Поисковый робот (crawler) — это программа, которая сканирует сайты и собирает информацию для индексации. Роботы анализируют тексты, изображения, ссылки и другие элементы страницы.
Чтобы улучшить взаимодействие с роботами, используйте файл robots.txt для управления доступом и регулярно обновляйте контент. Это поможет SEO сайту быстрее появляться в поисковой выдаче.
Поисковый робот (краулер, паук) — это автоматизированная программа поисковых систем, которая:
- Сканирует веб-страницы по ссылкам
- Анализирует контент и структуру
- Передает данные для индексации
- Проверяет обновления контента
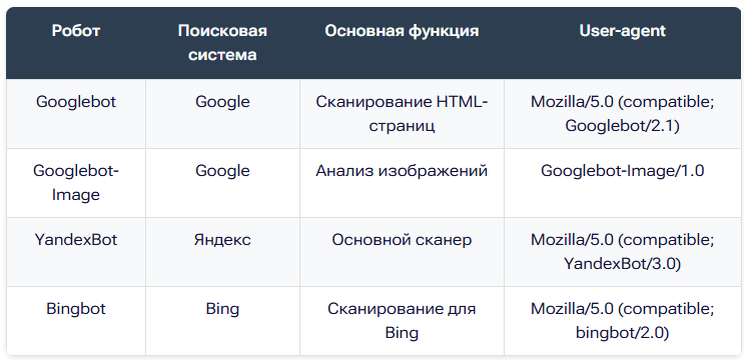
Основные типы поисковых роботов
Как управлять поведением роботов?
Файл robots.txt (основные директивы)
User-agent: *
Allow: /public/
Disallow: /private/
Crawl-delay: 2
Sitemap: https://example.com/sitemap.xml
Мета-теги в HTML
<meta name=»robots» content=»noindex, nofollow»> <!— Запрет индексации —>
<meta name=»googlebot» content=»notranslate»> <!— Отключение перевода —>
HTTP-заголовки
X-Robots-Tag: noindex, nofollow
5 стратегий оптимизации работы с краулерами
Контроль сканирования
- Оптимальный crawl budget: 200-500 страниц/день для средних сайтов
- Приоритезация важных страниц через внутренние ссылки
- Исключение дублей (параметры, сессии)
Ускорение индексации

Анализ активности роботов
- Google Search Console → Статистика сканирования
- Яндекс.Вебмастер → Инструменты → Анализ robots.txt
- Логи сервера (прямой мониторинг)
Оптимизация структуры
- Глубина вложенности ≤3 клика от главной
- Хлебные крошки с микроразметкой
- Канонические URL для дублей
Поддержка новых технологий
- Адаптация под JavaScript-рендеринг
- Оптимизация для mobile-first индексации
- Поддержка structured data
Частые проблемы и решения
Инструменты для мониторинга активности роботов
Google Search Console → Статистика сканирования
Яндекс.Вебмастер → Инструменты → Анализ robots.txt
Анализ логов сервера:
- Screaming Frog Log Analyzer
- ELK Stack (для больших сайтов)
Сервисы мониторинга:
- Botify
- OnCrawl
Профессиональный совет: Для крупных сайтов (10 000+ страниц) настройте приоритетное сканирование через:
- Указание важных разделов в sitemap
- Увеличение внутренних ссылок на ключевые страницы
- Настройку crawl-delay для редко обновляемых разделов
Регулярно проверяйте неиндексированные страницы в вебмастерах и устраняйте причины исключения.
_________________________________
Поисковый робот (crawler) - оригинал термина с сайта маркетингового агентства LEadBRO. Термин подготовлен при участии SEO-эксперта, руководителя отдела продвижения «LEadBRO» Евгения Матвийчука.
Возникли вопросы или хотите заказать услугу в "LEadBRO"?
Свяжитесь с нами, мы ответим на все ваши вопросы.
Контактные данные:
- Телефон: +7 (343) 364-42-23
- Email: sale@lead-bro.ru