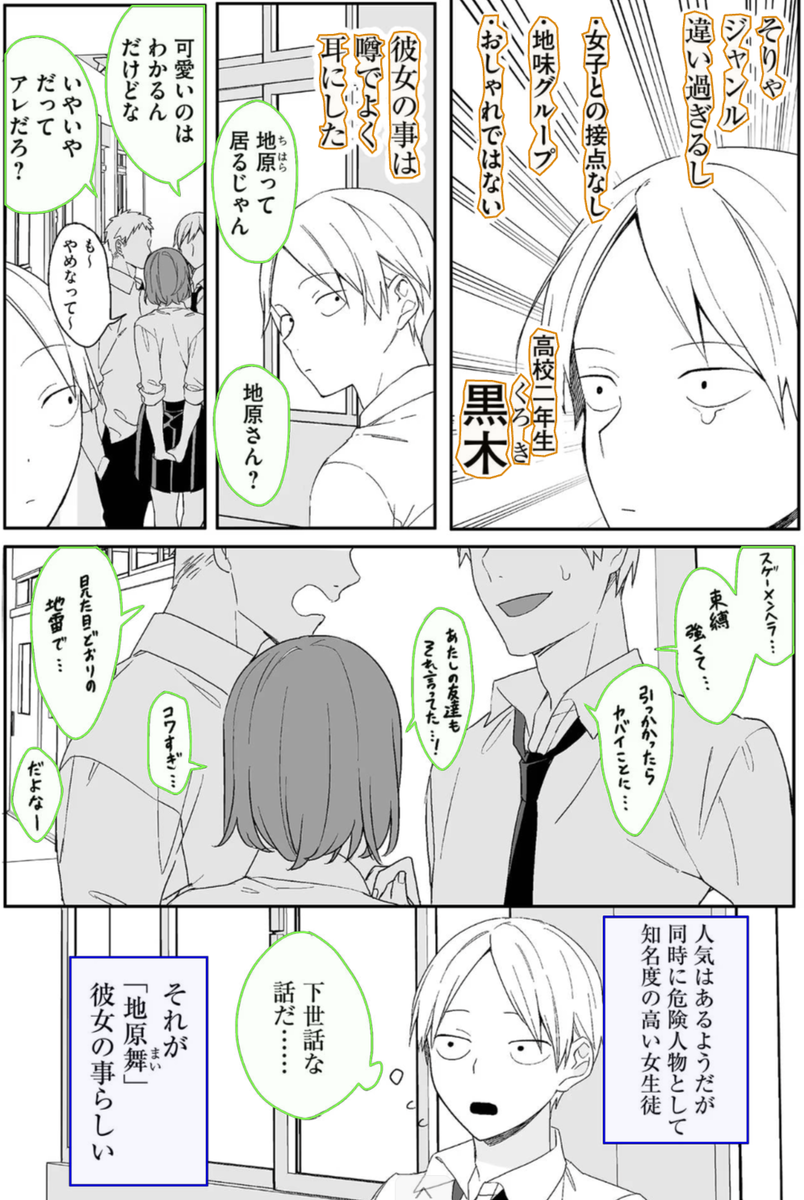
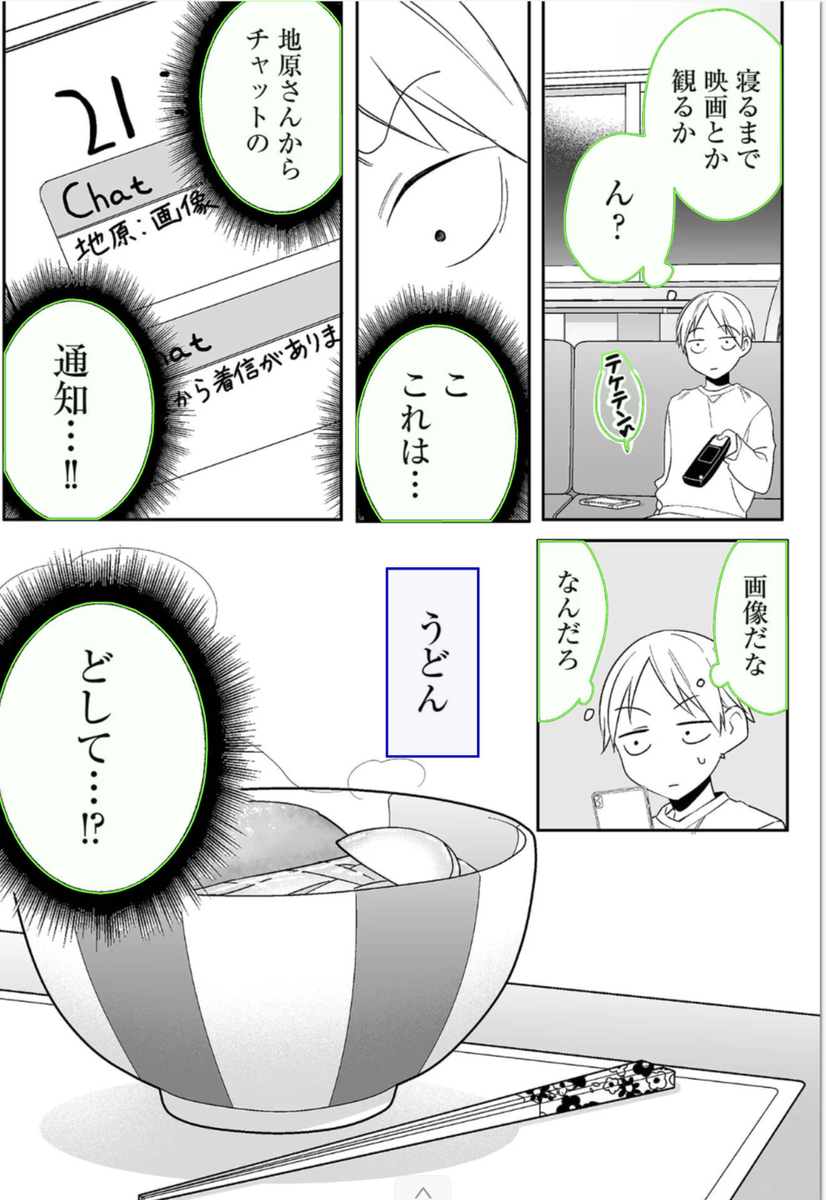
Но вот разметил хотя бы 100. Дальше, после проверки общей работоспособности дальнейшей функциональности проекта (поиск по случайному изображению, вырезка текста, восстановление фона) будет больше, но будет это гораздо позже. А пока решил натренировать 2 сети. Обе на основе YOLO просто с разными параметрами. У YOLOv8 есть несколько релизаций: YOLOv8n, самый быстрый но и самый маленький, далее по нарастающей, YOLOv8s, YOLOv8m, YOLOv8l, YOLOv8x. Более подробнее по различиям тут.
Общий итог обучения в цифрах (Обучал в Google Colab):
YOLOv8s
# 212 epochs completed in 0.265 hours.
# YOLOv8s-seg summary: 261 layers, 11791644 parameters, 11791628 gradients, 42.7 GFLOPs
YOLOv8m
# 300 epochs completed in 0.558 hours.
# YOLOv8m-seg summary: 331 layers, 27241964 parameters, 27241948 gradients, 110.4 GFLOPs
и в графиках + итоги проверки.
Как общий итог, YOLOv8m чуть точнее и чуть меньше потерь по маске текста вне баблов.
Теперь, наконец-то, можно начать реализовывать уже полностью свою нейросеть для восстановления фона.