
Мы можем ожидать его выхода в ноябре, возможно, в 2-ю годовщину запуска легендарного Chat GPT.
В аналогичные сроки мы также получим Gemini 2 Ultra, LLaMA-3, Claude-3, Mistral-2 и многие другие новаторские модели.
(Gemini от Google, похоже, уже составляет жесткую конкуренцию GPT-4 turbo)
Практически очевидно, что GPT-5 будет выпущен поэтапно, при этом промежуточные контрольные точки будут устанавливаться во время обучения модели.
Само обучение может занять 3 месяца, а еще 6 месяцев - тестирование безопасности.
Чтобы дать представление о GPT-5, давайте сначала взглянем на характеристики GPT-4:
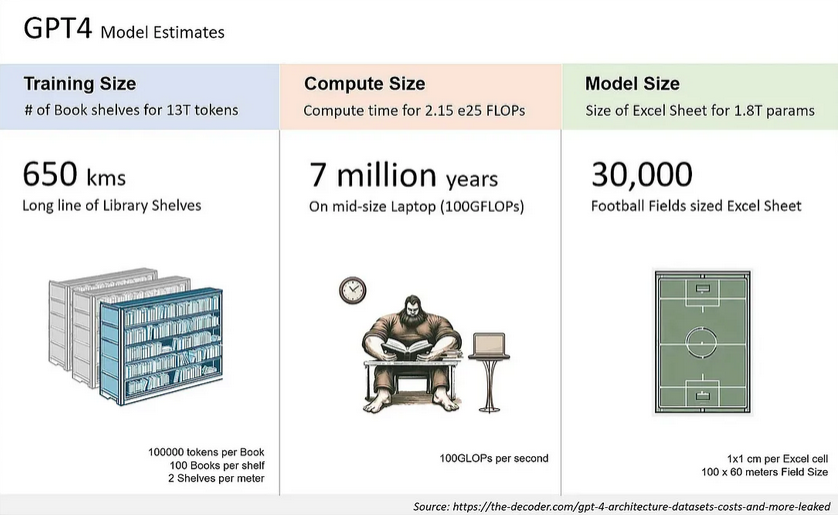
Оценки модели GPT-4
Масштаб: GPT-4 имеет ~1,8 триллиона параметров в 120 слоях, что в 10 раз больше, чем у GPT-3.
Смесь экспертов (MoE): OpenAI использует 16 экспертов в своей модели, каждый с ~111 млрд параметров для MLP (многослойный перцептрон).
Набор данных: GPT-4 обучается на ~13Т токенах, включая как текстовые, так и кодовые данные, с некоторыми данными для точной настройки от ScaleAI и внутренними источниками.
Состав набора данных: Обучающие данные включали CommonCrawl и RefinedWeb, в общей сложности 13 триллионов токенов. Есть предположения о дополнительных источниках, таких как Twitter, Reddit, YouTube и большая коллекция учебников.
Стоимость обучения: Стоимость обучения GPT-4 составила около 63 миллионов долларов с учетом необходимой вычислительной мощности и времени обучения.
Стоимость вывода: GPT-4 стоит в 3 раза дороже,
чем 175-миллиардная параметрическая модель Davinci из-за требуемых
более крупных кластеров и более низких коэффициентов использования.
Архитектура вывода:
Вывод выполняется на кластере из 128 графических процессоров с
использованием 8-стороннего тензорного параллелизма и 16-стороннего
конвейерного параллелизма.
Зрение (мультимодальность): GPT-4 включает в себя кодировщик зрения, позволяющий автономным агентам читать веб-страницы, транскрибировать изображения и видео. Это добавляет дополнительные параметры и происходит дополнительная донастройка на ~2 триллионах токенов.
Теперь, GPT-5 может иметь в 10 раз больше параметров, чем GPT-4, и это ОГРОМНО! Это означает увеличение размеров встраивания, больше слоев и вдвое больше экспертов.
Более широкое
встраивание подразумевает большую детализацию, а удвоение количества
слоев позволяет модели развивать более глубокое распознавание образов.GPT-5 будет намного лучше
в рассуждениях, он будет излагать свои шаги рассуждения перед решением
задачи и проверять каждый из этих шагов рассуждения внутренне или
внешне.Подход проверки шагов
рассуждения и выборки до 10 000 раз приведет к значительно лучшим
результатам в генерации кода и математических вычислениях.
Сравнение моделей вознаграждения с учетом результатов и процессным контролем, оцененных по их способности искать среди множества тестовых решений.
Многократная выборка из модели тысячи раз и принятие ответа, имевшего наиболее высоко оцененные этапы рассуждения, удвоило производительность в математике. Причем это сработало не только для математики, но и привело к впечатляющим результатам во всех областях STEM (естественные науки, технологии, инженерия и математика).
GPT-5 также будет обучен на гораздо большем количестве данных, как с точки зрения объема, так и качества и разнообразия.
Это включает в себя огромное количество текстовых, графических, аудио- и видеоданных, а также мультиязычные данные и данные для рассуждений.
Это означает, что мультимодальность значительно улучшится в этом году, параллельно со стремительным развитием рассуждений в LLM (больших языковых моделях).
Это сделает GPT-5 более активной, как при использовании LLM в качестве операционной системы.
Хотя ничего по-настоящему безумного/революционного не произойдет с LLM, выпущенными в 2024 году, например, изобретения LLM новой науки или лекарств от болезней, создания сфер Дайсона или биологического оружия...
...2024 год принесет нам более четкие и коммерчески применимые версии существующих сегодня моделей, и люди будут удивлены, насколько хорошими стали эти модели.
Никто по-настоящему не знает, какими будут новые модели.
Самая главная особенность истории ИИ заключается в том, что она полна сюрпризов.
Каждый раз, когда вы думаете, что что-то знаете, вы масштабируете это в 10 раз, и оказывается, что вы ничего не знали. Мы, как человечество, как вид, действительно исследуем это вместе.
Тем не менее, весь коллективный прогресс в LLM и ИИ - это шаг вперед к AGI (общему искусственному интеллекту)
Источники: