
За последний год в мире высоких технологий произошли кардинальные перемены, когда искусственный интеллект затмил метавселенную и стал главным трендом интернета. Внезапно все компании ринулись создавать собственные большие языковые модели (LLM), однако большинство из них работают в облаке на мощных серверных конфигурациях. На данный момент смартфоны не обладают достаточным объемом оперативной памяти для запуска самых больших и мощных ИИ-моделей, но компания Apple заявила, что нашла решение В новой исследовательской работе инженеры Apple предлагают хранить параметры LLM во флэш-памяти NAND iPhone, а не в ограниченной мобильной оперативной памяти.
Благодаря тому, что Qualcomm, Intel и другие компании начали активно добавлять аппаратное обеспечение для машинного обучения в новейшие чипы, ваш следующий смартфон будет иметь почти все необходимое для работы на нем локального искусственного интеллекта. Проблема в том, что большие языковые модели не зря получили свое название - они реально занимают много места в оперативной памяти. Во время работы ИИ-модели в оперативной памяти должны храниться триллионы параметров, а в телефонах на данный момент не так много оперативной памяти, особенно в телефонах Apple, максимальный объем которых в iPhone 15 Pro составляет всего 8 ГБ.
Ускорители искусственного интеллекта, запускающие эти ИИ-модели в центрах обработки данных, оснащаются гораздо большим объемом памяти по сравнению с игровыми видеокартами. Например, в флагманской модели Nvidia H100 установлено 80 Гб памяти HBM2e против 24 Гб GDDR6X в игровой RTX 4090 Ti.
Google сейчас работает над расширением возможностей мобильных LLM с помощью своей новой модели Gemini, которая имеет "нано"-версию, ориентированную на смартфоны. Новое исследование компании Apple направлено на то, чтобы втиснуть в смартфон более крупную модель за счет использования флеш-памяти NAND, которая как правило в 10 раз превосходит объем оперативки телефона. Основная проблема заключается в скорости - флэш-память работает гораздо медленнее.
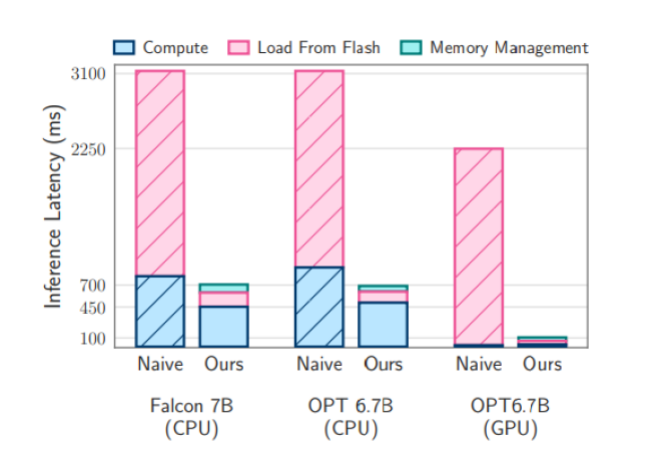
Apple заявила, что добилась существенного повышения скорости, адаптировав модель к использованию флеш-памяти.
Согласно новому исследованию, команда инженеров использовала два метода, чтобы заставить свою ИИ-модель работать без оперативной памяти. Оба они направлены на уменьшение объема данных, которые модель должна загружать из хранилища. Технология оконной выборки позволяет модели загружать в оперативку параметры только для последних токенов, фактически рециркулируя данные для сокращения обращений к хранилищу. Также было использовано объединение строк и столбцов для более эффективной группировки данных, чтобы модель могла обрабатывать большие куски данных.
Исследование также показало, что такой подход расширяет возможности LLM на iPhone. При таком подходе LLM работают в 4–5 раз быстрее на стандартных процессорах и в 20–25 раз быстрее на графических процессорах. Возможно, самое главное, что iPhone сможет запускать модели искусственного интеллекта, размер которых в два раза превышает объем установленной оперативной памяти, сохраняя параметры во внутренней памяти. В исследовании делается вывод, что этот подход может открыть путь к запуску LLM на устройствах с ограниченной памятью.



















