Всем привет, меня зовут Андрей, это снова я!
Продолжим говорить про то, как Эксель помогает составлять кроссворды.
Конкретно в этой статье будет рассказ про один из способов того, как можно в кроссворд вложить "изюминку", чтобы этот кроссворд отличался от других, чтобы у него была какая-то особенность.
Можно, например, сделать так, чтобы все слова нашего кроссворда начинались с буквы "а". Для этого с помощью фильтра в столбце "I" выберем букву "а".
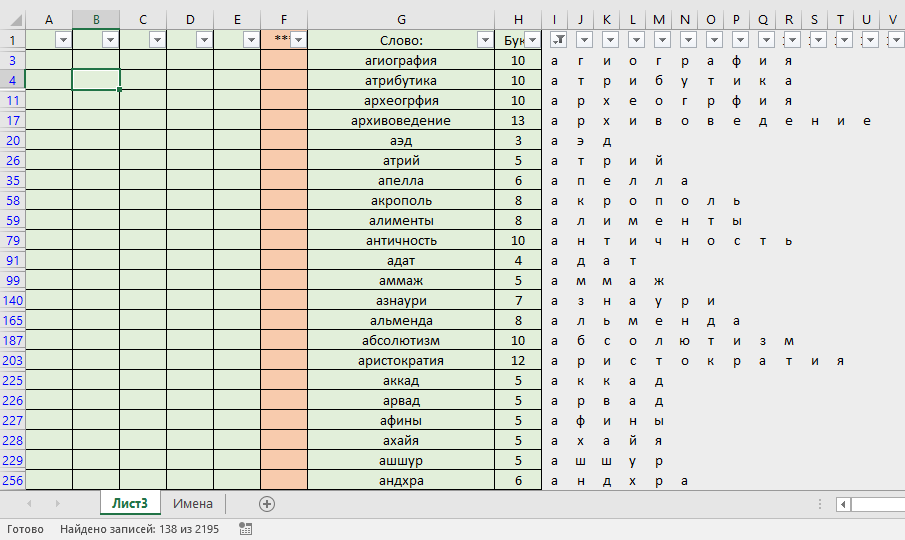
В моей базе данных пока только 2195 слов, но из них начинаются на букву "а" только 138 слов. Даже если не все слова, которые удовлетворяют нужному критерию будут использованы в кроссворде (а в нашем случае этот критерий: "слово должно начинаться на букву 'а'"), все равно, чем больше слов будет отобрано на первых этапах, тем лучше.
Поэтому можно изменить сам критерий отбора слов. Например, можно выбрать не те слова, что начинаются на букву "а", но найти такую первую букву, на которую у нас начинается максимальное количество слов в нашей базе данных.
Можно продолжить заполнять тот лист Эксель, которому мы уже раньше присваивали Имя "Имена". В нем мы и будем вести разный статистический учет. В том числе, среди прочих параметров, будем подсчитывать, сколько слов начинается на букву "а", сколько - на букву "б", и так далее.
Перейдем на этот лист и добавим там для начала каждую букву:

Кто-то может возразить, что на буквы "ь" или "ъ" в русском языке не начинаются слова. Да, это так. Но в будущем мы эту же таблицу (этот же заголовок) будем использовать и для других задач тоже. Например, можно будет аналогичным образом выделять вторую, третью букву, или даже последнюю, независимо от количества букв в слове.
Затем вернемся на тот лист, где у нас расположены слова. Выделим тот столбец, что содержит первые буквы (а мы знаем из первого рисунка, что это столбец I).
Присвоим имя этому столбцу: Первые_буквы
Можно присвоить этому же столбцу и второе имя, например Б_1
Снова вернемся на второй лист (Имена), теперь можно подсчитать, какая буква в нашей базе данных чаще всего стоит на первом месте (с какой буквы чаще всего начинаются слова в нашей базе).
Но вначале продолжим заполнять лист "Имена". Мы же еще не высчитали, какая именно буква самая популярная среди всех первых букв в нашей базе данных.
В ячейке А3 "1е" означает, что мы здесь подсчитываем все первые буквы в каждом слове; цифры показывают, какая из бкв сколько раз бывает именно первой в нашем диапазоне данных; B3...AG3 используют одну и ту же формулу:
=СЧЁТЕСЛИ(Б_1; B$2)
Мы же уже заранее определили, что Б_1 - это и есть тот столбец, что содержит все первые буквы в каждом из слов.
Очевидно, что больше всего слов начинаются на букву "к". Но надо сделать так, чтобы эта буква выявлялась автоматически. Добавим несколько ячеек:
Вторая строка эксель-это просто заголовки.
AI3 - это число 256. Это значит, что та буква, которая на первом месте находится чаще других, встречается в нашей базе данных 256 раз.
AJ3 означает, что чаще всего встречающаяся буква будет под номером 11, а AK3 означает, что речь идет о букве к.
Если бы было несколько одинаковых значений (если бы несколько букв занимало лидирующие позиции), то в этих ячейках мы бы получили ту букву, которая ближе к началу алфавита.
А вот какие были использованы формулы в этих ячейках:
Итак, AI находит максимум, AJ показывает, какая именно позиция по номеру у этой буквы, а AK показывает, какая именно буква нам нужна.
И теперь мы можем этой ячейке (AK3) присвоить конкретное имя (например, maksim01), и тогда можно будет быстро увидеть нужную нам букву, находясь в любом листе Эксель.
Конечно же, при другой базе данных или при кадом изменении в основной базе данных, содержащей слова для кроссворда, мы будем сталкиваться и с изменениями в этой отчетной таблице результатов.
Например. вернемся к тому листу, что содержит основные слова.
В левую верхнюю ячейку (А1) введем формулу:
=maksim01
И мы увидим результат - букву "к". В ячейке А1 эксель.
Вот фрагмент листа Эксель, содержащий эту букву "к".