Привет, сегодня я хотел бы поделиться информацией о своей коммерческой разработке, связанной с коннектором под Greenplum v6, который я разрабатываю на Python и который использует:
- subprocessing подход (по сути wrapper) с использованием psql тулзы
- фукнционал "parallel retrieve cursor", который доступен в Greenplum
На данный момент я разрабатываю его в одиночку, но:
- он уже демонстрирует успехи, уже на стороне бизнес-заказчика в одном коммерческом проекте
- скоро появится новый QA-тестер, которого наняла моя компания, и который будет занят исключительно тестированием коннектора (т.к. пока я один всем занят)
Прямое извлечение данных с сегментов с использованием параллельных курсоров.
Одной из самых интересных особенностей коннектора является использование "параллельных курсоров" из Greenplum. Вместо того, чтобы пропускать все операции через мастер-ноду, коннектор создает параллельный retrieve-курсор, где количество связанных endpoints соответствует количеству primary-сегментов. Такой подход позволяет запросу напрямую получать данные с сегментов, сокращая задержки в сети и эффективно распределяя нагрузку.
Вот, что происходит "за кулисами":
1). Использование параллельных курсоров, когда основная сессия запускается, коннектор отправляет команду на создание параллельного курсора. Этот курсор настраивается на параллельное чтение данных по всем доступным сегментам:
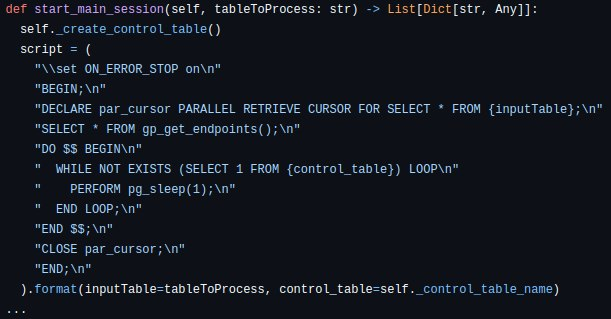
Здесь стоит пояснить, почему я выбрал именно такое решение.
Прежде всего, корректная работа с драйверами JDBC/psycopg2 не обеспечивается, поскольку retrieve-сессия Greenplum достаточно специфична, и самым стабильным подходом оказалось подготовка wrapper, который управляет выполнением psql тулзы. Именно поэтому, Вы видите такой SQL, который обрабатывается следующим методом:
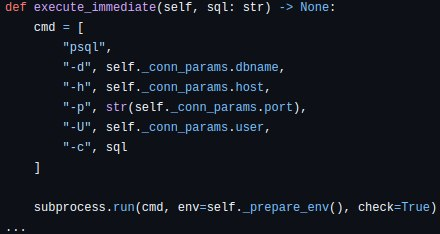
Конечно, я подготовил множество мест по синхронизации в коде для корректного контроля выполнения работы коннектора.
Часть, где используется pg_sleep() в приведенном выше коде, необходима, чтобы основная сессия не была завершена преждевременно. Если бы сессия была завершена, то данные с endpoints параллельного курсора (которые указывают непосредственно на сегменты) получить не удалось бы...
Конечно, данный процесс контролируется из другого метода (мониторинг осуществляется с помощью pg_stat_activity), пока идут основные работы по извлечению данных. Когда задания завершаются, PID Postgres связанный с удержанием "основной сессии" будет убит, что завершит работу цикла с pg_sleep().
2). Использование thread pool executor и futures, одним из самых значимых мест в коде коннектора является то, как он оркестрирует параллельную обработку с помощью "concurrent.futures.ThreadPoolExecutor":
"ThreadPoolExecutor" управляет пулом потоков. Благодаря его использованию, мой Greenplum-коннектор способен обрабатывать несколько endpoints курсора - параллельно. Вот, что происходит:
- отправка задач, для каждого endpoints (каждый из которых, по-сути, представляет доступ к сегменту) коннектор отправляет задачу посредством "executor.submit(processing_func, x)".
- cбор futures, каждый вызов submit возвращает объект future, который сохраняется в списке, то есть в этот момент у коннектора накапливается коллекция ожидающих задач - по одной для каждого endpoint.
- получение результатов, строка "list(map(lambda x: x.result(), futures))" проходит по всем объектам futures и вызывает метод result() для каждого из них. Этот шаг ожидает завершения каждой асинхронной операции, обеспечивая, что каждая задача по обработке данных с каждого сегмента будет завершена до перехода программы к следующему этапу.
Такой подход позволяет одновременно обрабатывать данные с нескольких endpoints, связанных с параллельным курсором.
Стриминг на основе сокетов. Отправка чанков по сети.
Еще одной особенностью моего коннектора является возможность отправлять данные чанками по сети на сокет-сервер (есть дополнительный сервис, которой я подготовил, т.е. сам сокет-сервер). При работе в режиме "NETWORK_STREAMING" (есть еще два других режима) коннектор не просто извлекает данные, он формирует данные в ОЗУ и напрямую отправляет их на сокет-сервер, который также разработан на Python.
Как это работает?
- идет подготовка чанка, т.е. коннектор подготавливает чанк из данных и вычисляет его размер в байтах.
- взаимодействие через сокет-клиент, с помощью модуля сокет-клиента коннектор подключается к сокет-серверу, устанавливает параметры согласно внутреннему протоколу (например, размер чанка и имя файла) и отправляет содержимое по raw TCP:
- используя собственные команды протокола сервера, на стороне сервера команды вроде:
- SETCHUNK
- SETNAME
- FLUSH
- END и др.
гарантируют, что данные получены правильно и сохранены в соответствии с определенным внутренним протоколом. Эта структурированная передача обеспечивает надежную обработку команд и гарантирует, что каждый чанк передается и записывается корректно. Протокол является "собственным" и не использует ни один из существующих "прикладных" протоколов.
Данная сетевая функциональность значительно расширяет возможности моего Greenplum-коннектора, делая его пригодным для распределенных систем, где данные необходимо дополнительно обрабатывать или сохранять в централизованном хранилище, как и для streaming операций.
Режимы работы.
Коннектор поддерживает три режима работы:
1). CSV_SGMT, данные извлекаются и записываются в CSV-файлы. Коннектор сохраняет данные на локальный диск, извлекая весь объем данных без разделения на чанки. Можно рассматривать это как "полное копирование таблицы-источника" из Greenplum в CSV.
2). STREAMING_LOCAL_DIR, данные сохраняются напрямую в локальную директорию. Режим отличается от первого тем, что уже используются чанки. Здесь, коннектор сохраняет данные в определенной директории, внутри которой данные таблицы разбиты на чанки. Это реализовано, поскольку некоторым разработчикам из моей команды, это было необходимо для задач по Spark structured streaming.
3). NETWORK_STREAMING, этот режим позволяет отправлять данные чанками, по сети, на удаленный сокет-сервер. Сокет-сервер можно воспринимать, как некий middleware-сервис. Также, это необходимо для моей задачи по подготовке custom data source для Spark v3. Уже, кстати, подготовлен сокет-клиент на Scala, поскольку мне необходимо поддерживать дистрибутив Spark v3.x.x
Неблокирующий I/O для повышения пропускной способности обработки данных.
Одним из ключевых решений в дизайне коннектора является использование неблокирующего I/O при работе с psql subprocessing.
Обычно, при запуске внешнего процесса, особенно такого, который работает с операциями, как обработка SQL-запросов, стандартный блокирующий ввод-вывод может повлияеть на приложение так, что придется уйти в длительное "ожидание". В условиях высокой пропускной способности подобные операции ожиданий станут быстро "узким местом".
Чтобы избежать этого, коннектор устанавливает для файловых дескрипторов режим неблокирующего ввода-вывода. Это достигается за счет изменения флагов файла (с использованием модулей, таких как "fcntl" в Python), так что чтение из stdout подпроцесса psql никогда не приводит к приостановке программы, если данные недоступны на момент времени:
Детали о Greenplum-коннекторе:
- он использует параллельные retrieve курсоры для процесса параллельного чтения с сегментов Greenplum.
- для параллельной прямой записи на сегменты используется "gpfdist". Об этом я не стал писать, поскольку это "стандарт", а параллельная запись с использованием PXF/gpfdist уже реализована/интегрировано во многих других коннекторах/фреймворках, да и написано про них достаточно много. Так что для меня, как автору было гораздо важнее отметить возможность "параллельного чтения".
- На данный момент я разрабатываю custom data source под Spark v3.x.x , который будет использовать данный коннектор со взаимодействием по сокет-серверу, о котором я уже упоминал в данной статье.
- Коннектор тестировался только с Greenplum v6, я использую "ванильную" версию GP. Многие текущие бизнес-заказчики не используют Greenplum v7 . Множество развернутых Greenplum-кластеров, над которыми ведется работа (и где реализованы DWH), основаны на GP v6. Возможно, в будущем будут работы и под v7, но сейчас бизнесу необходима стабильная поддержка v6.
- Уже разработаны:
(1) коннектор на Python.
(2) сокет-сервер с собственным протоколом через raw TCP на Python.
(3) сокет-клиент на Python.
(3) сокет-клиент на Scala (который будет использоваться с custom data source под Spark v3.x.x дистрибутивы). - Custom data source под Spark v3.x.x находится в разработке на данный момент.
- Уже проведен успешный тест на стороне бизнес-заказчика, и коннектор будет дорабатываться.
- Были проведены тесты с Cython, коннектор компилируется и работает, но в настоящее время, ввиду большого объема рабочих задач, эта активность приостановлена. Возможно, после релиза сustom data source под Spark v3.x.x - я вернусь к Cython. Я смог подготовить динамически-слинкованный бинарник, который работает. Но, именно на данном моменте я поставил паузу, в будущем планирую добиться полной статической линковки/сборки:
Идея использования подхода с psql subprocessing, изначально казалась "футуристичной", но что удивительно, подход работает довольно стабильно и быстро, именно поэтому он был оставлен в конечном решении, в том числе устроив бизнес-заказчика.
Я не могу опубликовать полный исходный код, так как это коммерческий продукт, но могу рассказать о некоторых его деталях, что и сделал в данном посте :)