Из всех функций активации, сложнее всего понять, каким образом ReLU добавляет нелинейность в нейронную сеть. Как такая простая функция, помогает нейронной сети чему-то научиться.
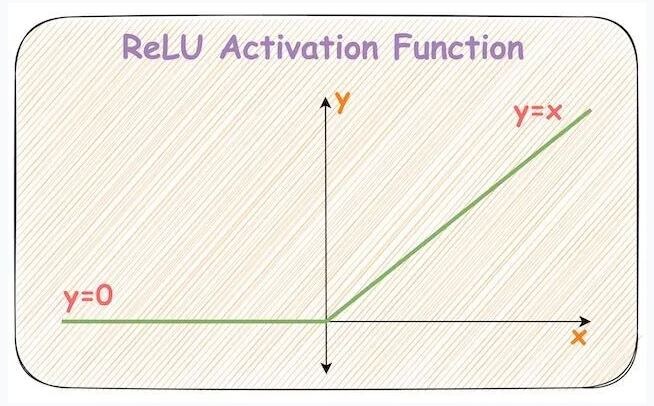
Путаница вполне очевидна, учитывая кажущуюся линейную форму, называть ее нелинейной функцией активации, как минимум странно.
Возникает очевидный вопрос: «Как ReLU позволяет нейронной сети улавливать нелинейность?»
Рассмотрим математическое выражение ReLU:
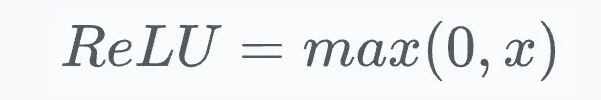
Приведенное выше уравнение можно переписать с параметром h следующим образом:
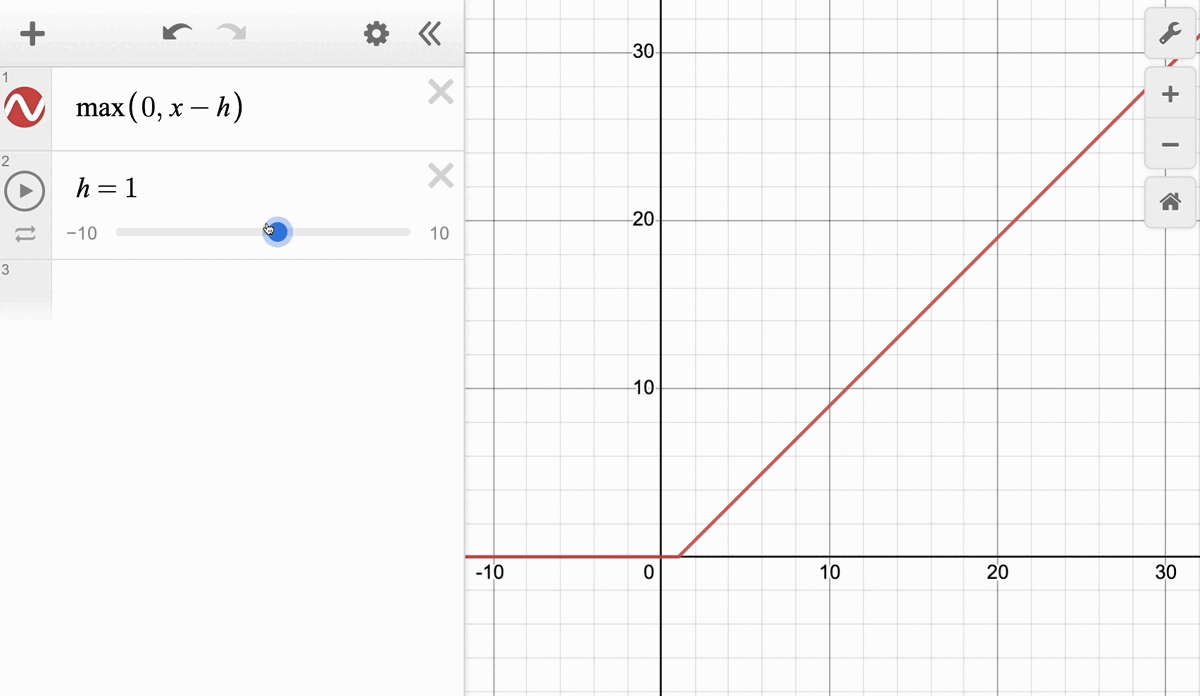
По сути, это та же функция ReLU, но со смещением.
Запомним данный факт, вернемся к нему чуть позже
Как работает нейрон
Рассмотрим какие операции происходят в нейроне:
- Во-первых, на нейрон поступают входные данные от предыдущего слоя (x₁, x₂, …, xₙ).
- Эти данные поэлементно умножается на веса (w₁, w₂, …, wₙ), после чего суммируются
- Затем добавляется смещение bias (каждый нейрон имеет своё собственное смещение)
- Результирующее значение передается на функцию активации (в данном случае ReLU) для получения выходного значения
Если внимательно присмотреться, то эти операции аналогичны функции
ReLU (x-h), которую обсуждали ранее:
Теперь давайте внимательно рассмотрим нейроны в последнем скрытом слое. На следующем рисунке показано, как нейроны этого слоя в совокупности вносят вклад в результирующее выходное значение:
По сути, конечный результат (Final Output) представляет собой взвешенную сумму по-разному смещенных ReLU, вычисленных на последнем скрытом слое.
Суммирование ReLU
Теперь, когда известен конечный результат работы сети, давайте построим график взвешенной суммы некоторых функций ReLU и посмотрим, как будет выглядеть общий график.
Начнем с двух:
На изображении выше видно, что сумма двух ReLU меняет наклон в одной точке.
Добавим третью функцию ReLU умноженную на константу:
На этот раз, суммирование трех функций ReLU формирует два изгиба.
Давайте добавим четвертую ReLU:
В этот раз, итоговая функций ReLU демонстрирует еще больше изгибов.
О чем это говорит?
Приведенные выше иллюстрации показывают, что, добавляя новые функций ReLU (со смещением и умноженные на некоторую константу), в результате можно получить любую форму кривой, как линейную, так и нелинейную.
Представленное выше уравнение не имеет ограничений по характеру кривой, может быть, как линейным, так и нелинейной.
Основная задача состоит в том, чтобы найти такие веса (w₁, w₂, …, wₙ), которые максимально точно описывают исходную функцию f(x).
Теоретически точность аппроксимации может быть фактически идеальной, если будем добавлять новые и новые ReLU, для каждого возможного значения х.
Пример для функции f(x) = x²
Допустим, необходимо получить аппроксимацию функции f(x) = x² для всех x ϵ [0;2]
Сначала аппроксимируем всего одной функцией ReLU:
Давайте добавим еще одну функцию ReLU(x) + ReLU(x−1):
Зеленая линия – имеет лучшее приближение, чем было ранее.
Давайте посмотрим, что будет если изменим веса (добавим 0,5 и 3):
Отлично - синяя линия начинает формировать контуры нашей параболы.
Главное, что здесь нужно понять, это то, что ReLU НИКОГДА не добавляет идеальную нелинейность в нейронную сеть. Кроме этого, как показано выше, настоящая сила ReLU раскрывается тогда, когда большое количество ReLU работают вместе.
Вот поэтому, наличие всего нескольких ReLU в сети может не дать удовлетворительных результатов, как показано на изображения ниже:
С увеличением числа ReLU, аппроксимация становится все лучше и лучше, а при 100 единицах ReLU, аппроксимация выглядит фактически нелинейной.
Именно по этим причинам ReLU называют - нелинейной функцией активации.
Дополнение: как выбрать функцию активации
Какую функцию активации следует использовать ReLu, Sigmoid, Than или собственную custom функцию ? На эти вопросы нельзя дать однозначного ответа. Стоит использовать ту функцию, с которой процесс обучения и сходимости будут точнее и быстрее.
Например, Sigmoid хорошо показывает себя в задачах классификации, а ReLu, как было показано выше, прекрасный аппроксиматор.
Если природа исследуемой функции непонятна, в этом случае можно начать с ReLu (требует меньше вычислительных мощностей), а далее при необходимости экспериментировать с другими функциями.