
Как эффективно управлять ИИ с помощью 4-битной квантизации (с блокнотом Colab в комплекте!) .
Мир больших языковых моделей (LLM) быстро развивается, постоянно появляются такие прорывные модели, как LLAMA2 и Falcon.
27 сентября прошлого года французский стартап Mistral всколыхнул мир технологий, представив свою первую модель - Mistral 7B,
претендующую на звание самой мощной языковой модели для своего размера
на сегодняшний день. Кроме того, Mistral AI представляет собой
многообещающую возможность для Европы проложить свой собственный путь в быстро развивающейся области искусственного интеллекта.
Цель данной статьи
Цель статьи - показать вам, как эффективно загрузить и запустить Mistral 7B
AI в Google Colab, используя всего один GPU. Волшебный ингредиент
успеха? Квантование с 4-битной точностью и QLoRA, о которых будет
рассказано далее.
Здесь вы также можете найти блокнот Google Colab,
https://boosty.to/ai_ml/posts/9e155ba3-9f6e-4897-bd01-6792b61ae845?share=post_link
использованный в нашей статье, чтобы самостоятельно исследовать и экспериментировать с Mistral AI!
Что такое Мистраль 7B
Mistral-7B-v0.1 - это небольшая, но мощная модель
большого языка, адаптируемая ко многим случаям использования. Она может
выполнять различные задачи обработки естественного языка и имеет длину
последовательности 8k. Например, она оптимальна для обобщения текста,
классификации, завершения текста, завершения кода.
Вот краткая информация о Mistral 7B:
Производительность вне сравнения: Mistral 7B превосходит Llama 2 13B по всем показателям.
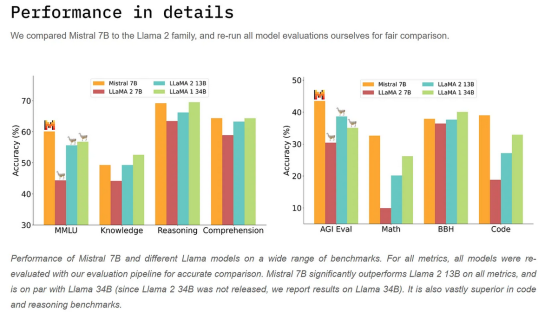
Характеристики Mistral 7B в деталях
Более эффективный: Благодаря функциям внимания по сгруппированным запросам (GQA) и
внимания по скользящим окнам (SWA) Mistral 7B обеспечивает более
быстрый вывод и легко справляется с длинными последовательностями.
Открыт для всех: Выпущенный под лицензией Apache 2.0, Mistral 7B можно использовать без ограничений.Что такое квантование и QLoRA?
Mistral 7B может быть меньше своих аналогов, но запуск и обучение на потребительском оборудовании остается сложной задачей.
Чтобы запустить ее на одном GPU, нам нужно запустить модель с 4-битной
точностью и использовать QLoRA для уменьшения использования памяти.
Решение QLoRA
QLoRA,
что расшифровывается как Quantized LLMs with Low-Rank Adapters, - это
эффективный подход к тонкой настройке. Он использует 4-битное
квантование для сжатия предварительно обученной языковой модели без
ущерба для производительности по сравнению со стандартной 16-битной
финишной настройкой модели.
Аннотация к статье QLoRA:
Мы представляем QLoRA, эффективный подход к тонкой настройке, который
позволяет снизить потребление памяти настолько, чтобы выполнить тонкую
настройку модели с 65 параметрами на одном GPU объемом 48 ГБ, сохраняя
при этом полную 16-битную производительность задачи тонкой настройки.
[...]
В QLoRA реализован ряд инноваций для экономии памяти без снижения
производительности: (а) 4-битный NormalFloat (NF4), новый тип данных,
который теоретически оптимален для нормально распределенных весов (б)
двойное квантование для уменьшения среднего объема памяти за счет
квантования констант квантования и страничные оптимизаторы для
управления скачками памяти. [...]
Наши результаты показывают, что тонкая настройка QLoRA на небольшом
высококачественном наборе данных приводит к самым современным
результатам, даже при использовании моделей меньшего размера, чем в
предыдущем SoTA.
Пошаговое руководство
Давайте начнем! Вы также можете напрямую открыть блокнот Google Colab здесь,
где уже подготовлены все инструкции для изучения!
Шаг 1 - Установите необходимые пакеты
QLoRA использует биты и байты для квантования и интегрирована с библиотеками PEFT и трансформаторов Hugging Face.
Поскольку мы хотим быть уверены, что используем самые последние возможности, мы установим эти библиотеки из исходного кода.
Шаг 2. Определите параметры квантования через BitsandBytesConfig из трансформаторов
Теперь мы настроим параметры QLoRA с помощью BitsandBytesConfig из библиотеки transformers.
Вот краткое объяснение аргументов, которые можно настраивать и использовать:
load_in_4bit=True: указать, что мы хотим преобразовать и загрузить модель в 4-битной точности.
bnb_4bit_use_double_quant=True: использование вложенного квантования для более эффективного использования памяти при выводе и обучении.
bnd_4bit_quant_type="nf4":
4-разрядное интегрирование поставляется с двумя различными типами
квантования FP4 и NF4. Тип NF4 означает Normal Float 4 и представлен в документе QLoRA. По умолчанию используется квантование FP4.
bnb_4bit_compute_dype=torch.bfloat16:
compute dtype используется для изменения dtype, который будет
использоваться во время вычислений. По умолчанию dtype вычислений
установлен в float32, но для ускорения вычислений можно установить bf16.
Шаг 3 - Загрузка Mistral 7B с квантованием
Теперь мы указываем ID модели, а затем загружаем в нее нашу ранее определенную конфигурацию квантования.
Шаг 4 - После загрузки запустите генерацию и попробуйте!
Наконец-то мы готовы ввести Mistral 7B в действие.
Давайте начнем с проверки его возможностей по созданию текста . Вы можете использовать следующий шаблон:
Модель следовала нашим инструкциям и хорошо объяснила концепцию Большой языковой модели!
2. Теперь давайте проверим навыки кодирования Mistral 7B.
Кажется, модель идеально подходит к коду!
3. Попросим модель объяснить простыми словами, что такое большие языковые модели
Подведение итоговКраткий обзор
В итоге мы убедились, что Mistral AI является очень интересной альтернативой таким популярным моделям, как LLaMA и Falcon.
Он бесплатный, компактный и при этом более эффективный. Он позволяет
полностью настроить его под себя и легко поддается тонкой настройке,
обеспечивая превосходную производительность.
В этом руководстве мы рассказали вам о том, как заставить ИИ Mistral
работать на одном GPU, используя подход QLoRA. Если вы хотите пойти
дальше, я настоятельно рекомендую ознакомиться со статьей Huggingface "Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA".
Что дальше?
В ближайшее время будут подготовлены практические руководства по
настройке Mistral AI для ваших конкретных случаев использования, в том
числе:
1) Как точно настроить Mistral 7B с помощью собственных данных:
Погрузитесь в искусство настройки Mistral 7B с помощью ваших уникальных наборов данных.
2) Как выполнить тонкую настройку Mistral 7B, используя только файлы
конфигурации YAML: Мы собираемся упростить процесс тонкой настройки,
продемонстрировав, как использовать в этом процессе конфигурационные
файлы YAML.



















