Резюме
Комплексное руководство по Python для обработки данных, обучения и вывода клонированных ИИ голосов. От голосовых данных до использования предварительно обученных и пользовательских моделей.

Представьте себе мир, в котором ваш голос может гармонировать с любой мелодией, принимать любой акцент или даже повторять культовый тембр легендарных певцов. Это реальность, ставшая возможной благодаря клонированию поющего голоса ИИ.
Эта революционная технология объединяет музыкальное искусство с точностью машинного обучения, позволяя нам создавать новые песни или переосмысливать классику любым голосом, который мы пожелаем.
Клонирование голоса ИИ — это технология, которая фиксирует уникальные характеристики голоса, а затем воспроизводит их с поразительной точностью. Эта цифровая алхимия позволяет нам не только воспроизводить существующие голоса, но и создавать совершенно новые.
Это инструмент, который произвел революцию в создании контента: от персонализированных песен до индивидуальной озвучки, открыв мир творческих возможностей, преодолевающих языковые и культурные барьеры.
Цель этой статьи — предоставить читателям подробное руководство Python по использованию технологии клонирования голоса искусственным интеллектом — комплексного решения для преобразования любого звука в тоны выбранного исполнителя или даже в собственный голос путем обучения специальной модели.
Эта обучающая статья структурирована следующим образом:
1. Объяснение технологий и теоретических концепций
2. Использование библиотеки Python SO-VITS-SVC для вывода
3. Обучение пению вашей собственной модели искусственного интеллекта
4. Практическое применение и выводы.
1. Технологические предпосылки
Технология, которую мы будем использовать в этой статье, называется преобразованием певческого голоса (SVC), в частности системой под названием SO-VITS-SVC, что расшифровывается как «SoftVC VITS Singing Voice Conversion».
Система SO-VITS-SVC представляет собой сложную реализацию преобразования певческого голоса (SVC) с использованием технологий глубокого обучения. Понимание этой системы требует понимания конкретных архитектур и алгоритмов машинного обучения, которые она использует.
1.1 Вариационный вывод и генеративно-состязательные сети
- В основе SO-VITS-SVC лежит архитектура вариационного вывода для преобразования текста в речь (VITS). Эта система гениально сочетает в себе вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN).
- VAE используются для моделирования распределения мел-спектрограмм, которые являются ключевым представлением аудиосигнала в SVC. Компонент VAE помогает улавливать скрытые переменные речи.
- Функция потерь VAE представлена по формуле, приведенной ниже. где x — входная мел-спектрограмма, z — скрытая переменная, а KL обозначает расхождение Кульбака-Лейблера.
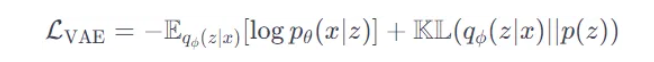
- GAN повышают реалистичность синтезированного звука. Дискриминатор в GAN анализирует выходные данные генератора, повышая его точность. Функция потерь GAN определяется следующим образом:
1.2 Процесс мелкой диффузии
- Как показано на прилагаемой диаграмме, процесс мелкой диффузии начинается с выборки шума, которая постепенно уточняется до структурированной мел-спектрограммы посредством серии преобразований.
1. Исходный образец шума: визуальное представление шума, которое служит отправной точкой для процесса распространения.
2. Этапы преобразования. Шум проходит ряд этапов в рамках диффузионной модели, переходя от неупорядоченного состояния к структурированной мел-спектрограмме. Это можно описать, как показано ниже, где xt — данные на шаге t , а ϵ представляет собой гауссов шум.
- В контексте SO-VITS-SVC «поверхностный», вероятно, означает меньшее количество слоев или шагов, обеспечивая баланс между вычислительной эффективностью и качеством звука.
3. Уточнение мел-спектрограммы. Результатом этого процесса является мел-спектрограмма, которая инкапсулирует аудиоконтент певческого голоса и готова к следующему этапу синтеза.
4. Вокодирование. На последнем этапе вокодирования мел-спектрограмма преобразуется в звуковой сигнал, который является слышимым певческим голосом.
1.3 Интеграция процесса синтеза с системой SVC
- Уточнение Мел-спектрограммы:
После того, как модель мелкой диффузии структурировала шум в более когерентную форму, как показано на ранее упомянутой диаграмме, результирующая мел-спектрограмма улавливает нюансы звукового содержания певческого голоса. Эта мел-спектрограмма служит ключевым мостом между необработанными, неструктурированными данными и окончательным голосовым выводом.
2. Вокодирование:
Затем вокодер используется для преобразования уточненной мел-спектрограммы в звуковой сигнал. На этом этапе происходит преобразование визуальных данных в слышимый певческий голос. Роль вокодера заключается в синтезе нюансов высоты звука, тембра и ритма, которые были зафиксированы в мел-спектрограмме, тем самым создавая окончательный выходной певческий голос.
3. Обучение и оптимизация:
Для достижения такого высокоточного синтеза система SO-VITS-SVC проходит тщательное обучение и оптимизацию. Обучение включает в себя оптимизацию комбинированной функции потерь, которая уравновешивает вклад компонентов VAE, GAN и модели диффузии.
Эта оптимизация проводится с использованием таких алгоритмов, как Stochastic Gradient Descent или Adam, с конечной целью минимизировать общие потери. Этот процесс гарантирует, что конечный результат будет очень похож на целевой певческий голос с точки зрения тембра, высоты тона и ритма.
4. Окончательный результат:
Конечным продуктом этого процесса является синтезированный голос, который точно отражает целевой певческий голос. Способность сохранять музыкальность и выразительные нюансы источника, перенимая тембральные качества цели, является свидетельством сложности системы SO-VITS-SVC.
1.4 Используемые библиотеки IPython
Форк SO-VITS-SVC, размещенный на GitHub, представляет собой специализированный инструмент, предназначенный для преобразования певческого голоса в реальном времени. Этот ответвление исходного проекта SO-VITS-SVC предлагает расширенные функции, такие как более точная оценка шага с использованием CREPE, графический интерфейс пользователя (GUI), более быстрое время обучения и удобство установки инструмента с помощью pip.
Он также интегрирует QuickVC и исправляет некоторые проблемы, присутствующие в исходном репозитории. Форк поддерживает преобразование голоса в реальном времени, что делает его универсальным инструментом для задач клонирования голоса. Кроме того, он упрощает процесс установки и настройки, делая его более доступным для пользователей, желающих поэкспериментировать с технологией клонирования голоса.
2. Вывод: пойте голосом искусственного интеллекта любого исполнителя.
Вывод относится к процессу, в котором модель нейронной сети после обучения на наборе данных для понимания определенного голоса генерирует новый контент с этим изученным голосом.
На этом этапе мы можем «петь» голосом искусственного интеллекта исполнителя, предоставляя новые входные данные (необработанный звук певческого голоса) предварительно обученной модели, которая затем создает выходные данные, имитирующие стиль пения исполнителя на необработанном голосовом звуке.
2.1 Настройка среды SO-VITS-SVC
Для простоты мы будем использовать Jupyter Notebook с виртуальной средой. Поэтому мы предлагаем начать с этого:
- Установите Anaconda: загрузите и установите Anaconda в свою систему, что позволит вам создавать изолированные среды для различных проектов.
- Откройте терминал Anaconda, создайте новую среду, выполнив следующую команду.
Если вы используете VS Code, вы можете ссылаться на среду из выбора ядра, в противном случае, если вы продолжите использовать Anaconda, активируйте среду с помощью conda active и запустите блокнот Jupyter.
Установите необходимые библиотеки в среду.
- Чтобы избежать описанной ниже проблемы позже, когда мы запустим !svc команду, нам следует перейти в среду anaconda, удалить Torchaudio с помощью pip uninstall torchaudio и установить его снова с помощью pip install torchaudio.
Теперь мы готовы выполнить «преобразование певческого голоса» с использованием предварительно обученной модели на чистом вокале (т. е. без фонового шума).
2.1 Использование предварительно обученной модели для генерации певческого голоса
1. Выбор предварительно обученной модели
Когда среда готова, следующим шагом будет получение предварительно обученной модели. Мы сделали несколько предварительно обученных моделей , которые можно использовать, от Дрейка до Майкла Джексона! Вот варианты:
После того, как решено, какую модель использовать, необходимо получить и загрузить .pth файл модели Pytorch и связанный с ним файл config.json
2. Выбор чистого аудиофайла
Далее мы загрузим чистый аудиофайл для конвертации. Аудиофайл, который мы используем, можно получить и загрузить через Google Диск.
Это чистый вокал Джастина Бибера, который затем можно ввести в систему SO-VITS-SVC для преобразования голоса с использованием выбранной модели.
Хотя это может быть не самая чистая дорожка, при подготовке собственных аудиофайлов к преобразованию крайне важно убедиться, что они максимально чистые, чтобы избежать непреднамеренных артефактов или проблем с качеством сгенерированного звука.
Качество исходного звука существенно влияет на точность преобразования голоса, поэтому всегда рекомендуется использовать высококачественную и чистую запись.
3. Выполнение вывода
Чтобы выполнить преобразование голоса с использованием модели SO-VITS-SVC, вам потребуется указать пути к вашему аудиофайлу, контрольной точке модели и файлу конфигурации. Вот как вы можете установить пути и запустить вывод.
Убедитесь, что вы запускаете эту команду в среде, у которой есть доступ к !svcкоманде, например в командной строке или сценарии, который выполняется в среде, где установлен инструмент SO-VITS-SVC.
4. Отображение вывода
После выполнения вывода вы можете отобразить выходной звук непосредственно в блокноте Jupyter или в любом интерфейсе IPython. Следующий фрагмент кода будет воспроизводить полученный аудиофайл:
5. Необязательно — используйте графический интерфейс, чтобы сделать выводы
Для пользователей, предпочитающих графический интерфейс, система SO-VITS-SVC предоставляет дополнительный графический интерфейс для преобразования голоса.
Этот многофункциональный графический интерфейс упрощает процесс вывода, предлагая альтернативу операциям в командной строке. Его можно запустить, используя следующее
- Настройка: запустите графический интерфейс и настройте необходимые пути для модели, конфигурации и аудиофайлов с помощью кнопок «Обзор».
- Выбор модели: выберите подходящую предварительно обученную модель в поле «Путь к модели».
- Конфигурация: выберите файл конфигурации, соответствующий вашей модели, в поле «Путь конфигурации».
- Аудиовход: загрузите целевой аудиофайл для преобразования, используя «Входной путь к аудио».
- Вывод: нажмите кнопку «Вывод», чтобы начать процесс преобразования, при необходимости корректируя любые дополнительные параметры.
- Вывод: сохраните и прослушайте сгенерированный вывод непосредственно через графический интерфейс, чтобы убедиться, что качество соответствует вашим ожиданиям.
Графический интерфейс также предлагает возможности вывода в реальном времени, что позволяет вносить коррективы «на лету» и немедленную звуковую обратную связь.
Он разработан для простоты использования и предназначен для пользователей, которым могут быть неудобны сценарии или инструменты командной строки.
2. Модельное обучение: научим ИИ петь, как вы
Теперь мы покажем шаги, которые необходимо предпринять для обучения пользовательской модели преобразования певческого голоса с использованием системы SO-VITS-SVC. Мы начнем с подготовки набора данных, перейдем к настройке среды и обучению модели и завершим выводом, создав певческий голос из существующего аудиоклипа.
Прежде чем мы углубимся в процесс обучения модели, важно отметить, что эта задача требует больших вычислительных ресурсов и требует системы с высокопроизводительным графическим процессором и значительным объемом видеопамяти — обычно более 10 ГБ.
Для тех, чье личное оборудование может не соответствовать этим требованиям, Google Colab предлагает жизнеспособную альтернативу, предоставляя доступ к мощным графическим процессорам и достаточному объему памяти для облегчения обучения — графического процессора T4 должно быть достаточно. Вывод не требует такого большого количества видеопамяти.
2.1 Подготовка данных
На Hugging Face вы можете найти множество наборов голосовых данных, подходящих для обучения пользовательской модели so-vits-svc. Однако, чтобы придать вашей модели уникальные вокальные характеристики, запись собственного голоса — более интересный способ.
Запись собственных голосовых сэмплов
- Длина образца: запишите свое выступление и пение отрывками, в идеале по 10 секунд каждый. Эта длина оптимальна для передачи нюансов вашего голоса без особых требований к обработке.
- Количество образцов: чем больше данных, тем лучше. Постарайтесь записать как минимум 200 образцов своего голоса. Хороший микс может состоять из 50 сэмплов пения и 150 сэмплов речи.
- Общая продолжительность аудио: ваша цель должна состоять в том, чтобы накопить как минимум пять минут общего аудио. Это обеспечивает прочную основу для модели, на которой можно учиться.
- Разнообразный контент: освойте широкий спектр фонем, читая фонетически сбалансированные предложения. Рекомендованная IEEE практика измерения качества речи предлагает список таких предложений, которые могут способствовать формированию всестороннего набора данных.
- Инструмент записи: Audacity — это бесплатное программное обеспечение с открытым исходным кодом, которое идеально подходит для записи ваших сэмплов. Он позволяет легко записывать, редактировать и экспортировать файлы WAV.
Дальнейшая подготовка образцов голоса
- Удаление фонового шума. Возможно, нам придется удалить фоновые шумы из звуковых дорожек. Spleeter— отличная библиотека Python для этого. См. пример ниже. Однако обязательно сохраните файл в формате WAV.
2. Разделение аудиодорожки на 15-секундные фрагменты. Мы можем использовать AudioSlicer разбиение обширного аудиофайла на 10–15-секундные фрагменты, подходящие для обучения модели.
2.2 Автоматическая предварительная обработка
Создав папку dataset_raw в текущем каталоге и записи записей, хранящиеся в этом dataset_raw/{speaker_id} каталоге, как показано в структуре папок ниже, вы готовы начать этапы предварительной обработки и обучения для вашей модели преобразования певческого голоса.
Предварительная обработка включает в себя 3 ключевых этапа подготовки аудиоданных для обучения модели — !svc pre-resample, !svc pre-config, !svc pre-hubert для окончательного запуска !svc train.
2.3 Конфигурация обучения
Прежде чем приступить к обучению, важно настроить модель так, чтобы обеспечить оптимальные условия обучения. Это предполагает редактирование config.json файла, созданного в config/44k/ каталоге во время предварительной обработки. Ключевые параметры этого файла конфигурации включают: log_interval, eval_interval, epochs, batch_size:
Для набора данных с 200 выборками и размером пакета 20 каждая эпоха соответствует 10 шагам. Если вы стремитесь к 100 эпохам, это означает 1000 шагов. Желательно добавить единицу к счетчику эпох, чтобы гарантировать сохранение последнего шага.
По умолчанию может предлагаться 10 000 эпох, но в зависимости от вашего оборудования и размера набора данных вам может потребоваться изменить это значение. Практический подход мог бы заключаться в том, чтобы пробежать 20 000 шагов и оценить результаты, прежде чем принимать решение о продлении тренировки.
2.4 Начать обучение
Начните фактическое обучение модели с svc train команды. Это запустит процесс машинного обучения с использованием предварительно обработанных данных из dataset/44k/{speaker_id} каталога и настроек конфигурации в формате config/44k/config.json.
2.5 Вывод модели
После того, как модель обучена, настроена и проверена, следующим шагом будет запуск вывода для преобразования исходного звука в целевой голос, как описано в предыдущем разделе.
После выполнения вывода вам может потребоваться дополнительная настройка вывода. Например, если исходный звук пел, и вам нужно смешать его с фоновой музыкой или если вы хотите отрегулировать высоту звука, вы можете использовать инструменты обработки звука, такие как Audacity, или любую другую рабочую станцию цифрового аудио, чтобы микшировать и сопоставлять треки по своему вкусу. .
4. Практическое применение решения.
- Улучшение музыкального производства . Продюсеры экспериментируют с различными вокальными текстурами и стилями, не требуя физического присутствия артистов. Это может быть особенно полезно для концептуализации новых треков или для добавления бэк-вокала различной высоты и тембра.
- Персонализированный музыкальный опыт . Представьте себе сервис, где фанаты могут получить версию своей любимой песни, исполненную голосом другого исполнителя или даже своим собственным голосом, используя специальную модель.
- Дублирование фильмов и анимации . Дубляж фильмов, мультфильмов и игр может извлечь выгоду из SO-VITS-SVC за счет создания закадровой речи различными голосами персонажей, особенно когда оригинальные актеры недоступны. Он может создавать согласованные вокальные исполнения в разных языковых версиях.
- Образовательные инструменты . При изучении языка SO-VITS-SVC может улучшить понимание, позволяя учащимся слышать текст, прочитанный вслух своим собственным голосом, с правильным акцентом и интонацией различных языков, способствуя развитию навыков аудирования и разговорной речи.
- Восстановление голоса . Для людей, потерявших способность говорить, SO-VITS-SVC может быть обучен на записи их голоса, чтобы восстановить их способность общаться таким образом, чтобы сохранить сущность их первоначального голоса.
- Возрождение исторических голосов . Оживите исторические речи, клонируя голоса из прошлого, обеспечивая захватывающий слуховой опыт в музеях или образовательном контенте.
Заключение
Последствия этой технологии глубоки и далеко идущие. В ближайшем будущем мы можем стать свидетелями демократизации музыкального производства, когда независимые артисты будут использовать ИИ для дуэта с любым историческим голосом, а преподаватели будут использовать его для устранения языковых барьеров в классах по всему миру. Но истинный потенциал SO-VITS-SVC заключается в его долгосрочном применении, которое нам еще предстоит полностью понять или представить.
Представьте себе мир, в котором каждое цифровое взаимодействие персонализируется не только с учетом ваших визуальных предпочтений, но и с учетом слухового комфорта. Мир, где виртуальная реальность — это не просто визуальное зрелище, а слуховой праздник, где каждый персонаж, каждое существо может разговаривать с вами голосами, неотличимыми от реальных человеческих. SO-VITS-SVC может стать предвестником виртуальных существ со своими уникальными голосовыми особенностями, способных петь, говорить и взаимодействовать на множестве языков и стилей.
.
❤️ Если вам понравилась статья, ставьте лайк и подписывайтесь на мой канал "Заходи в Ай-Ти".
👍 Если у вас остались вопросы или есть интересные темы, которые вы хотите, чтобы я разобрал, то пишите в комментариях. Ваше мнение очень важно для меня!
.
#искуственный интеллект #нейросеть для клонирования голоса #нейросеть на python #код нейросети на python #python нейросеть с нуля #написание нейросети на python #нейросеть питон #нейросеть для кода питон #написать код питон нейросеть #нейросеть на пайтон