Алгоритм Skip-Gram является одним из составляющих модели Word2Vec. Он использует нейронную сеть для прогнозирования слова, находящегося в ближайшем окружении данного слова. Алгоритм представляет слова в виде векторов и использует их для предсказания слова в контексте. Он также использует искусственную нейронную сеть для обучения и улучшения своей точности. Skip-Gram использует алгоритм обратного распространения ошибки (Backpropagation), чтобы достичь максимальной точности.
Как работает алгоритм Skip-Gram?
Ты задумывался, в какой момент приходит осознание, как именно использовать тот или иной алгоритм на практике? Правильный ответ: когда ты понимаешь его внутреннее устройство. Чтобы разобраться в Word2Vec необходимо в первую очередь понять алгоритмы, на которых она работает. В первую очередь разберемся в работе Skip-Gram.
Алгоритм Skip-Gram является составляющей частью модели Word2Vec, который использует нейронную сеть для машинного обучения на корпусе текста.
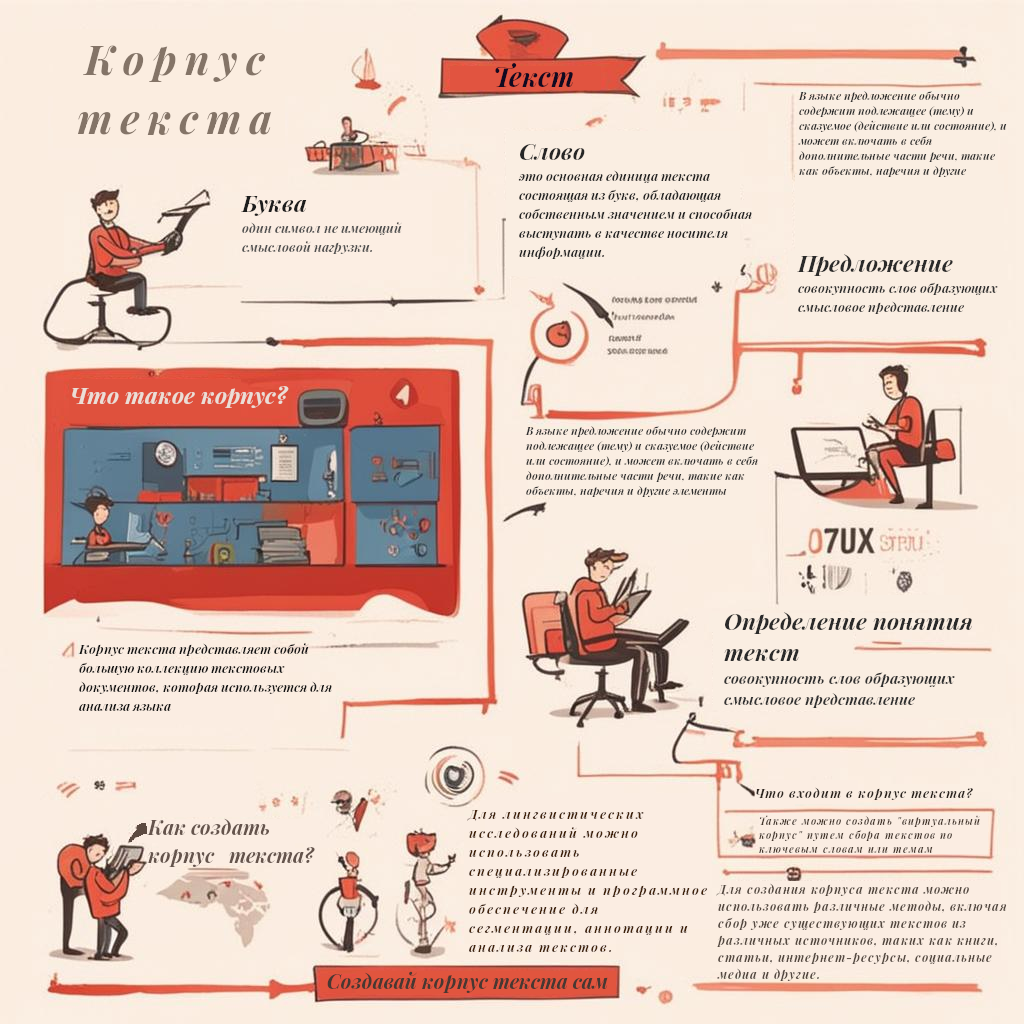
Чтобы что-то обсуждать, давай определимся с термином корпус текста. Давай начнем объяснение с самой маленькой единицы и будем двигаться по нарастанию:
- Буква - это один символ;
- Слово - совокупность букв;
- Предложение - совокупность слов образующих смысловое представление;
- Текст - это последовательность слов или символов, которая передает информацию, идеи или эмоции;
- Корпус текста - это набор текстов, но лучше посмотрите подготовленную инфографику.
Алгоритм Skip-Gram представляет слова в виде векторов, используя контекстуальную информацию для предсказания слов по данным корпусам текста.
Skip-Gram основан на схеме скипграммы, которая использует контекстную информацию для предсказания целевого слова по данным корпусам текста. В алгоритме Skip-Gram контекст используется для предсказания целевого слова
Скипграмма составляется из пар слов, представляющих собой цепочку из трех слов, образующих предложение. Первое слово в паре является контекстом следующего слова. Например, для данного входного текста «У меня есть любимый кот» скипграмма будет выглядеть так:
[ У, меня, есть, любимый, кот, меня_есть, есть_любимый, любимый_кот ].
Таким образом, скипграмма представляет собой последовательность пар слов, которые образуют предложение.
Поэтому, алгоритм Skip-Gram использует контекстную информацию о каждом слове для предсказания следующего слова в предложении. Визуально это выглядит, как работа Т9.
Он обучается, используя набор пар слов. Первое слово представляет центральное слово, а второе представляет слово в контексте. Он предсказывает контекстное слово по центральному слову, а затем использует модель для предсказания следующего слова.
Алгоритм Skip-Gram можно представить следующим образом: дана последовательность слов (например, предложение), и алгоритм проверяет все слова и ищет те, которые находятся непосредственно слева и справа от данного слова. Затем алгоритм предсказывает данное слово, используя окружающие его слова. Таким образом, при использовании алгоритма Skip-Gram предсказывается каждое слово из последовательности, используя окружающие слова.
Но перед этим нужно обучить данный алгоритм посредством подготовленного корпуса текста. Когда вы обучаете, то получается вот такая карта слов.
Если убрать все пунктирные линии на рисунке, то может показаться, что это просто куча разных хаотично расположенных слов. Но это не так. Давайте оставим только красную пунктирную линию.
Если обратить внимание на разделение вертикальной линией, то справа остались все слова, которые описывают живые существа, а слева неживые. А обратив внимание на горизонтальную пунктирную линию вы заметите, что выделена нижняя строка (вектор) в котором находятся ближайшие по смыслу слова.
Так они распределяются при обучении skip-gram. Но важно понимать, что алгоритм не умеет определять смыслоёмкость слов, а распределяет их по частоте использования в корпусе текста, который вы подаёте на вход при обучении.
Таким образом, если ваш корпус текста будет содержать разрозненные наборы текстов, в которых не прослеживается частотность слов, то такие четкие векторы, которые представлены на схеме вряд ли будут появляться.
Давайте закрепим:
- вектор является горизонтальной строкой образующей соседние слова, которые по частотности и весу были близки в обучающем корпусе текста;
- разделение по горизонтали происходит в бинарном формате и масштабируется, т.е. живое и неживое, мужчина и женщина, петух и курица.
Касательно вопроса о слове масштабируется мы вернем на наш график зеленую пунктирную линию. Скажите, что она разделяет?
Думаю вы заметили, что в правой части разделение произошло по мужскому и женскому роду. Давайте вернем синюю пунктирную линию и посмотрим, а что же там разделяется.
Разделение произошло по оборудованию, которое используется в серверных комнатах или в офисе. И такое масштабирование при разделении по вертикали - позволяют сформировать контекстный вектор по горизонтали.
Конечно на схеме представлена идеальная модель и никакой корпус текста не сможет позволить так точно все распределить. Но это и ненужно. Важно сохранять контекст, который использовался в обычном тексте, чтобы предсказание или прогноз следующего слова был более подходящим.
Другими словами чем лучше ваш корпус текста, тем лучше предсказание следующего слова.
В дальнейших материалах будем рассматривать другие составляющие модели Word2Vec, поэтому подписывайся на канал, чтобы ничего не пропускать.