
Дада, ты не ослышался, начиная с bash 4.0 можно и такое провернуть. Дай нам палку и гвоздь, а мы сделаем из этого кофеварку, мыж с тобой настоящие инженеры-программисты, ее!
Летсгоу! Есть у меня огромный txt файл со словами, отсортированный по алфавиту. Нет, не словарь для брутфорса.
Если на него натравить sed, то скорость извлечения нужного слова из файла — ну совсем никакая, сидишь ждешь, пока этот сыщик Коломбо, что-то откроет-отроет. Но в век высокий технологий, скорость как-никак в приоритете.
SED – это потоковый редактор текста (от stream editor), c помощью которого можно выполнять с файлами множество операций вроде поиска и замены, вставки или удаления. При этом чаще всего он используется именно для поиска и замены.
Давай разгонять этого ленивца «Блиц, скорость без границ»
Каков план:
1. Отсортировать содержимое txt файла по алфавиту
2. Проиндексировать данные
Так как файл у меня содержит слова (не цифры и т.п.), то индексами я сделаю диапазоны строк начинающихся на определенную букву.
sort -o data.txt data.txt
Эта команда отсортирует содержимое файла data.txt по алфавиту и перезапишет его в нужном мне формате.
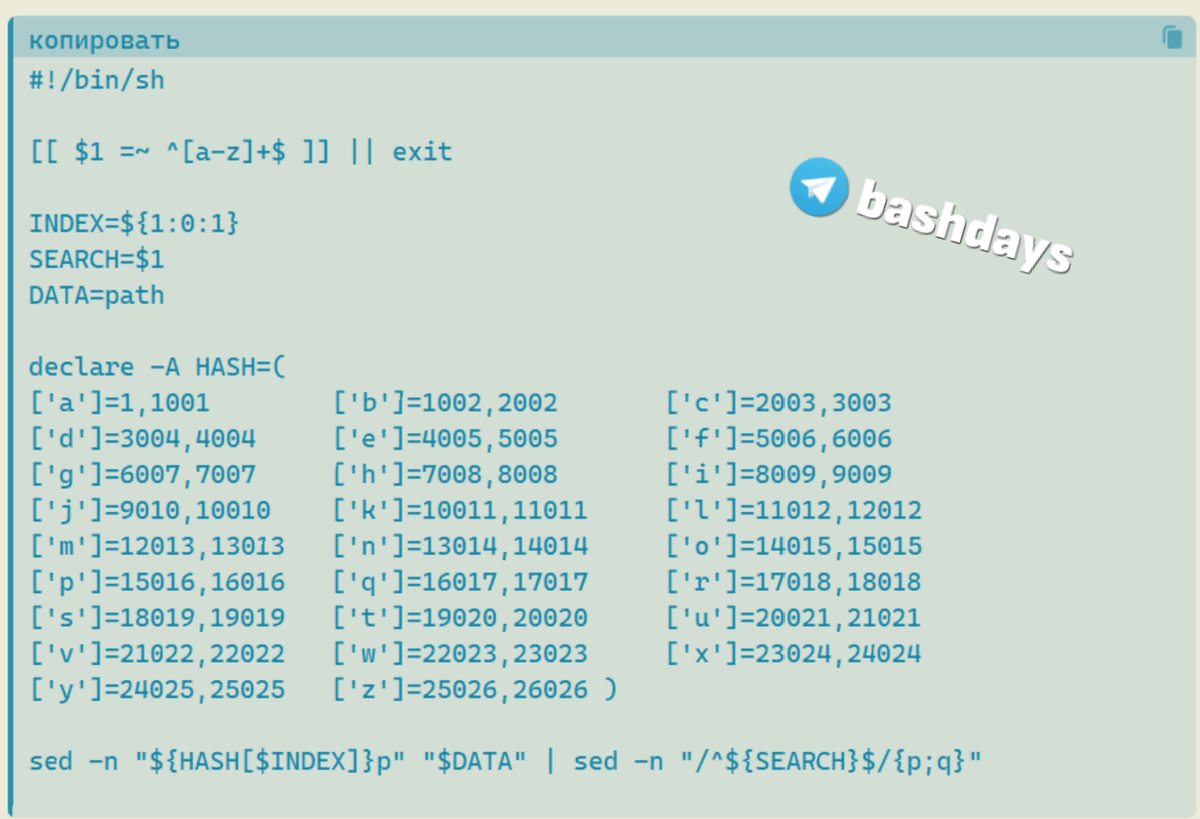
Пишем код
Проверяем первый аргумент переданный в скрипт. Если передать что-то кроме букв, то экзитим:
[[ $1 =~ ^[a-z]+$ ]] || exit
Берем первую букву из первого аргумента и присваиваем её переменной.
INDEX=${1:0:1}
Инициализируем переменную SEARCH значением первого аргумента, чтобы нам было удобнее в будущем. Это будет искомым словом по нашей базе.
SEARCH=$1
Далее объявляем переменную DATA. В которой будет указываться путь до нашего файла. Который мы заранее отсортировали по алфавиту.
DATA=data.txt
Объявляем и инициализируем hash ассоциативный массив. Будет работать начиная с bash 4.0, это важно.
declare -A HASH=(['a']=1,1001 ['b']=1002,2002 ['c']=2003,3003)
Тут я сократил, ниже скрипт полностью.
Здесь можешь ручками заполнить этот хэш, а можешь еще один скрипт написать, чтобы автоматом заполнился. Но проще ручками, чтобы не тратить время.
Что это за конструкция? Ну смотри, берем индекс ['a']. В файле data.txt слова начинающиеся c 'а' и идут с первой строки до 1001, далее начинаются слова на букву 'b' строки 1002-2002, ну и так далее.
Короче выявляем короткие диапазоны, по которым будем осуществлять дальнейший поиск. Зачем тебе лопатить весь файл, если можно пройтись по нужному диапазону.
Далее отдаём утилите «sed» диапазон строк и само искомое слово. В данном примере я делаю два вызова через пайп (pipe), но можно извернуться и обойтись одним.
sed -n "${HASH[$INDEX]}p" | sed -n "/^${SEARCH}$/{p;q}"
Весь скрипт будет выглядеть так:
➕ Подпишись на BashDays в телеграм
Ничего сложного, а самое главное мы используем инструменты, которые поставляются из коробки с Linux. Ну и конечно же в несколько тысяч раз повысили и оптимизировали скорость чтения данных из огромного текстового файла.
Не нужно стрелять из пушки по воробьям используя какие-то мастодонтные решения. С помощью гвоздя и палки, можно творить настоящие чудеса.
Надеюсь коллеги вам было интересно. Show must go on!