
Недавно в одном из проектов мне потребовалось решить задачу поиска по содержанию файлов популярных форматов, таких как doc, docx, xls, csv и pdf.
В данной статье я хотел бы поделиться своим опытом написания скрипта на PHP для поиска по содержимому документа.
Подготовка
Перед тем как продолжить хочу уточнить, в статье я не буду рассказывать как установить Sphinx. Все ниже изложенное написано с тем учетом, что система Sphinx уже установлена и настроена.
Так как Sphinx напрямую не может работать с файлами форматов .doc, .xls, .csv, .pdf и т.п., необходимо подготовить данные, которые он сможет обработать. Я буду использовать формат XML. Для обработки данных в этом формате используется драйвер xmlpipe (или xmlpipe2). Другими словами, чтобы проиндексировать информацию в файлах формата PDF, DOC и DOCX, ее нужно передать Sphinx в формате XML.
Чтобы выполнить эту задачу, необходимо написать скрипт, который будет парсить файлы, считывать данные и передавать их в нужном формате.
Настройка Sphinx
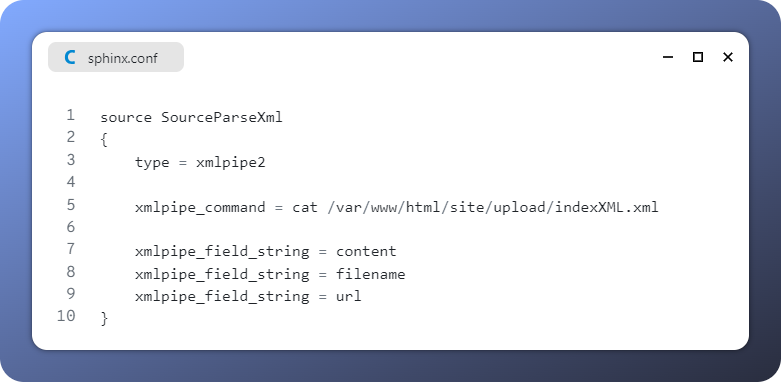
Перед тем как начать реализовывать парсинг и генерацию XML, необходимо настроить Sphinx на новый источник данных. Для этого перейдем к конфигурационный файл и сделаем следующие изменения:
Блок source содержит описание источника данных для нашего индекса, параметров доступа к ним, атрибутов и правил их анализа.
Блок index содержит настройки построения индекса с использованием источника.
Блок indexer содержит настройки индексатора.
Блок searchd содержит порты и переменные для запуска демона Sphinx. Настройки демона обычно всегда стандартные, указываем адрес, порт демона и пути к логам.
Подробнее о настройках можно прочитать в официальной документации Sphinx.
Реализация
Парсинг файлов и генерация XML
С помощью функции parseFiles() проводим парсинг фалов в форматах .doc, .xls, .csv, .pdf и других.
Для парсинга фалов MS Office (doc, docx, xls, xlsx, xlm и т.д.) используется пакет LibreOffice 7.6. Он также поддерживает другие форматы (подробности можно найти в документации).
Для парсинга PDF-файлов мы используем пакет PdfToText. Хочу обратить ваше внимание, что парсинг PDF этим способом возможен только в том случае, если содержимое PDF-файла не является изображением (например, отсканированный документ).
С помощью функции createXmlSphinx() мы генерируем правильный XML для индексирования. Эта функция использует функцию getFileContent(), которая извлекает контент из файлов, подготовленных функцией parseFiles().
Хочу обратить ваше внимание, что функция getFileContent() сканирует папку с исходными файлами и обращается к папке с подготовленными файлами, поэтому важно соблюдать следующее правило:
<имя исходного файла> = <имя подготовленного файла>
Индексация и поиск
Для того, чтобы произвести поиск, необходимо выполнить индексацию. Индексация выполняется командой:
indexer --all --rotate
из PHP
shell_exec('indexer --all --rotate');
Теперь можно перейти к реализации поиска. Для этого я буду использовать PDO.
В результате получился готовый набор функций, с помощью которых можно реализовать поиск по содержимому документов в следующих форматах: doc, docx, rtf, xls, xlsx, xlsm, csv, pdf.
На Boosty вы можете найти готовые файлы с комментариями к коду. Также рекомендую подписаться на Boosty, так как там контент выходит раньше.
===