DeepSeek представила новую технологию обучения reasoning-моделей: Self-Principled Critique Tuning
Что произошло
Китайская исследовательская лаборатория DeepSeek AI, представила революционный метод для улучшения способностей рассуждения в моделях искусственного интеллекта. Новая техника названа Self-Principled Critique Tuning (SPCT), нацелена на создание более универсальных и масштабируемых моделей вознаграждения (reward models).
В чем суть новой технологии
SPCT объединяет два подхода для улучшения процесса "рассуждения" моделей:
1. Генеративное моделирование вознаграждения (GRM) - вместо выдачи простой оценки, модель генерирует текстовые критические замечания, которые затем преобразуются в оценки
2. Самопринципиальная настройка критики (SPCT) - модель учится самостоятельно формулировать принципы оценки и критерии на основе запроса и ответов
Исследователи DeepSeek выявили четыре ключевые проблемы при создании универсальных моделей вознаграждения:
- Гибкость ввода: Модель должна обрабатывать различные типы входных данных и оценивать один или несколько ответов одновременно
- Точность: Необходимо генерировать точные сигналы вознаграждения в разных областях, где критерии сложны, а "правильный ответ" часто недоступен
- Масштабируемость во время вывода: Модель должна выдавать более качественные результаты при выделении большего количества вычислительных ресурсов
- Обучение масштабируемому поведению: Для эффективного масштабирования моделям нужно усваивать поведение, позволяющее улучшать производительность при увеличении вычислений
Как работает SPCT
Технология включает два основных этапа:
1. Отбраковочная тонкая настройка: На этом этапе модель обучается генерировать принципы и критические замечания в правильном формате. Примеры принимаются только если предсказанное вознаграждение соответствует эталону.
2. RL на основе правил: Модель дополнительно настраивается через обучение с подкреплением. Сигналы вознаграждения рассчитываются на основе простых правил точности.
Для решения проблемы масштабируемости во время вывода исследователи запускают модель несколько раз для одного и того же запроса, генерируя разные наборы принципов и критических замечаний. Окончательная оценка определяется голосованием (агрегацией оценок отдельных выполнений).
Дополнительно была введена мета-модель вознаграждения — отдельная, легковесная модель, обученная специально предсказывать, приведет ли принцип/критика, сгенерированные основной моделью, к правильной итоговой оценке. Она фильтрует низкокачественные суждения перед финальным голосованием.
Практическое применение
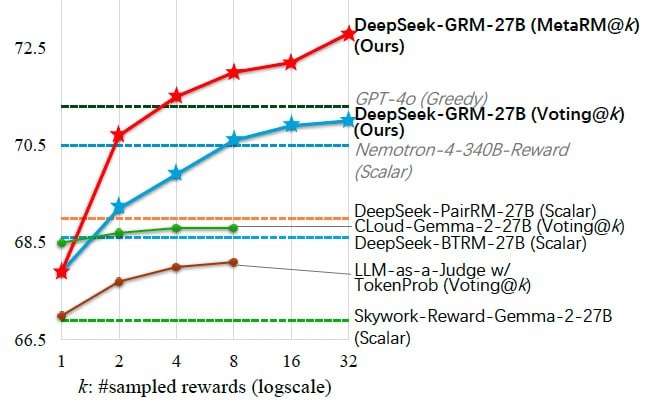
Исследователи применили SPCT к модели Gemma-2-27B от Google, создав DeepSeek-GRM-27B. Они протестировали её против нескольких сильных базовых моделей вознаграждения и публичных моделей (включая GPT-4o и Nemotron-4-340B-Reward) на нескольких тестах.
Результаты показали, что:
- DeepSeek-GRM-27B превзошла базовые методы, обученные на тех же данных
- При увеличении числа выполнений на этапе вывода производительность DeepSeek-GRM-27B значительно возрастала, превосходя даже гораздо более крупные модели
- Метамодель дополнительно улучшила масштабирование, достигая лучших результатов путем фильтрации суждений
*комментарий к изобретению в посте
Производительность DeepSeek-GRM (обученной с SPCT) продолжает улучшаться с масштабированием времени вывода.
Влияние на будущие модели
Эта технология имеет важное значение для развития моделей рассуждения. Благодаря ей можно создавать более универсальные AI-системы, способные:
- Адаптироваться к динамически меняющимся условиям
- Лучше работать с творческими задачами и заданиями без четких критериев оценки
- Улучшать свою производительность при выделении дополнительных ресурсов
Что дальше
Хотя компания официально не комментировала сроки выпуска R2 (по слухам в мае 2025), новая технология SPCT, вероятно, будет играть важную роль в архитектуре этой модели, потенциально позволяя ей превзойти текущие стандарты в области моделей рассуждения.