
Как пользователи Linux, мы регулярно взаимодействуем с различными типами файлов. Одним из наиболее распространенных типов файлов в любой компьютерной системе является обычный текстовый файл. Зачастую очень часто требуется найти нужный текст в этих файлах.
Однако эта простая задача быстро становится надоедливой, если файл содержит повторяющиеся записи. В таких случаях мы можем использовать команду uniq для эффективной фильтрации повторяющегося текста.
В Linux мы можем использовать команду uniq, которая пригодится, когда мы хотим вывести список или удалить повторяющиеся строки, расположенные рядом.
Помимо этого, мы также можем использовать команду uniq для подсчета повторяющихся записей. Важно отметить, что команда uniq работает только тогда, когда повторяющиеся записи находятся рядом.
В этой статье мы рассмотрим команду uniq с практическими примерами в Linux.
Синтаксис команды.
Синтаксис команды uniq очень прост для понимания и похож на другие команды Linux:
uniq [OPTIONS] [INPUT] [OUTPUT]
Позволю заметить, что все опции и параметры команды uniq являются необязательными.
Создадим образец текстового файла.
Для начала давайте создадим простой текстовый файл с помощью текстового редактора и добавим следующее дублирующее содержимое, расположенное в соседних строках.
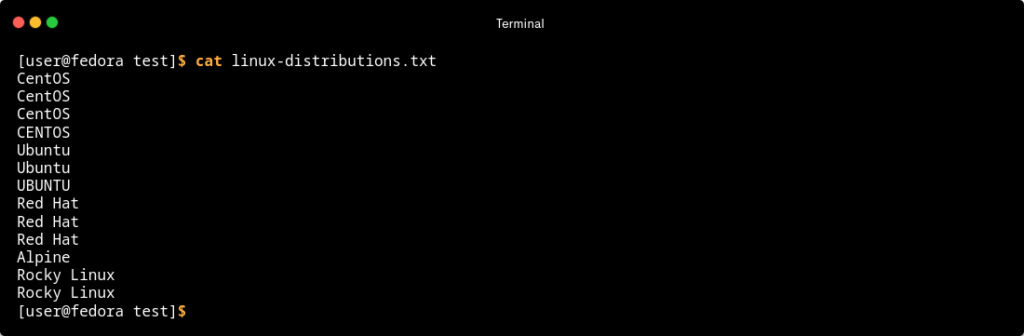
Теперь давайте воспользуемся этим файлом, чтобы рассмотреть использование команды uniq.
Удалить повторяющиеся строки.
Одним из распространенных вариантов использования команды uniq является удаление соседних повторяющихся строк из текстового файла.
$ uniq linux-distributions.txt
В приведенном выше выводе мы видим, что команда uniq успешно удалила дублированные строки.
Посчитать дублирующиеся строки в файле.
В предыдущем примере мы увидели, как удалить повторяющиеся строки. Однако иногда нам также нужно знать, сколько раз та или иная строка появляется.
Для этого, используется опция -c.
$ uniq -c linux-distributions.txt
В приведенном выше выводе первый столбец представляет количество повторений строки.
Удалить дубликаты без учета регистра.
По умолчанию команда uniq работает с учетом регистра. Однако мы можем отключить это поведение по умолчанию, используя опцию -i.
$ uniq -i linux-distributions.txt
В этом примере мы можем наблюдать, что теперь строки Ubuntu и UBUNTU обрабатываются одинаково. Наряду с этим то же самое происходит со строкой CentOS и CENTOS.
Печать только повторяющихся строк.
Иногда нам нужно просто напечатать повторяющиеся строки из текстового файла, в этом случае вы можете использовать опцию -d.
$ uniq -d linux-distributions.txt
В приведенном выше выводе мы видим, что команда uniq показывает повторяющуюся запись из каждой группы.
Распечатать все повторяющиеся строки из файла.
В предыдущем примере мы увидели, как отображать дублирующую строку из каждой группы. Аналогичным образом мы можем показать все повторяющиеся строки, используя опцию -D:
$ uniq -D linux-distributions.txt
В приведенном выше выводе не отображается текст UBUNTU, CENTOS и Alpine, поскольку это уникальные строки.
Разделить повторяющиеся строки по группам.
В предыдущем примере мы напечатали все повторяющиеся строки. Однако мы можем сделать тот же вывод более читабельным, разделив каждую группу новой строкой.
Для этого воспользуемся опцией —all-repeated=separate
$ uniq --all-repeated=separate linux-distributions.txt
В приведенном выше выводе мы видим, что каждая повторяющаяся группа разделена пустой строкой.
Печать только уникальные строки.
В предыдущих примерах мы рассмотрели, как печатать повторяющиеся строки. Точно так же мы можем указать команде uniq печатать только неповторяющиеся строки.
Для этого воспользуемся опцией -u для печати только уникальных строк:
$ uniq -u linux-distributions.txt
Здесь мы видим, что команда uniq отображает строки, которые не дублируются.
Удаление несмежных повторяющихся строк.
Одним из тривиальных ограничений команды uniq является то, что она удаляет только соседние повторяющиеся записи. Однако иногда нам нужно удалить повторяющиеся записи независимо от их порядка в данном файле.
В таких случаях сначала мы можем отсортировать содержимое файла, а затем передать этот вывод команде uniq.
$ sort linux-distributions.txt | uniq
В этом примере мы использовали команды sort и uniq без каких-либо параметров. Однако мы также можем комбинировать с этими командами другие поддерживаемые параметры.
Заключение.
В этой статье мы рассмотрели команду uniq на практических примерах. Знаете ли вы какой-нибудь другой лучший пример команды uniq в Linux? Дайте знать в комментариях ниже.
P.S. Если вам интересен материал не забывайте ставить палец вверх под статьей. А так же, подписывайтесь на анонсы новых статей в телеграмм и на сайте RoadIT