Введение

Привет! Сегодня хочу рассказать о принципах работы самой нашумевшей, на сегодняшний день, нейросети – ChatGPT.
Я и сама многому научилась, создавая данную статью. Надеюсь, вы тоже найдете для себя что-то новое. Каждую статью стараюсь писать доступным языком для каждого.
ChatGPT был выпущен 30 ноября 2022 года. За два месяца он достиг 100 миллионов активных пользователей. Это самое быстрорастущее приложение в истории.
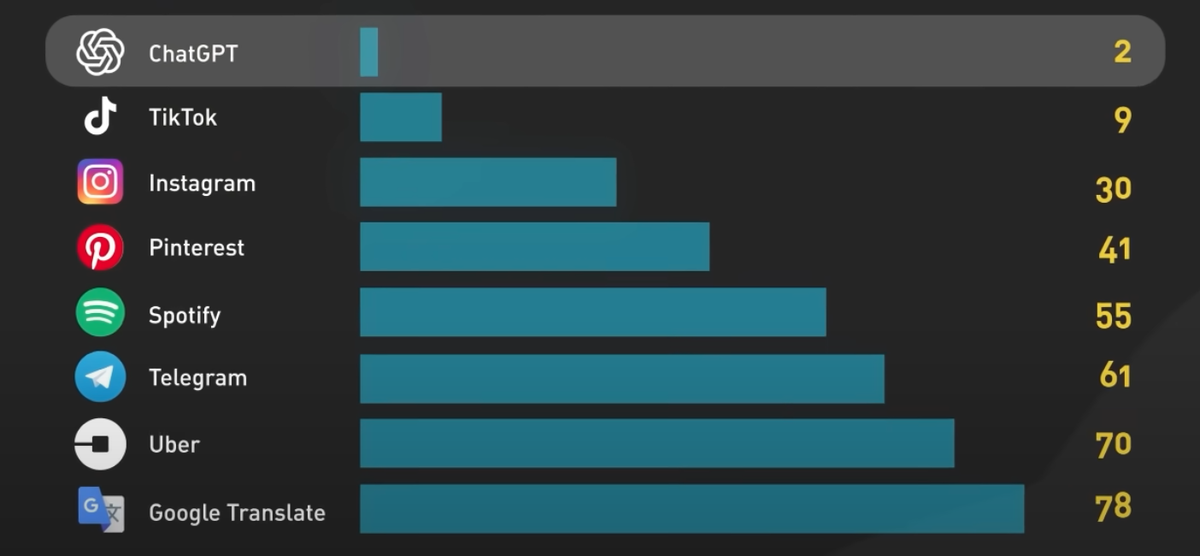
Для сравнения, Telegram потребовалось 5 лет, чтобы достичь того же результата.
Интерес людей к нейросетям очевиден и просто поражает, не правда ли?
Как работает ChatGPT?
Суть ChatGPT заключается в том, что он использует Большие Языковые Модели (LLM) для понимания наших запросов и для ответов на них.
Модели GPT-3.5 и GPT-4 обучены на огромном количестве данных, взятых из интернета, - для понимания и генерации человеческого языка. Модель GPT-3.5 имеет 175 миллиардов параметров, распределенных по 96 слоям нейронной сети, и была обучена на 500 миллиардах токенов.
Входные и выходные данные модели организованы с помощью токенов. Токены - это числовые представления слов, или, точнее, частей слов. Вместо слов, модели используют числа, потому что они обрабатываются более эффективно.
В отличие от GPT-3.5, GPT-4 является новейшей и самой современной моделью с еще большим количеством параметров и слоев, обученной на более обширном наборе данных. Большее количество параметров и слоев в модели GPT-4 позволяет ей лучше понимать сложные запросы и генерировать более точные и разнообразные ответы. Это делает ее одной из самых больших когда либо созданных моделей глубокого обучения.
Если вы прочитали этот абзац и ничего не поняли, есть более простое объяснение.
Я попросила ChatGPT объяснить вам на простом примере, как влияет количество параметров и токенов на производительность работы нейросети.
Давай представим, что у нас есть волшебная ручка, которая умеет создавать разные истории и тексты. Эта ручка называется "GPT-3.5".
Теперь давай представим, что внутри этой ручки есть много маленьких "мозговых клеток" (это как крошечные роботы), которые работают вместе, чтобы придумывать и писать тексты. У GPT-3.5 есть 175 миллиардов таких крошечных роботов (мозговых клеток). Чем их больше, тем умнее будет наша ручка.
Теперь давай представим, что эта ручка учится на миллиардах историй и текстов, которые когда-либо были созданы людьми. Она читает эти тексты и понимает, как «правильно» писать. GPT-3.5 была обучена на 500 миллиардах таких текстов.
Итак, количество мозговых клеток и количество текстов, на которых обучается ручка, влияют на то, как она умеет писать. Если у нее много мозговых клеток и она училась на основании множества текстов, она будет хорошо и интересно писать разные истории и отвечать на вопросы. Но при этом ей потребуется больше времени и мощности, чтобы произвести то, что мы попросим.
Принципы работы Моделей GPT
Модель обучена предсказывать следующий токен (слово), учитывая последовательность входных токенов. Она способна генерировать текст, который структурирован таким образом, чтобы быть грамматически правильным и семантически похожим на интернет-данные, на которых она была обучена.
Но без «правильного запроса» и без «правильной последовательности» работы с ней, модель также может генерировать ответы, которые являются ложными. При этом, она будет с полной уверенностью и без сомнения выдавать эти данные за действительность.
Несмотря на этот серьезный недостаток, модель уже очень полезна для решения огромного количества задач, но в очень структурированном виде.
Ее можно 'научить' выполнять задачи с помощью тщательно разработанных текстовых подсказок. Отсюда и появилось новое направление - 'инженерия подсказок'.
Чтобы сделать модель безопасной и способной отвечать на вопросы и ответы, модель дополнительно настраивается для создания версии, используемой в ChatGPT. Об этом расскажу далее.
Процесс обучения и настройки Моделей
Для улучшения безопасности и эффективности модели, ее дополнительно настраивают при помощи процесса, который называется «Обучение с Подкреплением от Человеческой Обратной Связи» (RLHF).
Без этих настроек, использование ChatGPT в виде чат-бота, которому можно доверять, и который знает все и обо всем, было бы невозможно.
OpenAI объясняет, как они проводили RLHF на модели, но это нелегко понять для людей, незнакомых с машинным обучением. Попробую объяснить на примере.
Представьте высококвалифицированного шеф-повара, который может приготовить широкий ассортимент блюд. Повар – это GPT-3.5. Настройка GPT-3.5 с помощью RLHF похожа на улучшение навыков этого повара, чтобы его блюда стали еще вкуснее.
Сначала повар обучается на большом количестве рецептов и техник приготовления каждого блюда. Однако, иногда повар не знает, какое блюдо приготовить по запросу клиента. Чтобы помочь повару с этим, мы собираем обратную связь от реальных людей, чтобы создать новый набор данных.
Первый шаг - создание сравнительного набора данных. Мы просим повара приготовить несколько блюд по конкретному запросу клиента, а затем просим людей оценить блюда по вкусу и подаче. Это помогает повару понять, какие блюда предпочитают клиенты.
Следующий шаг – вознаграждение нашего героя. Повар использует эту обратную связь для понимания предпочтений клиентов. Чем выше он получил вознаграждение, тем лучше было его приготовленное блюдо.
Далее мы обучаем модель с помощью Проксимальной Оптимизации Политики (РРО) - для улучшения навыков Модели.
В этой аналогии, повар практикует приготовление блюд, следуя модели вознаграждения. Это похоже на то, как повар сравнивает свое текущее блюдо с немного измененной версией и учится понимать, какое из них лучше, согласно модели вознаграждения. Этот процесс повторяется несколько раз, и повар совершенствует свои навыки на основе обновленной обратной связи от клиентов.
С каждым повторением, блюда повара становятся все лучше и лучше, а клиенты все более удовлетворены его творениями.
Итак, GPT-3.5 настраивается с помощью RLHF, собирая обратную связь от людей, создавая модель вознаграждения на основе их предпочтений и, затем, итеративно улучшая производительность модели с помощью PPO. Это позволяет GPT-3.5 генерировать лучшие ответы, адаптированные к конкретным запросам пользователей.
Использование ChatGPT для Общения / Безопасность и Модерация в ChatGPT
Теперь, когда мы понимаем, как модель обучается и настраивается, давайте посмотрим, как модель используется в ChatGPT для ответа на какой-то запрос любого пользователя.
В общем, это так же просто, как отправка запроса в модель ChatGPT и получение результата на выходе. На самом деле, изнутри все это работает немного сложнее.
Во-первых, ChatGPT знает контекст беседы с каждым пользователем.
Это достигается за счет того, что пользовательский интерфейс ChatGPT (то самое окошко чата, в котором мы ведем беседу с нейросетью) подает модели всю предыдущую беседу каждый раз, когда вы вводите новый запрос. Это называется "введением разговорной подсказки". Благодаря этому, ChatGPT кажется супер включенным в диалог и очень внимательным собеседником.
Во-вторых, в ChatGPT включена первичная инженерия подсказок.
Это инструкции, вставленные до и после запроса пользователя, чтобы направлять модель на разговорный тон. Эти подсказки невидимы для нас с вами, но очень сильно облегчают общение с GPT. Часто складывается ощущение общения со знакомым или с другом, который многое о нас знает.
В-третьих, запрос передается в API-модерацию, чтобы предупредить или заблокировать определенные типы небезопасного контента. Сгенерированный результат также, вероятно, будет передан в API-модерацию до того, как направить результат пользователю.
API модерации - это программный интерфейс, который позволяет автоматически проверять и анализировать контент, например, текст, изображения или видео, чтобы определить, соответствует ли он установленным правилам и стандартам. Он широко используется в онлайн-сервисах и в социальных сетях для фильтрации контента и поддержания безопасной и законной среды.
Заключение
В создание моделей, используемых ChatGPT, вложено много инженерных усилий. Лучшие умы мира работают над их созданием и улучшением.
Технология, лежащая в основе этого, постоянно развивается, открывая двери к новым возможностям и изменяя способ нашего общения.
Нам остается только пристегнуть ремни и наслаждаться увлекательной поездкой в невероятный мир будущего.
Подписывайтесь на мой блог, ставьте лайк, если статья оказалась полезной для вас.
НейроМарго ✌️