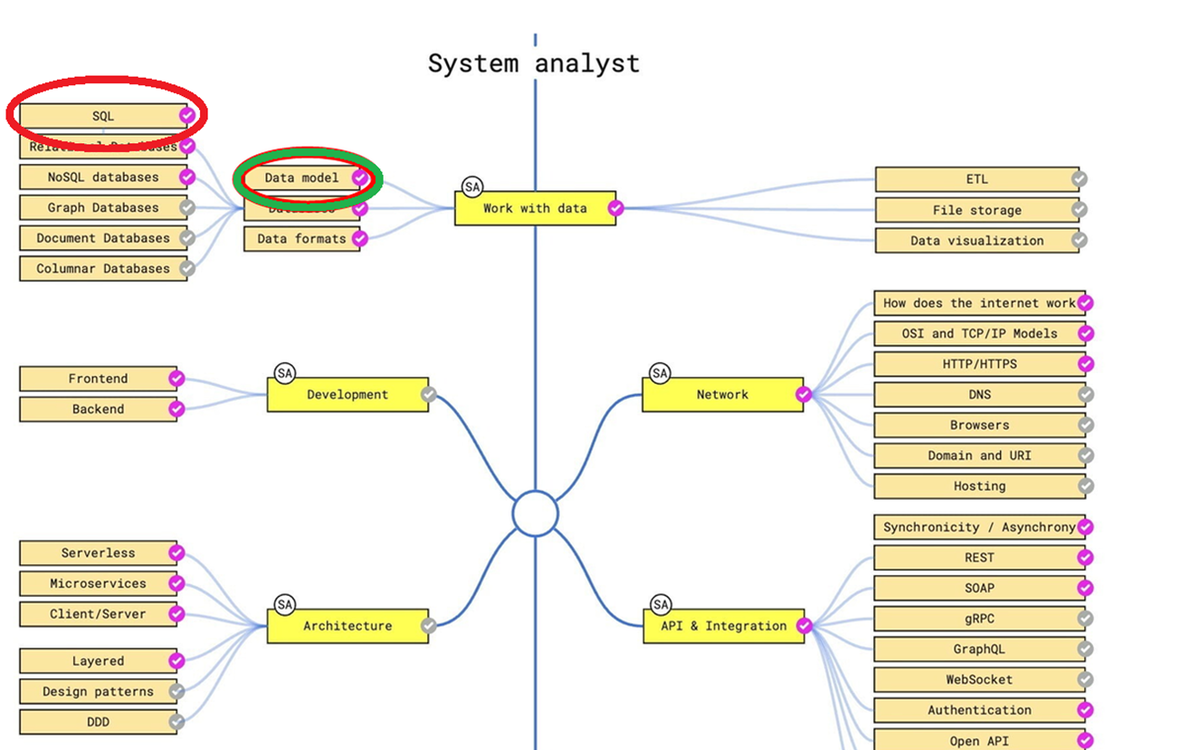
Перед вами карта компетенций системного аналитика. В предыдущей статье мы рассматривали data modeling, а сейчас рассмотрим SQL.
Типы данных
Для начала разберемся, как вообще представляются и хранятся данные. На примере типов данных в С++ рассмотрим основные типы данных:
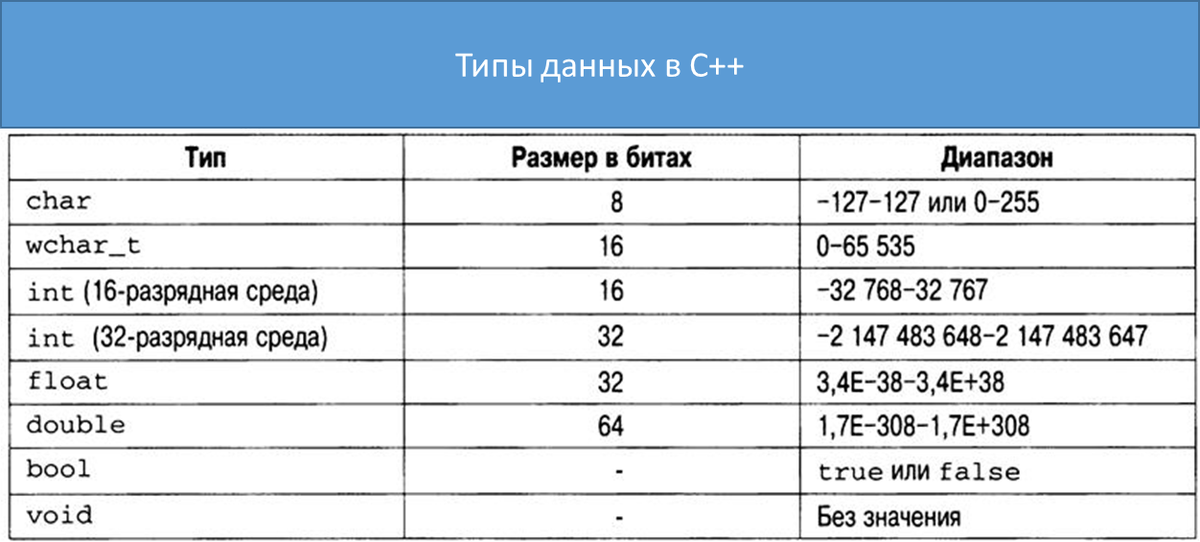
Тип данных char предназначен для хранения одного символа, например, буквы.
Есть также wchar_t, он предназначен для хранения широких символов в том виде, в котором их понимают конкретные компиляторы. Например, что-то из юникода.
В int хранятся целочисленные данные.
Во float и double – данные с плавающей точно, например, 3.14. Причем, Double может хранить заметно большие числа.
В bool удобно хранить признаки, например, женат/холост или совершеннолетний/ не совершеннолетний.
Структуры данных
Из отдельных данных можно собрать массив фиксированной длины. Назовем такой массив структурой данных. Например, у нас есть какой-то клиент, у которого есть имя, возраст и семейное положение. Данные о нем можно хранить в структуре, состоящей из varchar (100) – это просто набор из 100 переменных типа char (тут мы считаем, что имя не может содержать больше ста символов), возраст будет храниться в переменной типа int, а семейное положение - это признак и его мы положим в переменную типа bool.
Массивы структур
В базах данных хранятся таблицы, которые по сути просто являются массивами из таких вот структур. Например, таблица с данными нашего клиента в БД будет выглядеть вот так. Про то как могут быть связаны между собой таблицы мы говорили в предыдущей статье, где разбирали проектирование предметной области.
SQL запросы
Ну и раз в БД хранятся какие-то данные, их, очевидно нужно как-то оттуда доставать. Для этого есть SQL запросы. Структуру такого запроса вы видите на экране.
Select это собственно ключевое слово, которое говорит базе данных что мы хотим что-то из нее достать, дальше словом distinct можно указать что нас интересую только уникальные данные. Так же можно использовать Top, чтобы получить только ограниченное количество данных. Например, Top (100) выдаст первые 100 записей, подходящих под условие.
Далее нужно указать названия колонок, из которых мы хотим достать данные и название таблицы. Если нужны все колонки тут можно просто поставить *. К колонкам можно применить агрегирующую функцию. Например, посчитать сумму, среднее значение и т.д.
Далее пишем FROM и указываем из какой таблицы надо забрать данные, тут же можно указать с какими таблицами нужно нашу таблицу объединить, чтобы обогатить данными и как нужно это сделать – про это мы поговорим чуть позже.
Далее после слова WHERE или HAVING мы можем указать условия для фильтрации данных, например, можем выбрать только совершеннолетних или только женатых/замужних. Причем Having используется в случае если мы задаем условие к какой-то из колонок, к которой применяли агрегирующую функцию.
Ну и Goup By используется для объединения строк с одинаковыми значениями, например если мы хотим найти количество людей каждого возраста, можно сделать запрос
SELECT COUNT(CustomerID), Age
FROM Customer
GROUP BY Age;
А ORDER BY используется для сортировки по той или иной колонке.
Например, в предыдущем запросе мы можем сортировать возраст по убыванию (по умолчанию сортировка идет по возрастанию, поэтому для сортировки по убыванию мы добавляем DESC):
SELECT COUNT(CustomerID), Age
FROM Customer
GROUP BY Age;
ORDER BY Age DESC;
В принципе все эти ключевые слова можно писать и маленькими буквами, но рептилоиды из секты свидетелей SQLтакое не одобряют.
Join
Ну и наконец join. Их существует несколько видов:
Оператор INNER JOIN формирует таблицу из записей двух или нескольких таблиц. Каждая строка из первой (левой) таблицы, сопоставляется с каждой строкой из второй (правой) таблицы, после чего происходит проверка условия.
Если условие истинно, то строки попадают в результирующую таблицу. В результирующей таблице строки формируются конкатенацией (ну то есть склеиванием) строк первой и второй таблиц.
Оператор LEFT JOIN также осуществляет формирование таблицы из записей двух или нескольких таблиц. В этом операторе, как и в операторе RIGHT JOIN, важен порядок следования таблиц, так как от этого будет зависеть полученный результат. Алгоритм работы оператора следующий:
- Сначала происходит формирование таблицы внутренним соединением (это оператор INNER JOIN) левой и правой таблиц
- Затем, в результат добавляются записи левой таблицы не вошедшие в результат формирования таблицы внутренним соединением. Для них, соответствующие записи из правой таблицы заполняются значениями NULL.
RIGHT JOIN – то же самое, только таблицы меняются местами по сути.
FULL OUTER JOIN - cоединение, которое выполняет внутреннее соединение записей и дополняет их левым внешним соединением и правым внешним соединением.
Алгоритм работы полного соединения:
- Формируется таблица на основе внутреннего соединения (INNER JOIN)
- В таблицу добавляются значения не вошедшие в результат формирования из левой таблицы (LEFT OUTER JOIN)
- В таблицу добавляются значения не вошедшие в результат формирования из правой таблицы (RIGHT OUTER JOIN)
В заключении повторим основные моменты:
- Данные бывают разных типов.
- Из них можно собирать структуры.
- Массивы таких структур хранятся в базах данных.
- Наборы данных из БД можно получать при помощи запросов.
- Если в таких запросах необходимо объединять данные из нескольких таблиц, для этого используются join.