Эта статья познакомит вас с миром функций ранжирования в SQL. Мы рассмотрим основы их работы, как их использовать и как избежать распространенных ошибок.

В современном мире, основанном на данных, SQL является краеугольным камнем управления системами баз данных и манипулирования ими. Основной компонент мощи и гибкости SQL заключается в его оконных функциях, категории функций, которые выполняют вычисления для наборов строк, связанных с текущей строкой.
Представьте, что вы смотрите на свои данные через скользящее окно и в зависимости от положения и размера этого окна выполняются вычисления или преобразования над данными. По сути, это то, что делают оконные функции SQL. Они обрабатывают такие задачи, как вычисление текущих итогов, средних значений или рейтингов, которые сложно выполнить с помощью стандартных команд SQL.
Одним из самых надежных инструментов является функция ранжирования, в частности функция DENSE_RANK(). Эта функция — находка для аналитиков данных, позволяющая нам ранжировать различные строки данных без каких-либо пробелов. Независимо от того, изучаете ли вы данные о продажах, посещении веб-сайта или даже простой список результатов тестов студентов, функция DENSE_RANK() незаменима.
В этой статье мы углубимся во внутреннюю работу DENSE_RANK(), сопоставим ее с ее близкими братьями и сестрами RANK() и ROW_NUMBER(), а также продемонстрируем, как избежать распространенных ошибок, которые могут сбить вас с толку на пути к знаниям по SQL. Готовы повысить уровень своих навыков анализа данных? Давайте углубимся.
Понимание роли функций ранжирования в SQL
Функции ранжирования в SQL представляют собой подмножество оконных функций, которые присваивают уникальный ранг каждой строке в результирующем наборе. Эти значения ранга соответствуют определенному порядку, который определяется оператором ORDER BY в функции. Функции ранжирования являются основой SQL, широко используемой при анализе данных для различных задач, таких как поиск лучшего продавца, определение веб-страницы с наилучшими результатами или определение самого кассового фильма за конкретный год.
В SQL есть три основные функции ранжирования, а именно RANK(), ROW_NUMBER() и DENSE_RANK(). Каждая из этих функций работает немного по-разному, но все они служат общей цели ранжирования данных на основе заданных условий. Функции RANK() и DENSE_RANK() имеют схожее поведение в том смысле, что они присваивают одинаковый ранг строкам с одинаковыми значениями. Решающее различие заключается в том, как они обрабатывают следующий ранг. RANK() пропускает следующий ранг, тогда как DENSE_RANK() этого не делает.
С другой стороны, функция ROW_NUMBER() присваивает уникальный номер каждой строке. Хотя RANK(), DENSE_RANK() и ROW_NUMBER() на первый взгляд могут показаться взаимозаменяемыми, понимание их нюансов имеет решающее значение для эффективного анализа данных в SQL. Выбор между этими функциями может существенно повлиять на ваши результаты и понимание, полученное на основе ваших данных.
Что такое DENSE_RANK() в SQL?
DENSE_RANK() это мощная функция ранжирования в SQL, которая присваивает уникальное значение ранга в пределах указанного раздела. DENSE_RANK() ранжирует ваши данные без пробелов, что означает, что каждому уникальному значению присваивается отдельный ранг, а идентичные значения получают одинаковый ранг. В отличие от своего аналога RANK(), DENSE_RANK() не пропускает никаких рангов, если между значениями есть связь.
Чтобы разобраться в этом, давайте представим сценарий, в котором у вас есть набор данных с оценками учащихся, и три студента набрали одинаковый балл, скажем, 85 баллов. При использовании RANK() все три ученика получат оценку 1, но следующий лучший результат будет 4, пропуская оценки 2 и 3. Однако DENSE_RANK() обрабатывает это по-разному. Всем трем студентам будет присвоен ранг 1, а следующий лучший результат получит ранг 2, что гарантирует отсутствие разрыва в рейтинге.
Итак, когда следует использовать DENSE_RANK()? Это особенно удобно в сценариях, где требуется непрерывное ранжирование без каких-либо пробелов. Рассмотрим вариант использования, когда вам нужно наградить трех лучших исполнителей. Если у вас есть привязки к вашим данным, использование RANK() может привести к тому, что вы упустите возможность назначить достойного кандидата. Вот тогда DENSE_RANK() приходит на помощь, гарантируя, что все лучшие кандидаты получат должное признание, а ранги не будут пропущены.
DENSE_RANK() vs RANK() vs ROW_NUMBER() в SQL
Понимание различий между DENSE_RANK(), RANK() и ROW_NUMBER() важно для эффективного анализа данных в SQL. Все три функции по-своему эффективны, но их тонкие различия могут существенно повлиять на результат вашего анализа данных.
Давайте начнем с RANK(). Эта функция присваивает уникальный ранг каждому отдельному значению в наборе данных, причем одинаковый ранг присваивается идентичным значениям. Однако, когда RANK() обнаруживается связь (идентичные значения), следующий ранг (и) в последовательности пропускается.
Например, если у вас есть три продукта с одинаковыми показателями продаж, RANK() присвоит каждому из этих продуктов одинаковый рейтинг, но затем пропустит следующий рейтинг. Это означает, что если эти три продукта являются самыми продаваемыми, им всем будет присвоен ранг 1, но следующему самому продаваемому продукту будет присвоен ранг 4, а не 2.
Далее давайте рассмотрим DENSE_RANK(). Аналогично RANK(), DENSE_RANK() присваивает одинаковый ранг идентичным значениям, но не пропускает ни одного ранга. Используя предыдущий пример с DENSE_RANK(), трем наиболее продаваемым продуктам по-прежнему будет присвоен ранг 1, но следующему наиболее продаваемому продукту будет присвоен ранг 2, а не 4.
Наконец, ROW_NUMBER() использует другой подход. Он присваивает уникальный ранг каждой строке, независимо от того, идентичны ли значения. Это означает, что даже если три продукта имеют одинаковые показатели продаж, ROW_NUMBER() каждому из них будет присвоен уникальный номер, что делает его идеальным для ситуаций, когда вам нужно назначить отдельный идентификатор каждой строке.
Расшифровка синтаксиса и использование DENSE_RANK() в SQL
Синтаксис DENSE_RANK() прост. Он используется в сочетании с оператором OVER(), разделяющим данные перед присвоением рангов. Синтаксис следующий:
DENSE_RANK() OVER (ORDER BY column).
Здесь, column относится к столбцу, по которому вы хотите ранжировать свои данные. Давайте рассмотрим пример, где у нас есть таблица с именем Sales со столбцами SalesPerson и SalesFigures. Чтобы ранжировать продавцов по их показателям продаж, мы бы использовали функцию DENSE_RANK() следующим образом:
DENSE_RANK() OVER (ORDER BY SalesFigures DESC).
Этот SQL-запрос ранжирует продавцов от самого высокого к самому низкому на основе их показателей продаж.
Использование DENSE_RANK() в сочетании с PARTITION BY может быть особенно полезным. Например, если вы хотите ранжировать продавцов в каждом регионе, вы можете разделить свои данные на Region и затем ранжировать в каждом разделе. Синтаксис для этого будет таким:
DENSE_RANK() OVER (PARTITION BY Region ORDER BY SalesFigures DESC).
Таким образом, вы получаете не только исчерпывающий рейтинг, но и детальное представление о производительности в каждом регионе.
Практические примеры работы функции SQL DENSE_RANK()
Вопрос Apple по SQL: найдите лучших продавцов на каждую дату продаж
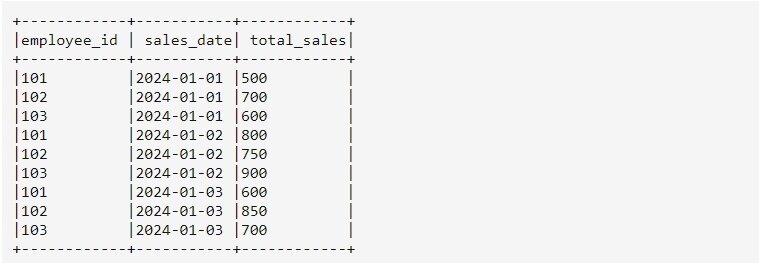
Таблица: sales_data
Вывод
Решение Apple
Шаг 1: Разберитесь с данными
Сначала давайте разберемся с данными в таблице sales_data. Она состоит из трех столбцов: employee_id, sales_date и total_sales . В этой таблице представлены данные о продажах с информацией о сотруднике, дате продажи и общей сумме продаж.
Шаг 2: Проанализируйте функцию DENSE_RANK()
Запрос использует оконную функцию DENSE_RANK() для ранжирования сотрудников на основе их общего объема продаж в каждом разделе даты продаж. DENSE_RANK() используется для присвоения ранга каждой строке в разделе sales_date с упорядочением на основе total_sales в порядке убывания.
Шаг 3: Расшифровка структуры запроса
Теперь давайте разберем структуру запроса:
SELECT
employee_id,
sales_date,
total_sales
FROM
(
SELECT
employee_id,
sales_date,
total_sales,
DENSE_RANK() OVER (
PARTITION BY sales_date
ORDER BY
total_sales DESC
) AS sales_rank
FROM
sales_data
) ranked_sales
WHERE
sales_rank = 1;
- Оператор SELECT: определяет столбцы, которые будут включены в конечный результат. В данном случае это employee_id, sales_date и total_sales.
- Оператор FROM: отсюда берутся фактические данные. Оно включает подзапрос (заключенный в круглые скобки), который выбирает столбцы из таблицы sales_data и добавляет вычисляемый столбец с помощью DENSE_RANK() .
- Функция DENSE_RANK(): эта функция используется в рамках подзапроса для присвоения ранга каждой строке на основе столбца total_sales , и она разделяется по sales_date. Это означает, что ранжирование выполняется отдельно для каждой даты продажи.
- Оператор WHERE: оно фильтрует результаты, чтобы включить только строки, в которых sales_rank равен 1. Это гарантирует, что в конечный результат будут включены только лучшие показатели продаж на каждую дату продаж.
Шаг 4: Выполните запрос
При выполнении этого запроса будет выдан результирующий набор, включающий employee_id, sales_date и total_sales для топ-менеджера по продажам на каждую дату продаж.
Шаг 5: Просмотрите выходные данные
Итоговая таблица с именем top_performers будет содержать желаемую информацию: топ-показатели продаж на каждую дату продаж на основе расчета DENSE_RANK()
Вопрос по SQL от Google: найдите для каждого продукта клиента, который набрал наибольшее количество баллов за отзыв
Таблица: product_reviews
Вывод
Решение
Шаг 1: Разберитесь с данными
Таблица product_reviews содержит информацию об отзывах клиентов о различных продуктах. Она включает такие столбцы, как customer_id, product_id, review_date, review_score и helpful_votes. В этой таблице представлены данные, относящиеся к отзывам клиентов, с подробной информацией о клиенте, рецензируемом продукте, дате отзыва, оценке отзыва и количестве полученных полезных голосов.
Шаг 2: Проанализируйте функцию DENSE_RANK()
В этом запросе оконная функция DENSE_RANK() используется для ранжирования строк в каждом разделе, определяемом product_id и review_date . Рейтинг определяется на основе двух критериев: review_score в порядке убывания и helpful_votes в порядке убывания. Это означает, что строкам с более высокими оценками отзывов и большим количеством полезных голосов будут присвоены более низкие ранги.
Шаг 3: Расшифровка структуры запроса
Теперь давайте разберем структуру запроса:
SELECT
customer_id,
product_id,
review_date,
review_score,
helpful_votes
FROM
(
SELECT
customer_id,
product_id,
review_date,
review_score,
helpful_votes,
DENSE_RANK() OVER (
PARTITION BY product_id,
review_date
ORDER BY
review_score DESC,
helpful_votes DESC
) AS rank_within_product
FROM
product_reviews
) ranked_reviews
WHERE
rank_within_product = 1;
- Оператор SELECT: указывает столбцы, которые будут включены в конечный результат. Оно включает customer_id, product_id, review_date, review_score и helpful_votes.
- Оператор FROM: эта часть включает подзапрос (заключен в круглые скобки), который выбирает столбцы из таблицы product_reviews и добавляет вычисляемый столбец с помощью DENSE_RANK(). Вычисление выполняется для раздела, определенного product_id и review_date, а ранжирование основано как на review_score, так и на helpful_votes в порядке убывания.
- Функция DENSE_RANK(): эта функция применяется в рамках подзапроса для присвоения ранга каждой строке на основе заданных критериев. Ранжирование выполняется отдельно для каждой комбинации product_id и review_date.
- Оператор WHERE: фильтрует результаты, чтобы включать только те строки, в которых rank_within_product равен 1. Это гарантирует, что в конечный результат будет включена только строка с самым высоким рейтингом для каждого продукта на каждую дату проверки.
Шаг 4: Выполните запрос
Выполнение этого запроса приведет к получению результирующего набора, содержащего желаемую информацию: customer_id, product_id, review_date, review_score и helpful_votes для обзора с наивысшим рейтингом на основе как оценки отзыва, так и голосов за полезность в каждой комбинации продукта и даты отзыва.
Шаг 5: Просмотрите выходные данные
В итоговой таблице с именем top_reviewers будут отображаться обзоры с самым высоким рейтингом для каждого продукта на каждую дату обзора с учетом как оценки обзора, так и количества полезных голосов.
Как избежать распространенных ошибок с DENSE_RANK() в SQL
Хотя DENSE_RANK() это очень полезная функция в SQL, аналитики, особенно новички в SQL, нередко допускают ошибки при ее использовании. Давайте подробнее рассмотрим некоторые из этих распространенных ошибок и способы их предотвращения.
Одной из распространенных ошибок является неправильное понимание того, как DENSE_RANK() обрабатывает значения NULL. В отличие от некоторых функций SQL, DENSE_RANK() обрабатывает все значения NULL как идентичные. Это означает, что если вы ранжируете данные, где некоторые значения равны NULL, DENSE_RANK() присвоит одинаковый ранг всем нулевым значениям. Помните об этом при работе с наборами данных, которые содержат значения NULL, и рассмотрите возможность замены NULL другим значением.
Еще одна частая ошибка заключается в игнорировании важности секционирования при использовании DENSE_RANK(). Оператор PARTITION BY позволяет вам разделить ваши данные на отдельные сегменты и выполнить ранжирование внутри этих разделов. Пренебрежение использованием PARTITION BY может привести к ошибочным результатам, особенно если вы хотите перезапустить ранжирование для разных категорий или групп.
С этим связано неправильное использование оператора ORDER BY с DENSE_RANK(). DENSE_RANK() по умолчанию присваивает ранги в порядке возрастания, то есть наименьшему значению присваивается ранг 1. Если вам нужно, чтобы рейтинг был в порядке убывания, вы должны включить ключевое слово `DESC` в оператор ORDER BY. Невыполнение этого требования приведет к ранжированию, которое может не соответствовать вашим ожиданиям.
Наконец, некоторые аналитики ошибочно используют, DENSE_RANK() где ROW_NUMBER() или RANK() может быть более подходящим, и наоборот. Как мы уже обсуждали, все три эти функции имеют уникальное поведение. Понимание этих нюансов и правильный выбор функции для вашего конкретного варианта использования имеют решающее значение для проведения точного и эффективного анализа данных.
Как освоение функции DENSE_RANK() повышает эффективность анализа данных в SQL
Освоение использования DENSE_RANK() может значительно повысить эффективность анализа данных в SQL, особенно там, где задействованы ранжирование и сравнения. Эта функция предлагает тонкий подход к ранжированию, который поддерживает непрерывность в шкале ранжирования, присваивая одинаковый ранг идентичным значениям без пропуска каких-либо номеров рангов.
Это особенно полезно при анализе больших наборов данных, где точки данных часто могут иметь одинаковые значения. Например, в наборе данных о продажах несколько продавцов могли достичь одинаковых показателей продаж.
DENSE_RANK() обеспечивает справедливое ранжирование, при котором каждому из этих продавцов присваивается одинаковый ранг. Кроме того, использование DENSE_RANK() в сочетании с PARTITION BY позволяет проводить целенаправленный анализ для конкретной категории.
Применение этой функции становится еще более эффективным при работе со значениями NULL. Вместо исключения их из процесса ранжирования, DENSE_RANK() обрабатывает все NULL как идентичные и присваивает им одинаковый рейтинг. Это гарантирует, что, даже если точные значения могут отсутствовать, точки данных не игнорируются, тем самым обеспечивая более комплексный анализ.
Вопросы и ответы
Какую задачу решает DENSE_RANK() в SQL?
DENSE_RANK() — это оконная функция SQL, которая присваивает ранги строкам данных на основе указанного столбца. Она обрабатывает связи, присваивая им одинаковый ранг, не оставляя пробелов в последовательности ранжирования.
В чем разница между RANK(), ROW_NUMBER() и DENSE_RANK() в SQL?
RANK() и ROW_NUMBER() присваивают данным ранги, но они по-разному обрабатывают связи. Функция RANK() оставляет пробелы в ранжировании связанных данных, в то время как функция ROW_NUMBER() присваивает каждой строке уникальный номер без учета связей. С другой стороны, DENSE_RANK() присваивает идентичные ранги связанным точкам данных без каких-либо пробелов.
Как использовать DENSE_RANK() с оператором WHERE в SQL?
DENSE_RANK() — это оконная функция, и ее нельзя использовать напрямую с оператором WHERE. Вместо этого его можно использовать в сочетании с другими функциями, такими как ROW_NUMBER() или RANK() , которые затем можно использовать с оператором WHERE для фильтрации данных на основе ранга.
Можно ли использовать DENSE_RANK() без PARTITION BY?
Нет, указание PARTITION BY имеет решающее значение для правильного функционирования DENSE_RANK(). Без этого все данные обрабатывались бы как одна группа, что приводило бы к неточному и бессмысленному ранжированию. Освоение использования DENSE_RANK() в SQL может значительно улучшить ваши навыки анализа данных.
В чем разница между RANK() и DENSE_RANK()?
Основное различие между RANK() и DENSE_RANK() заключается в том, как они обрабатывают связи. В то время как RANK() оставляет пробелы в ранжировании связанных данных, DENSE_RANK() присваивает идентичные ранги связанным точкам данных без каких-либо пробелов. Кроме того, функция RANK() всегда увеличивает номер ранга на 1 для каждой новой строки, тогда как функция DENSE_RANK() поддерживает непрерывное ранжирование.
https://www.kdnuggets.com/breaking-down-denserank-a-step-by-step-guide-for-sql-enthusiasts