Представим себе сайт интернет-магазина, на котором есть такие разделы:

Это типичное дерево. И конечно встречается оно не только на сайтах. Задача построения и вывода дерева зачастую становится одной из основных.
Введём начальные условия. Каждый раздел сайта можно представить следующими данными:
- id – идентификатор раздела
- parent_id – идентификатор родительского раздела
- title – название раздела
Могут быть ещё какие-то свойства, но это уже неважно.
Важно то, что раздел, который находится внутри другого раздела, является его потомком. Cвойство parent_id этого раздела будет равно свойству id родительского раздела.
В примере выше раздел Main Page может иметь id = 1. Тогда разделы Hardware и Software будут иметь parent_id = 1.
Такая структура подходит для хранения в таблице базы данных. Представим, что движок сайта отдал нам все разделы в виде JSON-объекта. Так как это выходит за рамки решаемой задачи, данный объект я просто сделаю руками на JS:
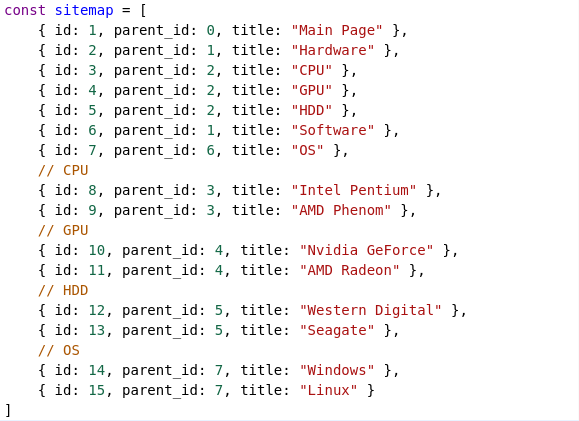
Это простой массив, и задача – построить из него дерево. Чтобы не возникало никаких предположений относительно порядка элементов, я случайным образом перемешаю массив:
Сделать хоть раз что-нибудь не так
Есть готовые алгоритмы, но иногда мне хочется придумать какую-то забавную, или даже идиотскую штуку, и отталкиваться от неё. Для построения дерева как правило нужна рекурсия, а программирование рекурсии обычно происходит муторно.
Поэтому я представил себе такую схему. Все разделы находятся в массиве, куда мы запускаем магнит на удочке. У магнита есть такое свойство: он равен какому-то числу, и к нему прилипают только те разделы, у которых parent_id равен этому числу. Выловленные таким образом разделы попадают в "улов".
Затем берём первый элемент из улова, делаем из него новый магнит и запускаем опять ловить оставшиеся разделы. К нему будут прилипать его потомки. Выловленные тоже попадают в улов. Затем берём второй элемент из улова и т.д.
Получается, что мы перебираем улов от начала, а все новые выловленные элементы добавляются в конец, увеличивая его, но мы в результате дойдём и до них. Перебор закончится, когда размер улова станет равен размеру исходного массива.
Улов будет отсортирован по parent_id (по возрастанию уровня вложенности), но чтобы им реально можно было пользоваться, нужно в каждом элементе указать, имеет ли он потомков, и где эти потомки расположены.
Для этого разделы сайта, добавляемые в улов, оборачиваются в такой объект:
{ page: page, cnt: 0, sub_pos: 0 }
У которого page это раздел сайта, cnt это количество потомков, а sub_pos это позиция в улове, где расположен первый потомок. Если cnt = 0, то позиция конечно не учитывается.
Получился такой код:
Корневой раздел сайта не имеет родителей, поэтому parent_id у него равен нулю. С этого и начинаем, присвоив магниту значение 0.
На первом этапе улов пуст, поэтому алгоритм сразу перейдёт к вылову и найдёт раздел Main Page, добавив его в улов. Затем, на следующей итерации, он возьмёт из улова ранее добавленный раздел Main Page, и далее будет вылавливать его потомков. Место хранения будущих потомков очевидно находится в конце текущего улова, поэтому полю sub_pos объекта, для которого ищем потомков, всегда присваивается текущая длина улова haul.length. А если потомок найден, то увеличиваем счётчик потомков cnt у объекта.
Вывод на печать
При выводе без рекурсии обойтись уже не удалось, но рекурсия для вывода всегда приятнее, чем рекурсия для построения.
Это не промышленный код, а просто для примера, поэтому я использую document.writeln().
Внешний цикл перебирает улов. Он прерывается, как только встретит раздел с непустым parent_id – это значит, что данный раздел уже выводился ранее через рекурсию. У дерева обычно один корень, поэтому по факту можно брать просто первый элемент улова и всё. Все остальные элементы будут чьими-то потомками. Но можно сделать и несколько корневых разделов с parent_id = 0.
Выводом непосредственно раздела занимается функция output():
В неё передаётся улов и текущая позиция в нём. Она выводит элемент в текущей позиции и затем проверяет, если ли у него дети. Если есть, то организует новый блок вёрстки <ul> и рекурсивно вызывает себя для каждого потомка.
В результате получаем вот это:
Заключение
Данный алгоритм работает, если разделы составлены правильно. То есть все id-ы указаны правильно, и каждый потомок имеет родителя, а не болтается с несуществующим parent_id. Добавлять работу над ошибками я не стал, чтобы не захламлять код.
Основная проблема в условии:
while (haul.length < sitemap.length) ...
Оно подразумевает, что все разделы сайта попадут в улов. Так и будет, если всё задано правильно. Иначе это условие может никогда не выполниться. В качестве неидеального, но простого решения можно ограничить количество попыток количеством разделов:
let attempts = sitemap.length;
while (attempts--) ...
И таким образом перебор гарантированно закончится.
Половить разделы магнитом можно онлайн