ОСНОВНЫЕ ОПРЕДЕЛЕНИЯ
Нейронная сеть (Neural Network): Нейронная сеть представляет собой математическую модель, которая имитирует работу нейронов в человеческом мозге. В нейронной сети существует множество связанных узлов, называемых нейронами, которые выполняют обработку информации.
Сверточная нейронная сеть (Convolutional Neural Network, CNN): CNN - это тип нейронной сети, специально разработанный для обработки изображений. Он состоит из сверточных слоев, которые способны выявлять различные признаки в изображениях, и полносвязных слоев для классификации объектов.
Классификация изображений: Эта задача заключается в том, чтобы присвоить изображению один или несколько классов (категорий) на основе его содержания. Например, классификатор должен определить, что на изображении изображен автомобиль или грузовик.
Графический процессор (GPU): Графический процессор - это специализированное вычислительное устройство, которое обладает высокой вычислительной мощностью и способно выполнять параллельные вычисления. В глубоком обучении GPU широко используются для ускорения обучения нейронных сетей.
Тензор (Tensor): Тензор - это многомерный массив числовых данных, который используется для представления входных и выходных данных в нейронных сетях. Тензоры позволяют эффективно хранить и обрабатывать данные в нейронных сетях.
Фреймворк машинного обучения (Machine Learning Framework): Фреймворк машинного обучения - это программное обеспечение, которое предоставляет инструменты и библиотеки для создания, обучения и применения нейронных сетей. Примерами таких фреймворков являются TensorFlow, PyTorch, Keras и другие.
Софтмакс-функция (Softmax Function): Софтмакс-функция - это математическая функция, которая преобразует вектор числовых значений в вероятностное распределение. Каждый элемент вектора представляется как вероятность принадлежности к определенному классу.
АУГМЕНТАЦИЯ ДАННЫХ И ЕЕ ЗНАЧЕНИЕ
В данной курсовой работе использовался метод аугментации, так как возникла проблема переобучения нейронной сети (Overfitting), так как при составлении датасета возникла нехватка изображений для достаточного обучения моей модели.
Переобучение (Overfitting) - это явление, при котором модель слишком хорошо "запоминает" обучающие данные, но плохо обобщает на новые, ранее не виденные данные. Для решения данной проблемы, мной была выбрана стратегия использования метода аугментации, так как этот метод позволяет минимизировать переобучение.
Аугментация данных - это техника, которая заключается в создании новых обучающих примеров путем преобразования существующих данных. Целью аугментации данных является увеличение разнообразия обучающего набора данных без необходимости собирать больше реальных данных. Это особенно полезно в задачах обучения нейронных сетей, таких как классификация изображений.
Главная цель аугментации данных - улучшение обобщения моделей машинного обучения. Путем внесения разнообразия в обучающие данные можно сделать модель более устойчивой к разнообразным сценариям и условиям. Это помогает бороться с переобучением, когда модель становится слишком адаптированной к обучающим данным и теряет способность обобщать на новые данные.
Виды аугментации данных:
• Повороты: Поворот изображения на определенный угол.
• Зум: Изменение масштаба изображения (увеличение или уменьшение).
• Отражения: Отражение изображения по горизонтали или вертикали.
• Изменение яркости и контраста: Модификация яркости и контраста изображения.
• Обрезка: Обрезка изображения до определенного размера.
Применение аугментации: Аугментацию можно применять к обучающим данным перед каждой эпохой обучения. Это означает, что каждая эпоха видит немного измененные данные, что способствует лучшему обобщению модели.
Библиотеки и инструменты: Существует множество библиотек и инструментов, которые упрощают применение аугментации данных в машинном обучении. Например, в библиотеках TensorFlow и Keras есть встроенные средства для аугментации изображений.
Потенциальные проблемы: Хотя аугментация данных может быть мощным инструментом, необходимо осторожно применять ее. Слишком интенсивная аугментация может привести к искажению данных, и модель может перестать распознавать реальные образцы. Поэтому важно балансировать аугментацию для сохранения смысла данных.
Реализация на графическом процессоре (GPU): Для ускорения процесса аугментации данных можно использовать графический процессор (GPU), который способен обрабатывать множество изображений параллельно.
ОПИСАНИЕ ВЫБОРА АРХИТЕКТУРЫ НЕЙРОННОЙ СЕТИ
Для решения поставленной задачи, я выбрал сверточную структуру нейронной сети, так эти сети специально разработаны для обработки изображений и видео. Они содержат сверточные слои, которые могут автоматически извлекать важные признаки из визуальных данных.
Свёрточная нейронная сеть — класс нейронных сетей, который специализируется на обработке изображений и видео. Такие нейросети хорошо улавливают локальный контекст, когда информация в пространстве непрерывна, то есть её носители находятся рядом. Например, пиксели — части изображения, которые расположены близко друг к другу и содержат визуальные данные: яркость и цвет.
Структура свёрточных нейронных сетей похожа на воронку: всё начинается с общей картины, а потом фокус смещается на детали. Мозг устроен так же.
Свёрточные нейронные сети состоят из нескольких слоёв. Чем больше слоёв, тем мощнее архитектура и лучше обучение нейросети. Основные элементы свёрточной нейронной сети:
• Сверточный слой
• Пулинг
• Полносвязный слой
Чтобы нейросеть «узнала» объект, нужно проделать с изображением несколько типовых операций на каждом слое. Ключевая из этих операций — свёртка. Во время свёртки нейросеть удаляет лишнее и оставляет полезное — то, что поможет проанализировать изображение. Например, линии, края или ровные области. Свёртку можно создавать для каждого признака. Нейросеть будет сама подбирать их во время распознавания и классификации на каждом свёрточном слое.
Эти слои применяют фильтры (ядра) к входным данным, чтобы выявлять различные паттерны и признаки.
Характеристики сверточных слоев:
• Каждый сверточный слой имеет набор ядер (фильтров), которые применяются к входным данным.
• Размер ядра определяет, сколько соседних пикселей анализируется каждым ядром.
• Шаг определяет, как часто ядро перемещается по входным данным.
• После применения свертки, к результатам применяется функция активации.
• Часто после сверточных слоев следует слой пулинга, который из признаков, которые выделил свёрточный слой, выбирает самые важные, а несущественные удаляет.
Полносвязные слои представляют собой обычные слои нейронов, в которых каждый нейрон связан с каждым нейроном предыдущего и следующего слоя. Эти слои используются для агрегации признаков и принятия окончательных решений. В задаче классификации, полносвязный слой на выходе может иметь количество нейронов, равное числу классов.
ОПРЕДЕЛЕНИЕ ИСХОДНЫХ ДАННЫХ И ОБУЧАЮЩЕГО НАБОРА
Весь следующий код я писал в Google Colab (сокращение от Google Colaboratory) - это бесплатная среда для выполнения кода на языке Python, основанная на облачных ресурсах Google. Colab предоставляет доступ к мощным вычислительным ресурсам, включая графические процессоры (GPU) и тензорные процессоры (TPU), и позволяет пользователям создавать и выполнять Python-код в интерактивной среде прямо в веб-браузере. Основной причиной использования этой среды было предустановленное ПО, так как Google Colab предоставляет множество предустановленных библиотек и пакетов, таких как TensorFlow, PyTorch, NumPy и другие, что упрощает разработку и обучение моделей машинного обучения. Еще одним критерием выбора этой среды был бесплатный доступ к мощным облачным ресурсам.
РЕАЛИЗАЦИЯ
Первым делом было необходимо импортировать библиотеки и модули , которые будут использоваться в моем проекте.
import matplotlib.pyplot as plt
import numpy as np
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
Далее была объявлена переменная, которая содержала путь к корневой директории.
image_folder='/content/drive/MyDrive'
Следующим действием было создание датасетов и их кэширование:
batch_size = 32 #количество изображений, которые будут загружены и обработаны за одну итерацию обучения
img_width = 299
img_height = 299
train_ds = tf.keras.utils.image_dataset_from_directory( #функция которая используется для создания датасета изображений на основе директории с данными
image_folder, #путь к корневой директории
validation_split=0.2, #аргумент валидации, 20% на валидацию, 80% на обучение
subset="training",
seed=123,
image_size=(img_height,img_width),
batch_size=batch_size)
validation_ds = tf.keras.utils.image_dataset_from_directory(
image_folder,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height,img_width),
batch_size=batch_size)
class_names = train_ds.class_names
print(f"Class names: {class_names}")
# cash
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
validation_ds = validation_ds.cache().prefetch(buffer_size=AUTOTUNE)
После этого появилось такое сообщение:
Found 1334 files belonging to 4 classes.
Using 1068 files for training.
Found 1334 files belonging to 4 classes.
Using 266 files for validation.
Class names: ['Bmp', 'Cars', 'Tank', 'Truck']
Это означает, что среда обнаружила 1334 изображения и 1068 из них пойдет на обучение, а оставшиеся 266 на валидацию. Так же было обнаружено 4 класса (Бмп, Машины, Танки, Грузовики).
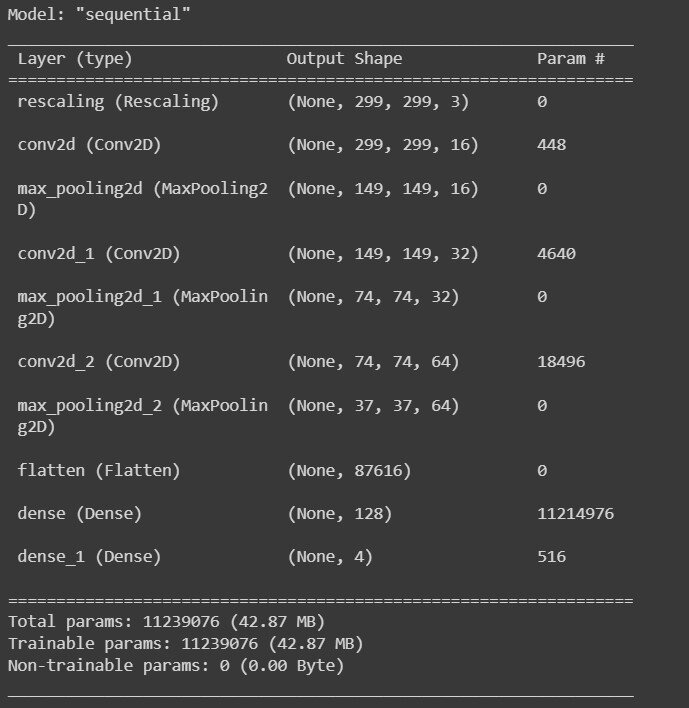
Следующим шагом было создание модели, ее компиляция и вывод сводки о получившейся модели.
#creat model
num_classes = len(class_names)
model = Sequential([ #cлои добавляются последовательно друг за другом
layers.experimental.preprocessing.Rescaling(1./255,input_shape=(img_height,img_width,3)),#слой для нормализации данных
#дальше везде одинаково
layers.Conv2D(16,3,padding='same',activation='relu'), #Это слой свертки (Convolutional Layer).
#количество фильтров (или ядер), которые применяются к изображению; размер фильтра, который перемещается по изображению;
#Параметр 'same' означает, что будет автоматически добавлено "нулевое" (нулевое) заполнение по краям изображения так,
#чтобы размеры выходного изображения были такими же, как у входного.
#ReLU (Rectified Linear Unit) применяется после сверточной операции. Она вводит нелинейность в модель,
#позволяя сети изучать сложные отношения между признаками.
layers.MaxPooling2D(), #этот слой использует размер пулинга 2x2 и операцию максимального пулинга.
layers.Conv2D(32,3,padding='same',activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64,3,padding='same',activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(), #преобразование многомерных данных в одномерные данные
layers.Dense(128,activation='relu'),
layers.Dense(num_classes)#Этот слой является финальным слоем в архитектуре нейронной сети и выполняет классификацию
])
# compile the model
model.compile( #метод компиляции модели
optimizer='adam', #оптимизатор, который будет использоваться для обновления весов модели во время обучения
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), #функция потерь, которая измеряет разницу между предсказанными значениями модели и фактическими метками
metrics=['accuracy'] #измеряет долю правильных классификаций
)
# print model summary
model.summary()
Следующим шагом было обучение нейросети и вывод графиков точности.
#train the model
epochs=10
history=model.fit( #метод, который запускает обучение модели
train_ds, #обучающий набор данных, который содержит изображения и соответствующие им метки классов
validation_data=validation_ds, #Валидационный набор данных используется для оценки производительности модели
#на данных, которые она ранее не видела. Это помогает выявить переобучение (overfitting) и следить за качеством модели
epochs=epochs
)
# visual training and validation results
acc=history.history['accuracy'] #точность на обучающем наборе данных извлекается из истории обучения
val_acc=history.history['val_accuracy'] #точность на валидационном наборе данных извлекается из истории обучения
loss=history.history['loss'] #значения функции потерь на обучающем наборе данных извлекаются из истории обучения
val_loss=history.history['val_loss'] #значения функции потерь на валидационном наборе данных извлекаются из истории обучения
epochs_range = range(epochs) #представляет собой последовательность чисел от 0 до epochs - 1
plt.figure(figsize=(8,8))
plt.subplot(1,2,1)
plt.plot(epochs_range,acc,label='Training Accuracy')
plt.plot(epochs_range,val_acc,label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1,2,2)
plt.plot(epochs_range,loss,label='Training Loss')
plt.plot(epochs_range,val_loss,label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Процесс обучения выглядел следующим образом:
На GPU:
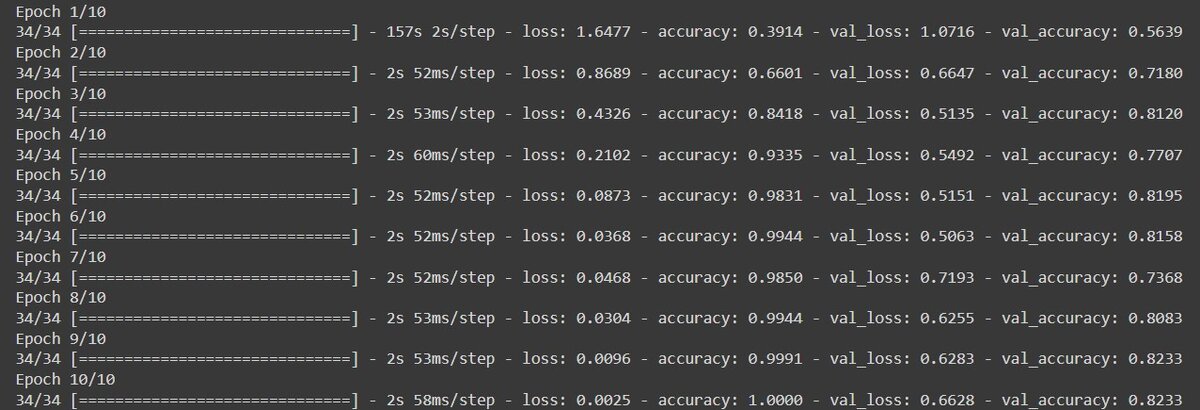
На CPU:
Преимущество использования GPU дало выигрыш в 6 раз.
Графики точности и потерь
Вывод из графиков: из графика точности видно, что после 4 эпохи обучения валидационная точность не меняется. Из графика потерь видно, что тренировочные потери к 10 эпохе минимальные, в то время как валидационные стремительно растут. Это значит что нейросеть к 10 эпохе начинает очень точно распознавать тренировочный датасет и очень плохо валидационный. Это и есть переобучение(overfitting).
Обычное увеличение количества эпох не дало никакой результат по улучшению качества классификации изображений, а только более наглядно показало, как выглядит переобучение нейронной сети.
Для решения данной проблемы я выбрал метод аугментации, его реализация выглядит следующим образом. При создании модели добавились новые слои, которые позволяли увеличить количество изображений. Это слои: отображение изображения по горизонтали, вращение изображения, приближение или отдаление, изменение контраста.
#creat model
num_classes = len(class_names)
model = Sequential([ #cлои добавляются последовательно друг за другом
layers.experimental.preprocessing.Rescaling(1./255,input_shape=(img_height,img_width,3)),#слой для нормализации данных
#аугментация
layers.experimental.preprocessing.RandomFlip("horizontal",input_shape=(img_height,img_width,3)), #отображает по горизонтали
layers.experimental.preprocessing.RandomRotation(0.1), #вращение изображения
layers.experimental.preprocessing.RandomZoom(0.1), #приближение или отдаление
layers.experimental.preprocessing.RandomContrast(0.2), #изменение контраста
#дальше везде одинаково
layers.Conv2D(16,3,padding='same',activation='relu'), #Это слой свертки (Convolutional Layer).
#количество фильтров (или ядер), которые применяются к изображению;размер фильтра, который перемещается по изображению;
#Параметр 'same' означает, что будет автоматически добавлено "нулевое" (нулевое) заполнение по краям изображения так,
#чтобы размеры выходного изображения были такими же, как у входного.
#ReLU (Rectified Linear Unit) применяется после сверточной операции. Она вводит нелинейность в модель,
#позволяя сети изучать сложные отношения между признаками.
layers.MaxPooling2D(), #Пулинговые слои используются для уменьшения размера изображения и уменьшения количества параметров в сети.
#этот слой использует размер пулинга 2x2 и операцию максимального пулинга.
layers.Conv2D(32,3,padding='same',activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64,3,padding='same',activation='relu'),
layers.MaxPooling2D(),
#регуляризация
layers.Dropout(0.2), #добавляет регуляризацию к модели случайным образом "выключает" часть нейронов во время обучения
#с указанной вероятностью (в данном случае 20%). Это помогает предотвратить переобучение и повышает обобщающую способность модели.
layers.Flatten(), #преобразование многомерных данных в одномерные данные
layers.Dense(128,activation='relu'), #Этот слой полносвязный, что означает, что каждый нейрон этого слоя связан со всеми нейронами предыдущего слоя;
#количество нейронов в данном полносвязном слое;
layers.Dense(num_classes)#Этот слой является финальным слоем в архитектуре нейронной сети и выполняет классификацию
])
# compile the model
model.compile( #метод компиляции модели
optimizer='adam', #оптимизатор, который будет использоваться для обновления весов модели во время обучения
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), #функция потерь, которая измеряет разницу между предсказанными значениями модели и фактическими метками
metrics=['accuracy'] #измеряет долю правильных классификаций
)
# print model summary
model.summary()
Соответственно новые слои добавились в сводку о модели:
В коде обучения модели ничего не поменялось, я только выбрал 20 эпох обучения.
Процесс обучения выглядел следующим образом:
На GPU:
На CPU:
Преимущество использования GPU дало выигрыш в 14 раз.
Графики точности и потерь:
Из графика можно увидеть, что к 20 эпохе обучения нейронная сеть максимально точно распознает как тренировочный, так и валидационный датасеты. Потери же, как для тренировочного, так и для валидационного минимальны.
ЭКСПЕРИМЕНТЫ И РЕЗУЛЬТАТЫ
Для тестов и проверки работоспособности нейронной сети, я сохранил веса модели:
model.save_weights('/content/drive/MyDrive/model_weights_GPU.h5')
Я создал новый файл в гугл колаб, для реализации инференса (непрерывной работы нейронной сети). В код этого файла попал весь предыдущий код, только вместо обучения модели я загружаю веса уже обученной модели:
from re import VERBOSE
#load the model
model.load_weights('/content/drive/MyDrive/model_weights.h5')
#evaluate the model
loss,acc=model.evaluate(train_ds,verbose=2)
print("Restored model, accuracy: {:5.2f}%".format(100*acc))
Для проведения тестов использовался следующий код:
#load interface
car_path='/content/drive/MyDrive/American3.jpg'
img=tf.keras.utils.load_img(
car_path,target_size=(img_height,img_width)
)
img_array=tf.keras.utils.img_to_array(img)
img_array=tf.expand_dims(img_array,0)
#make predictions
predictions=model.predict(img_array)
score=tf.nn.softmax(predictions[0])
#print interface result
print("На изображении скорее всего {} ({:.2f})% вероятность".format(
class_names[np.argmax(score)],
100*np.max(score)
))
plt.imshow(img)
plt.axis('off') # Отключить оси
# Вывести изображение
plt.show()
В значение переменной car_path вводится адрес изображения и нейросеть определяет класс к которому принадлежит данное изображение.
Были выбраны изображения, которых не было в датасете.
Танки:
БМП:
Здесь такой маленький процент точности, так как специально было выбрано довольно тяжелое изображение, так как объект очень похож на танк, но по факту является БМП.
Автомобили:
Грузовики:
Из приведенных примеров классификации автомобилей и грузовиков, можно увидеть очень высокий процент точности определения это связано с тем, что датасет, составленный для обучения модели до применения метода аугментации, насчитывал около 500 изображений, а аналогичный датасет для танков и БМП, только лишь порядка 200 изображений.