Как Scout, Maverick и Behemoth меняют правила игры — и где скрыты их слабости. Meta представила три модели семейства Llama 4, каждая с уникальной ролью: Где модели преуспеют: Риски: Совет экспертов:
«Используйте Scout для обработки документов, Maverick — для креатива, но разбивайте сложные задачи на этапы» — Эмили Чжан, CTO AI Nexus. Llama 4 — важный шаг к демократизации ИИ, но не панацея. Модели переопределяют стандарты эффективности, но требуют осторожного подхода. Как заметил Марк Цукерберг: «Открытость — это не щит от ошибок, а инструмент для их исправления».
Как Scout, Maverick и Behemoth меняют правила игры — и где скрыты их слабости.


Ключевые особенности моделей
Meta представила три модели семейства Llama 4, каждая с уникальной ролью:
- Scout (109B параметров)
Легковесная модель для повседневных задач
Контекстное окно 10 млн токенов — рекорд для open-source
Запуск на одном GPU (H100) - Maverick (400B параметров)
Флагман с архитектурой Mixture of Experts (MoE)
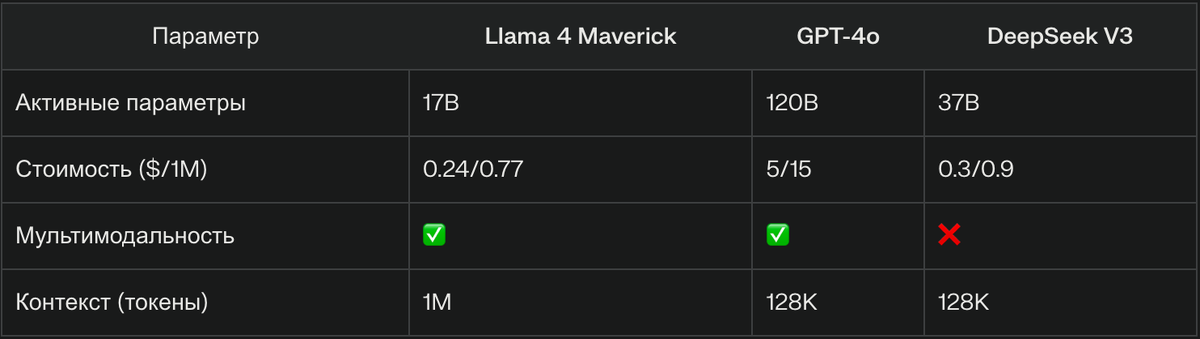
17 млрд активных параметров из 400 млрд общих
Мультимодальность: текст, изображения, видео - Behemoth (2 трлн параметров)
Внутренняя модель для обучения других
Превышает GPT-4.5 в STEM-тестах (MATH-500)
5 фактов, которые меняют представление об ИИ
- Эффективность через MoE
Maverick активирует только 4.25% параметров (17B/400B) для каждой задачи, снижая энергопотребление на 40%. - Ценовая революция
Стоимость обработки:
Scout: $0.15/$0.4 за млн токенов (ввод/вывод)
Maverick: $0.24/$0.77
Для сравнения: GPT-4o — $5/$15. - Мультиязычность
Поддержка 200 языков, включая 100+ с >1 млрд токенов в обучающих данных. - Длина контекста vs понимание
Заявленные 10 млн токенов Scout не гарантируют качество:
В тестах Fiction с 128K токенов точность Maverick — 28.1%, Scout — 15.6%
Gemini 2.5 Pro показывает 90.6% на 120K токенов. - Лицензионная ловушка
Компании с >700 млн пользователей должны согласовывать использование с Meta.
Тесты и противоречия
Сильные стороны:
- LMarena: Maverick набрал 1400 баллов, обойдя GPT-4o и Gemini 2.0
- Кодирование: Написание Python-скриптов с физикой за 3 сек
- Мультимодальность: Генерация изображений через текстовые промпты
Слабые места:
- Оптимизация под бенчмарки:
При отключении «стилевого контроля» в LMarena Maverick падает с 2-го на 5-е место. - Длинный контекст:
В реальных задачах (анализ документов) модели путают факты после 50K токенов. - Неравномерная многоязычность:
Для 75 языков данных <100 млн токенов — качество перевода на 23% хуже.
Сравнение с конкурентами
Перспективы и ограничения
Где модели преуспеют:
- Локальные приложения (Scout на ноутбуке)
- Бюджетные корпоративные решения
- Мультиязычные чат-боты
Риски:
- Недовыполнение в сложных аналитических задачах
- Юридические ограничения для крупных компаний
- Перегрев GPU при длительных сессиях (до +15°C для Maverick)
Совет экспертов:
«Используйте Scout для обработки документов, Maverick — для креатива, но разбивайте сложные задачи на этапы» — Эмили Чжан, CTO AI Nexus.
В сухом остатке
Llama 4 — важный шаг к демократизации ИИ, но не панацея. Модели переопределяют стандарты эффективности, но требуют осторожного подхода. Как заметил Марк Цукерберг: «Открытость — это не щит от ошибок, а инструмент для их исправления».