
На вашем сайте наверняка используется JavaScript. Уверены ли вы, что это не проблема для поисковых систем? Да, современные поисковики умеют работать с JS, но каждый владелец сайта должен убедиться, что его сайт поисковые системы могут эффективно сканировать и индексировать, притом без чрезмерных затрат вычислительных ресурсов.
Рассмотрим наиболее распространенные проблемы с использованием JavaScript для SEO и способы устранения этих проблем.
Могут ли ошибки JavaScript повлиять на SEO?
Если контент выводится средствами JS, то могут быть проблемы с обнаружением, сканированием и индексацией такого контента. В самом плохом случае контент, выводимый средствами javascript, не будет обнаружен вовсе. В хорошем случае – будет обнаружен с большой задержкой.
Современный поисковый робот (например, GoogleBot) – это практически обычный пользовательский браузер, хотя и работающий с некоторыми ограничениями. Например, по высоте сканирования (от 900 до 1000 пикселов – а это в среднем 2,8 экрана). Он не умеет кликать по кнопкам. Не умеет прокручивать. Он фактически никак не взаимодействует со страницей, никакой интерактивности. И если контент выводится только в результате действий пользователя – то робот ничего и не увидит. А зачем тратить время на страницу, где ничего нет?
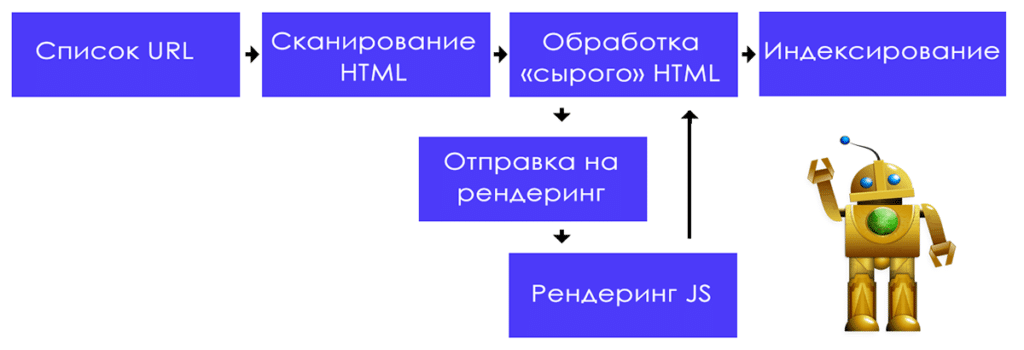
Из-за сложности JavaScript роботы-краулеры могут неправильно интерпретировать определенные элементы кода, что может привести к неправильной индексации контента. В результате любой веб-сайт, который в значительной степени использует JavaScript, может пострадать от снижения рейтинга. Чем сложнее ваш код, тем больше риски для SEO. Но есть способы исправить эти ошибки и, следовательно, улучшить рейтинг вашего сайта.
Распространенные проблемы SEO с JavaScript
Оценим базовые проблемы, которые могут возникнуть у сайта, активно использующего JavaScript для оформления и вывода контента.
Заблокированный доступ
Большинство современных сайтов использует адаптивную вёрстку, одинаково хорошо отображающуюся на любом дисплее – от смартфона до большого телевизора. Притом для поисковых систем сейчас приоритет за смартфонами: большинство людей для выхода в интернет использует только их.
Проблема заключается в том, что если вы не разрешите доступ поисковых роботов к файлам JS и CSS, то поисковая система не поймёт, что ваш сайт адаптирован для смартфонов. Если ваш сайт отображается не так, как ожидалось, поисковики просто сочтут его неоптимизированным – и вы потеряете позиции в выдаче.
Причина – в блокировке ресурсов на уровне файла директив robots.txt. Файлы JavaScript и каскадных таблиц стилей (CSS) должны быть доступны для поисковых роботов. Добавьте в robots разрешающую директиву:
Allow: /*.css*
Allow: /*.js*
После этого проверьте, как Google отображает ваши страницы, с помощью инструмента проверки URL-адресов в Search Console. Протестируйте несколько URL для каждого раздела сайта, использующего отдельный шаблон.
Используйте SEO-сканер, который позволит оценить важность файлов шаблона для отображения страницы. Я использую Screaming Frog SEO Spider. Добавляют ли незагруженные ресурсы на страницу какой-либо существенный контент и нужно ли их обязательно сканировать?
Проверьте файл robots.txt: заблокированы ли какие-либо соответствующие каталоги, в которых хранятся ресурсы, для роботов поисковых систем? – Если да, удалите все директивы, блокирующие критически важные файлы.
Нет гиперссылок
HTML-ссылки (гиперссылки с тегом <a> и атрибутом href) следует использовать для ссылок на индексируемые страницы, чтобы поисковые системы могли:
- Найти, просканировать и внести в свои базы данных ваши страницы
- Понять структуру вашего сайта.
Ссылки, сгенерированные средствами JavaScript, могут помешать поисковым системам сделать это: роботы не умеют нажимать на кнопки и не взаимодействуют со страницами, как люди.
А из этого уже проистекают серьёзные проблемы. Например, если вы используете нумерацию страниц (пагинацию), то отсутствие ссылок на страницы пагинации не позволит роботу их найти и просканировать. Это значит, что ваши товары, или лента статей, или пункты справочника останутся вне индекса. Робот их просто не найдёт и не учтёт. А это повлияет и на ранжирование по частотным запросам: поисковые системы ценят полноту соответствия, большой ассортимент. Пустая категория с парой десятков товаров не может конкурировать с сайтами, где категория содержит тысячи таких товаров.
Сейчас многие сайты используют подгрузку контента по типу «бесконечной ленты». Вы прокручиваете страницу – подгружаются новые элементы. Это удобно, это эффектно. Но поисковые роботы не умеют прокручивать, а значит, вы должны предоставить им ссылки на подгружаемые фрагменты.
Даже если вы реализуете эти ссылки с помощью JS, индексирование будет проходить с большой задержкой и может негативно повлиять на ранжирование. Даже если вы используете JS для навигации – не отказывайтесь от обычный HTML-ссылок для критически важного контента.
URL-адреса, содержащие хэши (#)
Идентификаторы фрагментов, также известные как привязки или хеш-фрагменты, используются для перехода к определенному разделу веб-страницы. Их ещё называют «якорными ссылками». Это достаточно удобный способ навигации в рамках одной страницы. Вы присваиваете какому-то элементу идентификатор и можете сослаться на него обычной ссылкой откуда угодно.
Якорные хэш-ссылки позволяют администраторам веб-сайтов напрямую ссылаться на определенную часть страницы. JavaScript и веб-разработчики могут использовать фрагменты для создания одностраничных приложений (SPA), в которых контент динамически изменяется без полной перезагрузки страницы на основе идентификатора фрагмента в URL-адресе.
Но есть проблема: URL-адреса, содержащие символ решетки, не будут сканироваться роботом как отдельные страницы и не могут быть корректно проиндексированы, если только контент уже не присутствует в исходном коде.
Чтобы ваш контент был правильно найден и проиндексирован в любой системе, надо использовать альтернативные методы направления поисковых систем на нужную страницу. Например, можно создание новых уникальных статических URL-адресов без символа решетки или использование другого разделителя, например вопросительный знак (?), часто используемый для параметров.
Редиректы, реализованные средствами JavaScript
Перенаправления JavaScript могут обеспечить удобное решение в определенных ситуациях, но на больших объёмах они могут здорово испортить техническое состояние сайта, а с ним – и ранжирование.
Если вам нужно перенаправить поискового робота или человека – используйте серверные редиректы 301 («перемещено окончательно») или 302 («временно перенесено»). Поисковые системы тратят на обработку JS много вычислительных ресурсов. И если структура вашего сайта технически зависит от обработки JS, это может стать причиной множества проблем.
В своей документации Google отмечает, что перенаправления средствами JS следует использовать только в крайнем случае.
Кроме того, может быть сложно узнать, действительно ли выполняется желаемое перенаправление: нет никакой гарантии, что каждый раз поисковый робот будет выполнять JS, который инициирует изменение URL-адреса.
Например, если перенаправления JS на стороне клиента являются решением по умолчанию для миграции веб-сайта с большим количеством изменений URL-адресов, это будет менее эффективно. В этом случае роботу потребуется больше времени для обработки всех перенаправлений.
Страницы, для которых в исходном HTML установлено значение noindex, не подвергаются рендерингу, поэтому робот-краулер не увидит их, если они будут перенаправлены с помощью JS.
Прокрутка страницы для подгрузки контента
Как уже упоминалось в отношении проблем с нумерацией страниц, робот не может нажимать кнопки, как это делает человек. Поисковый робот не может прокручивать страницу так, как это делают люди. Любой контент, требующий таких действий для загрузки, не будет индексироваться.
Например, на страницах с бесконечной нумерацией страниц Google не сможет видеть ссылки на последующие продукты (кроме первоначального рендеринга), поскольку он не запускает событие прокрутки.
Однако гуглобот может отображать страницы с высокой областью просмотра (около 9-10 тыс. пикселей), поэтому, если дополнительный контент загружается в зависимости от высоты области просмотра, Google может увидеть «некоторые» из этого контента.
Но вам нужно помнить о границе в 10 000 пикселей — контент, загруженный ниже этого значения, скорее всего, не будет проиндексирован. Более того, нет никакой гарантии, что Google будет использовать широкую область просмотра в нужном масштабе — не все страницы могут отображаться с ее помощью. А значит, не весь их контент будет проиндексирован.
Если вы реализуете отложенную («ленивую») загрузку, например, последующих продуктов в категории электронной торговли, убедитесь, что отложенная загрузка элементов откладывается только с точки зрения визуального рендеринга (их изображения не загружаются заранее, а загружаются отложенно), но их ссылки и сведения присутствуют в исходном HTML без необходимости выполнения JS.
Для правильной индексации вашего веб-сайта весь контент должен загружаться без необходимости прокрутки или нажатия. Это позволяет корректно просматривать весь веб-сайт как посетителям, так и сканерам.
Используйте инструмент проверки в консоли поиска Google, чтобы убедиться, что визуализированный HTML содержит весь контент, который вы хотите проиндексировать.
Робот не видит ссылки в JS-меню
В настоящее время Google ранжирует веб-сайты на основе их мобильных версий, которые менее оптимизированы, чем их настольные версии. В результате индексации с приоритетом мобильных устройств необходимо убедиться, что Google видит ссылки в меню вашего мобильного устройства.
Адаптивная вёрстка — общий ответ на этот вопрос.
Лучше всего, если вы используете один набор ссылок меню, а затем стилизуете его соответствующим образом, чтобы он работал для всех разрешений экрана. Не надо создавать отдельные экземпляры меню для нескольких разрешений.
Это также может привести к избыточности ссылок, если все варианты меню включены в код одновременно (вы удвоите количество ссылок из навигации). Если вы создаете отдельные меню для десктопа и мобильного устройства, где в коде появляется только одно в зависимости от разрешения экрана, вам нужно помнить, что индексироваться будет только то, что видно на мобильном устройстве (Mobile-First Indexing).
Ссылки, присутствующие только в меню вёрстки для десктопов, учитываться не будут.
Если ваше меню генерируется скриптами — поисковые системы, скорее всего, не будут его сканировать или, по крайней мере, не каждый раз. Учитывая такую важную часть навигации, ситуация не идеальна. Если вы не можете использовать такие решения, как SSR (серверный рендеринг), не забудьте сохранить критические ссылки в неотрисованном исходном HTML.
Контент, спрятанный под вкладками
Когда дело доходит до контента JavaScript, динамически загружаемого во вкладках, сканеры не могут щелкнуть по ним, поскольку они не взаимодействуют с веб-сайтами так же, как люди. Это может помешать роботу получить доступ к содержимому, представленному на вкладках, и привести к неправильной индексации вашего веб-сайта.
Лучше избегать сокрытия контента за вкладками или кнопками типа «нажмите здесь, чтобы увидеть больше», а вместо этого использовать комбинацию CSS и HTML, чтобы на время «скрыть» контент, который уже присутствует в коде, от визуального рендеринга, за исключением случаев, когда нажата вкладка.
Даже в этом случае поисковые системы могут счесть, что уже загруженный, но скрытый от глаз контент должен иметь невысокий приоритет. Но в этом случае они его хотя бы видят и учитывают.
Чтобы убедиться, что Google может проиндексировать ваш контент на вкладках, скопируйте фрагмент текста, скрытый под вкладкой, и найдите его с помощью оператора site: с URL-адресом веб-страницы. Для текстовых фрагментов стоит использовать заключение фрагмента в кавычки: в этом случае поисковик будет искать цитату целиком.
Если вы видите свой контент в реальном поиске Google, вы можете быть уверены, что он проиндексирован.
Динамический рендеринг
Если вы воспользуетесь подходом обслуживания посетителей с помощью полнофункционального JS-сайта, в то время как сервер отправляет предварительно обработанную версию поисковому роботу, это называется динамический рендеринг.
И это может привести к ряду проблем.
- Фактически, это создает два экземпляра веб-сайта, которыми вам нужно управлять и обслуживать (каждая страница имеет предварительно обработанную версию, передаваемую роботу на основе распознавания пользовательского агента), что требует больше ресурсов.
- Вам необходимо убедиться, что версия, предоставленная Google, соответствует тому, что видят реальные пользователи. Серьезные различия в контенте могут привести к индексации устаревшего контента или, что еще хуже, к наказанию вашего сайта за вводящие в заблуждение действия.
С 2023 года Google не рекомендует динамический рендеринг как действенное долгосрочное решение. Если ваш сайт всё ещё его использует – надо искать альтернативные варианты.
Как определить, использует ли ваш сайт динамический рендеринг? Откройте свой сайт, как обычно, но заблокируйте JavaScript. Отсутствуют ли какие-либо важные элементы страницы? Или, может быть, вы получаете пустую страницу? Затем сделайте то же самое, но переключите пользовательский агент на GoogleBot – с отключенным JS страница будет выглядеть так же? Или, возможно, он выглядит почти готовым (по сравнению с пустой страницей, которую видели раньше)? – Если да, то ваш сайт использует динамический рендеринг.
Существуют крайние случаи: если помимо обнаружения пользовательского агента вы также проверяете, поступает ли запрос с реальных серверов Google, это ничего не докажет.
Динамический рендеринг может быть слишком затратным для структуры сервера / инфраструктуры, вызывая проблемы с доступностью предварительно обработанного HTML и временем его ответа. Если версия, отображаемая на стороне сервера, генерируется специально, это означает, что любые серверные вычисления выполняются «налету», только по входящему запросу от поискового робота.
В зависимости от размера ресурсов и полезной нагрузки JS это может занять некоторое время. Поисковые роботы умеют ждать, но не будут ждать вечно – как и тратить впредь свои ресурсы на плохо оптимизированный в техническом отношении сайт.
Если какой-либо из фрагментов JS не выполняется во время этого расчета, возможно, у вас отсутствуют части страницы, поэтому недостающий контент не будет проиндексирован. Если значительная часть контента отсутствует в предварительном рендеринге, это приводит к проблемам с отсутствующим контентом на URL-адресах, которые должны быть проиндексированы и учтены, и это отрицательно влияет на качество всего сайта.
Рекомендуемое долгосрочное решение — предоставлять одну и ту же версию страниц, отображаемую на стороне сервера, как сканерам, так и пользователям. Другими словами, надо отказаться от распознавания поисковых роботов и предоставление им особого контента. Уравняйте людей и поисковых роботов, и предоставляйте обработанный контент всем.
Софт 404 попадают в индекс
Страницы софт-404 – это страницы-призраки: они отдают код 200 (доступно), на них может быть какой-то контент, они напоминают существующие – но на самом деле это страницы ошибок, не соответствующие запросу. Они могут попадать в индекс, отнимая ресурсы поисковой системы и засоряя базы данных. В некоторых случаях это связано с изменением содержимого сайта JavaScript.
Обилие ошибок софт-404 влияет на оценку вашего сайта поисковых системах, поэтому важно убедиться, что отсутствующие страницы отдают код 404, а окончательно удаленные – 410. Если вы используете динамический рендеринг – это может быть проблемой.
Чтобы обнаружить это, вы можете просканировать свой веб-сайт с помощью программного обеспечения по вашему выбору и выполнить поиск страниц, которые возвращают 200 кодов состояния HTTP, но не несут какой-либо уникальной ценности. Например, иметь одинаковый повторяющийся заголовок, сообщающий, что страница не существует. Если вы подозреваете, что проблема связана с JavaScript, не забудьте запустить сканирование с рендерингом JS, а не обычное.
Кроме парсинга, нужно использовать данные панелей для вебмастеров. Google Search Console помогает определить URL-адреса, которые возвращают 200 кодов состояния HTTP вместо ошибок 404. Яндекс-Вебмастер такие данные, к сожалению, не предоставляет.
Для устранения ошибок такого рода вам может понадобиться помощь программиста и вебмастера.
Неоптимизированные JS, формирующие шаблон
Обработка JS кратно увеличивает затраты системных ресурсов для поисковых систем. Однако огромные неоптимизированные JS влияют и на быстродействие вашего сайта. А это, прямо или косвенно, влияет и на ранжирование.
Оцените, всё ли, что содержится в файлах шаблона сайта, так уж нужно? Огромными раздутыми ресурсными файлами страдают готовые коммерческие шаблоны Wordpress, Битрикс, Tilda. Но если вы используете кастомный шаблон, собранный специально для вас – это не значит, что он не содержит мусора.
Для решения этой задачки годится старая, но не устаревшая практика оптимизации быстродействия:
- Уменьшайте неиспользуемые JS/CSS.
- Минимизируйте и сжимайте файлы JS/CSS.
- Убедитесь, что JS/CSS не блокирует рендеринг.
Если JS не нужен для первоначальной визуализации страницы (например, JS, который обрабатывает взаимодействия с пользователем) – отложите его загрузку.
Заключение
Трудно найти современные сайты, не использующие JS. И очевидно, что JS может оказать существенное влияние на поисковую оптимизацию, затрудняя процессы сканирования, индексирования, быстродействия.
Чтобы свести к минимуму вероятность появления проблем такого рода, надо сделать полноценный SEO-аудит вашего сайта и устранить любую из вышеупомянутых проблем с JavaScript.