Бинарная кросс-энтропия, также известная как логарифмическая потеря, это функция потерь, используемая в машинном обучении для задач бинарной классификации. Она измеряет эффективность модели классификации, выход которой - это вероятностное значение между 0 и 1.
Что такое бинарная кросс-энтропия?
Бинарная кросс-энтропия - это метод, используемый для оценки ошибки прогнозирования классификатора. Потери на кросс-энтропии увеличиваются по мере того, как прогнозируемая вероятность отклоняется от фактической метки. Так, прогнозирование вероятности 0.012, когда фактическая метка наблюдения равна 1, будет плохим и приведет к высокому значению потерь. Идеальная модель имела бы логарифмическую потерю равную 0.
Где используется бинарная кросс-энтропия?
Бинарная кросс-энтропия широко используется в области глубокого обучения, особенно в задачах, таких как распознавание изображений, обработка естественного языка и других областях, где требуется бинарная классификация.
Преимущества бинарной кросс-энтропии
Вероятностная интерпретация: Бинарная кросс-энтропия предоставляет вероятностную интерпретацию. Она позволяет модели выводить вероятности каждого класса, что может быть полезно для понимания уверенности модели в своих решениях.
Стабильность: При использовании с сигмоидной функцией активации бинарная кросс-энтропия может быть довольно стабильной, поскольку она менее вероятно достигнет крайних значений.
Производительность: Она часто приводит к лучшей производительности в задачах классификации по сравнению с другими функциями потерь, такими как среднеквадратичная ошибка.
Недостатки бинарной кросс-энтропии
Только бинарная классификация: Бинарная кросс-энтропия подходит только для задач бинарной классификации. Для задач многоклассовой классификации потребуется использовать категориальную кросс-энтропию.
Чувствительность к несбалансированным данным: Бинарная кросс-энтропия может быть чувствительной к несбалансированным наборам данных, где количество образцов в каждом классе не равно.
Числовая стабильность: Несмотря на общую стабильность, логарифмические операции в бинарной кросс-энтропии иногда могут приводить к числовой нестабильности.
Формула потерь бинарной кросс-энтропии
Формула выглядит следующим образом:
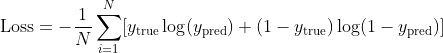
Вот что означает каждая часть формулы:
- N: Это общее количество образцов в вашем наборе данных.
- y_true: Это фактическая метка для каждого образца. В задаче бинарной классификации это будет либо 0, либо 1.
- y_pred: Это предсказанная вероятность того, что образец принадлежит положительному классу (классу 1). Это выход вашей модели.
- log: Это функция натурального логарифма.
Формула вычисляет потери для каждого отдельного образца, используя y_true * log(y_pred) + (1 - y_true) * log(1 - y_pred), а затем усредняет эти потери по всем образцам.
- Термин y_true * log(y_pred) вычисляет потери для положительного класса (когда фактическая метка y_true равна 1). Если модель предсказывает высокую вероятность для положительного класса (то есть y_pred близко к 1), этот термин будет близким к 0. Но если модель предсказывает низкую вероятность (то есть y_pred близко к 0), этот термин будет большим положительным числом, что приведет к большим общим потерям.
- Термин (1 - y_true) * log(1 - y_pred) вычисляет потери для отрицательного класса (когда фактическая метка y_true равна 0). Если модель предсказывает низкую вероятность для положительного класса (то есть предсказывает высокую вероятность для отрицательного класса, поэтому y_pred близко к 0), этот термин будет близким к 0. Но если модель предсказывает высокую вероятность для положительного класса (то есть y_pred близко к 1), этот термин будет большим положительным числом, что приведет к большим общим потерям.
Таким образом, формула потерь бинарной кросс-энтропии эффективно измеряет, насколько хорошо предсказания модели соответствуют фактическим меткам. Она накладывает более тяжелые штрафы на уверенные, но неверные предсказания, что помогает модели со временем делать более точные предсказания.
Ниже вы можете увидеть Python код:
Весь код, и даже больше, в моем телеграм канале.