Всем привет, меня зовут Андрей, это снова я!
Эксель может быть очень хорошим помощником как для составления, так и для отгадывания разных кроссвордов. Здесь есть огромное поле для творчества и креативности. Но обо всем по порядку, конкретно в этой статье будет рассказано только о подготовке файла и о работе с фильтрами (с фильтрацией данных для составления кроссворда).
Но начнем с самого начала. Создадим новый файл в Эксель, желательно с поддержкой макросов, и начнем вводить в этот файл различные слова вот каким образом:
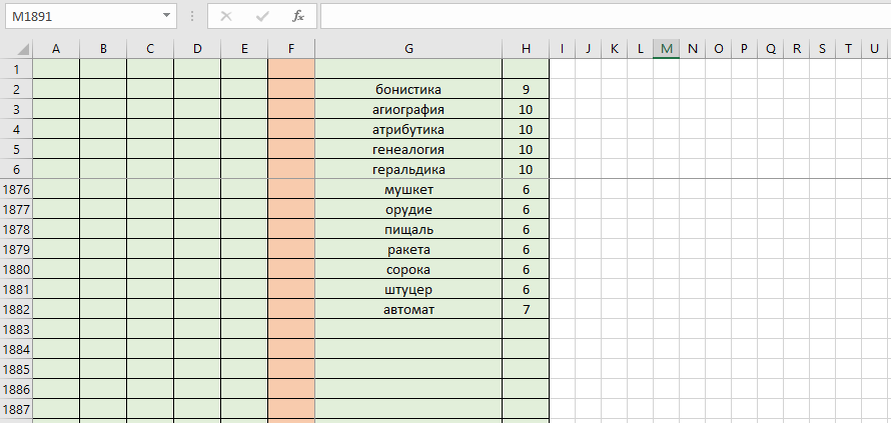
Левые столбцы от A до E можно использовать для какой-то служебной информации. Например, если мы берем слова из какой-то книги или словаря (справочника), то в эти столбцы можно добавить информацию о том, на какую тему (подтему) это слово, на какой оно странице, и т.д. Например, если этот файл мы будем использовать не для отгадывания чужих кроссвордов, а для составления своих, то в каком-то из этих столбцов можно разместить информацию, в каком именно своем кроссворде мы хотим использовать это слово, в каком издании, или какого числа этот кроссворд опубликован. Это пригодится, например, для того, чтобы одни и те же слова слишком часто не повторялись. Хотя, с другой стороны, если есть желание какое-то одно слово использовать во всех или почти всех своих кроссвордах, как, например, режиссер Данелия почти во все свои фильмы включал песню "На речке" (эта песня звучала там целиком или частично), то и это какое-то специальное слово тоже можно снабдить каким-то комментарием.
В приведенном фрагменте листа мы видим, что применено закрепление областей. Это позволит постоянно видеть верхние строчки и левые столбцы.
Первая строка Эксель у нас пока пустая, ее в будущем можно будет использовать как "шапку", добавить заголовки столбцов.
Столбец F мы будем использовать для тех случаев, когда нам попадется какое-то подозрительное слово. Чаще всего там будут использованы такие слова, которые вряд ли существуют на самом деле, но их можно встретить при отгадывании чужих кроссвордов, а при составлении своих кроссвордов эти слова лучше не использовать. Типичный пример - это слово "карукота":
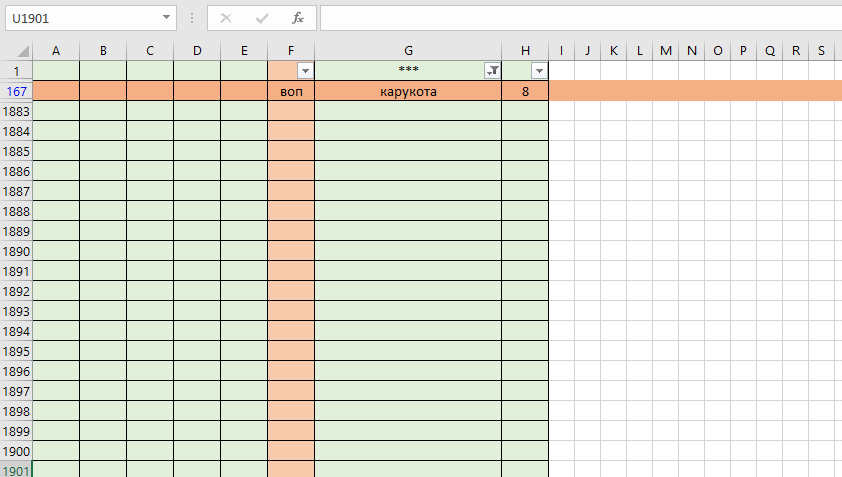
Здесь мы заполнили ячейку G1, а затем применили фильтрацию данных. Теперь вся наша основная информация содержится во всех строках, начиная со второй, а первая строка понадобится для заголовка и для фильтрации.
О фильтре. Этот инструмент Эксель можно найти здесь:
Прежде, чем нажать на кнопку фильтрации, нужно выбрать диапазон ячеек с исходными данными, которые необходимо фильтровать. Чаще всего выделяют несколько столбцов целиком, те столбцы, в которых содержится информация с нужными данными. Если есть задача выбирать столбцы не целиком, а только какую-то их часть, тогда нужно заранее выделить именно тот диапазон, в котором содержатся нужные данные (то есть иногда можно выделять не все строки нужных столбцов, если в остальных строках есть другая информация, и нет необходимости в фильтрации).
Но вернемся к предыдущему рисунку, где мы уже с помощью фильтра выбрали строку 167 Эксель.
Итак, ячейка F167 содержит информацию "воп", это сокращение от слова "вопрос". Сам знак вопроса (?) лучше не применять, так как этот знак часто используется в эксель в служебных целях, например, при поиске информации (конкретно в поле "Поиск", что находится чуть ниже текстовых фильтров) знаком вопрос можно заменить один (любой) символ:
Итак, фильтр "?арукота" означает одно: первая буква нам не известна, но мы точно знаем, что перед фразой "арукота" имеется ровно одна буква (правильнее сказать, один символ, а не одна буква, но, поскольку в нашем конкретном случае в столбце G есть только слова и ничего более, то этим символом может быть только буква).
Конечно же, слово "карукота" можно было бы найти и другим способом, например, при поиске в столбце F можно выделить все непустые данные (если версия Эксель позволяет это сделать), или конкретно кодовое "слово" - "воп":
Но я просто хотел рассказать о том, что знак вопроса можно использовать как замену одной буквы. Кстати, аналогично, звездочка заменяет одну, ноль, или несколько букв сразу.
Можно, кстати, одновременно использовать и звездочку, и знак вопроса, например:
Этот фильтр "*кот?" можно понимать так: перед сочетанием букв "кот" в нужном нам слове есть:
- несколько букв (или даже совсем 0 [ноль] букв) - это из-за первой звездочки, которая символизирует любое количество букв, он нуля букв до нескольких букв;
- затем есть сочетание букв "кот" (эти буквы остаются "как есть", то есть именно в таком сочетании эти буквы должны присутствовать в искомом слове),
- после этого сочетания букв есть ровно одна буква - это знак вопроса (?), который символизирует ровно одну букву.
Этим требованиям (при нашей базе данных) соответствует только одно слово, и это слово "карукота".
В принципе, подобных вариантов может быть несколько. Можно использовать одновременно любое сочетание, состоящее из звездочек и знаков вопроса. Единственное, что не имеет смысла при такой комбинации, это соединение двух звездочек подряд (потому что результат от одной звездочки будет точно такой же, как и от двух звездочек подряд; а вот от двух знаков вопроса подряд будет другой эффект: один знак вопроса символизирует только ровно один символ, а два подряд - это уже ровно два символа). Но те же две звездочки, разделенные буквами и/или знаком/знаками вопроса, вполне могут существовать, например:
Здесь мы применили фильтр "*а*а*", но его смысл прост: найти все слова, в которых есть минимум две буквы "а". Как мы видим, не все нужные нам слова уместились в отведенном для этого месте, поэтому автоматически появляются полосы прокрутки. Горизонтальная полоса означает, что какая-то информация не уместилась в видимую часть строки (например, "Выделить все результаты..." или "Добавить выделенный фрагмент"). Вертикальная полоса прокрутки при этом означает, что все слова, которые содержат минимум две буква "а", не умещаются в то поле, которое предназначено для отображения, таких слов оказалось слишком много.
Но можно применить и другие сочетания вопросов и звездочек, например:
?ар*т?
Итак, при применении фильтра "?ар*т? мы получим всего 2 слова, которые отсеялись после данной фильтрации. Это слова "барту" и "карукота". Было бы в нашей базе больше слов, тогда, возможно, при применении этого же фильтра мы могли бы получить и другой результат. Кстати, наличие среди отфильтрованных слов слова "барту" только подтверждает тот факт, что звездочка (*) может иногда означать, что вместо нее может быть ровно 0 (ноль) букв или других символов. Действительно, в слове "барту" между буквами "р" и "т" никаких других букв нет, а в "фильтре" между этими буквами есть звездочка.
Кстати, фильтр "?ар*т? означает следующее:
- первая буква может быть любой (это первый знак вопроса);
- вторая буква "а", третья буква "р" (это сочетание "ар" после первого знака вопроса);
- после "ар" могут быть несколько любых букв, их количество не известно, но известно, что их может быть любое число, больше или равное нулю (это звездочка * );
- предпоследняя буква в искомом слове - это буква "т" (это буква "т" перед знаком вопроса);
- последняя буква в искомом слове может быть любой, известно только то, что после предпоследней буквы "т" в нужном нам слове будет ровно одна буква (любая, но ровно одна) - это последний знак вопроса.
А теперь хотелось бы несколько слов сказать о "специальных символах, а именно:
- звездочка (*);
- знак вопроса (?);
- тильда (~).
Как использовать звездочку и вопрос в служебных целях при фильтрации данных, я достаточно подробно рассказал в данной статье. Но иногда бывает итак, что нужны именно эти символы. Приведем пример. Допустим, что у нас есть несколько ячеек, содержащих одиночные символы, включая именно эти:
Допустим, что нужно выбрать все данные, которые в столбце F содержат именно знак вопроса. Есть как минимум два способа добиться этого результата.
Первый способ простой и очевидный. Найти все элементы данного столбца, которые доступны на данном этапе сортировки, убрать галочку с пункта "Выделить все", но добавить галочку на пункт, который содержит знак вопроса:
Второй пункт аналогичен первому по своему результату. В графе "поиск" ввести сначала знак ~ (тильду), а потом тут же, следом за ней, знак вопроса:
Кстати, если бы мы ввели только знак вопроса (?), но без тильды (~), то мы бы выбрали все те ячейки столбца F, которые содержат ровно один символ, а именно:
Аналогичным образом (прибавлением тильды слева) нужно искать не только знаки вопроса (?), но и звездочки (*) и сами одиночные тильды (~). Вводя в графе "Поиск" сразу две тильды, мы найдем те ячейки, что содержат только одиночную тильду (~).
Если бы мы в той же ситуации ввели только одиночную тильду (~), то мы бы получили ответ, что результаты не найдены:
Аналогичным образом можно искать данные, которые состоят только из одной звездочки. Если в графе "Поиск" ввести только одну звездочку, то это будет все равно, что мы вообще не фильтровали данные, ведь одиночная звездочка - это любое количество символов:
А вот для поиска тех ячеек, что содержат только одну звездочку (*) в графе "Поиск" нужно ввести не одиночную звездочку, а тильду и звездочку:
Конечно же, для составления и отгадывания кроссвордов эти одиночные символы, что мы вводили в столбце F, не нужны. Мы их здесь вводили только для того, чтобы показать основные возможности фильтрации данных в Эксель.
В реальности же могут случаться и вот какие ситуации: информация в ячейке может состоять не из одного символа и даже не из одного слова, но частью этой информации может быть любой из тех символов, что мы здесь рассматривали. Например, в какой-то ячейке могут быть данные "Петров?" и "Сидоров?", а необходимо с помощью фильтра выбрать все ячейки, что содержат знак вопроса. Если при этом точно известно, что сам знак вопроса во всех случаях будет самом конце каждой ячейки, то можно применить следующий фильтр в графе "Поиск":
*~?
Здесь тильда с вопросом (~?) будет означать, что последний символ - это знак вопроса, но перед ним может быть сколько угодно символов. Кстати, после такой "маски" мы отфильтруем даже и те ячейки, которые содержат только одиночные знаки вопроса, ведь в этой статье уже говорилось, что под звездочкой (*) могут скрываться любые сочетания букв, а также и отсутствие любых букв.
Приведем пример. Пусть у нас есть реально такая база данных, что содержит и несколько простых фамилий, и несколько таких фамилий, после которых есть знак вопроса.
Если стоит задача: с помощью фильтра выбрать только те данные, что содержат символ "?" в конце, то фильтр будет следующим:
*~?
А вот и результат работы этого фильтра:
Итак, мы видим, что результат работы этого фильтра - это все данные, которые содержат знак вопроса в конце, то есть оканчиваются знаком вопроса.
Аналогичным образом можно компоновать и другие символы и их тандемы Здесь есть очень много вариантов, главное иметь ввиду следующее:
- ~* воспринимается как одно целое, означает "один символ, но не любой, а только звездочка";
- ~~ воспринимается как одно целое, означает "один символ, но не любой, а только тильда";
- ~? воспринимается как одно целое, означает "один символ, но не любой, а только знак вопроса";
- * просто звездочка (*) означает "любое количество символов либо отсутствие символов вообще";
- ? просто вопрос (?) означает "один символ, любой".
Приведем конкретный пример. Пусть в базе данных появилось значение, которое начинается со звездочки и заканчивается знаком вопроса (строка 10 Эксель):
Допустим, что с помощью фильтра нужно найти ту строку, что начинается с символа звездочки, а заканчивается знаком вопроса.
Вот какой нужно применить фильтр:
~**~?
Итак, хотя обычно две звездочки подряд означают то же, что и одна звездочка, то есть любое количество символов либо отсутствие символов, но в данном случае ситуация другая, потому что наша левая звездочка не одна, а часть тандема (потому что расположена сразу за тильдой), а поэтому тандем тильды и звездочки надо понимать так: один символ, но не любой, а именно звездочка. А вот вторая звездочка - она уже будет означать любое количество символов (либо отсутствие символов вообще). А правее второй звездочки мы видим снова тандем, и он означает: "один символ, и не любой, а только знак вопроса". А результат действия всего этого фильтра - одна строка, которая содержит информацию "*Иванов?".
Возможности фильтрации данных немного больше, чем те, о которых рассказано в данной статье. Если сказать вкратце, то есть еще и фильтры по цвету, и текстовые фильтры... Но эта статья и так получилась достаточно длинной, так что добро пожаловать на мой канал, подписывайтесь и ждите новых статей, там будет много интересного, в том числе и подробности про другие возможности фильтрации данных.
Приглашаю всех любителей и составлять, и решать кроссворды, на мой канал! Создавайте свою базу со словами по тем принципам, что изложены в данной статье, подписывайтесь на мой канал, в будущем там будут появляться и другие статьи, рассказывающие про составление или отгадывание кроссвордов с помощью Эксель.
Напоследок скажу несколько слов о слове "карукота", а также о всех таких словах, которые лучше использовать только при решении чужих кроссвордов, но не при составлении своих. Есть несколько разных авторитетных энциклопедий и энциклопедических словарей. Если эти издания написаны знаменитыми авторами (например, Ожегов, Ушаков, Даль и т.д.), то этим изданиям можно доверять. Но в последнее время появилось несколько словарей-справочников для решения кроссвордов, которые содержат не только вполне нормальные слова, но иногда содержат и такие слова, которых нет ни у Даля, ни у Ожегова, ни в энциклопедических словарях как России, так и СССР. Одним из этих слов является "карукота". Даже иногда на просторах интернета можно встретить вот какой вопрос:
- В интернете часто встречается слово "карукота", но его можно увидеть на тех сайтах, которые созданы якобы в помощь кроссвордистам. На этих сайтах карукота - английская мера площади. Но этого слова я не встречал ни в словарях, ни в энциклопедиях, ни в википедии. Подскажите, пожалуйста, может быть там одна или несколько опечаток?
Ответ на этот вопрос найти не получится, да и не надо искать его. В любом случае, встретив подозрительное слово, его можно занести в базу данных, но обязательно снабдить какой-то пометкой, которая будет означать, что это слово в реальности вряд ли существует, но его можно использовать только для отгадывания чужих кроссвордов.
А на этом пока всё, всем пока, и до новых встреч!