Обработка предназначена для решения проблемы управлением индексами в платформе 1С 8.3 в режиме клиент-сервера
Что это?
При работе с платформой 1С мы неявно используем ORM (Object-Relational Mapping) - отображение объектов в реляционную СУБД. В ORM 1С слишком мало настроек, можно сказать, их вообще нет, что выгодно отличает ORM 1С от того же Hibernate в java. С одной стороны это удобно, поскольку снимает с разработчика необходимость знать ORM, язык SQL и конкретную СУБД, с другой – приводит к неоправданному снижению скорости работы системы. Самой значимой причиной этого снижения скорости, по моему мнению, является система индексирования. Платформа автоматически создаёт индексы для своих нужд, создать и поддерживать индексы для оптимизации работы запросов средствами платформы – невозможно. Если создавать и удалять индексы средствами СУБД, то при любом изменении структуры метаданного все сделанные изменения будут удалены платформой 1С. Кроме этого, невозможно средствами платформы использовать встроенные поля индекса (include) и параметры индексов.
Таким образом, перед вами попытка кастомизировать ORM для 1С. По аналогии с Hibernate от мира java назовём эту кастомизацию - Спячка1С.
Зачем?!
Обработка предназначена для решения проблемы управлением индексами в платформе 1С. Поддерживаются первая и вторая версии реструктуризации и обе две СУБД: MS SQL Server и PostgreSQL Server. При работе с обработкой создаются необходимые функции и триггер(ы) в базе данных. Обработка не использует какие-либо таблицы базы данных для сохранения информации.
Цель
Дать разработчику инструмент решения крайне распространённой проблемы с производительностью запросов из 1С к базе данных в режиме клиент-сервера.
Какова функция данного инструмента?
Обработка позволяет создавать и удалять индексы для таблиц БД объектов метаданных, используя привычное и удобное представление метаданных в виде дерева. При работе в БД создаются необходимые функции и триггер(ы). Триггер(ы) служат для подержания системы индексов таблиц в заданном пользователем инструмента состоянии. Например, создан пользовательский индекс A для основной таблицы какого-то справочника. Индекс B платформы пользователь пометил на удаление. При любом добавлении, удалении реквизита, изменении типа и т.д. платформа удалит все индексы пользователя и создаст заново свои. Триггер отслеживает подобные события и возвращает индексы в заданное пользователем состояние – добавляет заново пользовательский индекс A и удаляет индекс B платформы. Триггер не влияет на работу с индексами средствами СУБД и на переиндексацию средствами платформы.
Как пользоваться инструментом?
В обработке присутствуют три закладки: Индексы, Анализ индексов и Настройки.
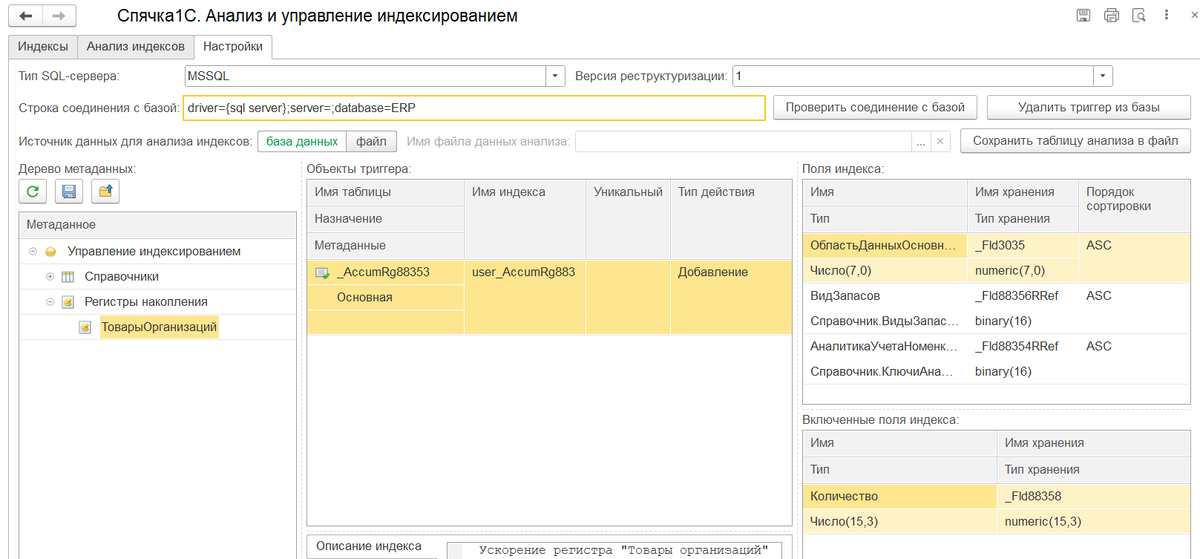
На закладке Настройки нужно указать: тип SQL-сервера (MSSQL или PostgreSQL), версию реструктуризации (1 или 2), строку соединения с базой данных. Если платформа и служба 1С развернуты на одном и том же компьютере, тогда эти значения обработка попытается вычислить. В противном случае нужно заполнить поля самостоятельно.
На закладке присутствуют кнопки Проверить соединение с базой и Удалить триггер из базы. Нажатие кнопки Удалить триггер из базы полностью удаляет все сделанные изменения в индексах, удаляет функции и сам триггер, то есть возвращает базу в то состояние, в котором она была до начала работы с обработкой.
Существует возможность выгрузить результат работы в файл кнопкой Сохранить в файл объекты триггера и загрузить из файла кнопкой Загрузить из файла объекты триггера.
При использовании обработки рекомендуется такой режим работы: создаём тестовую базу, открываем в ней обработку, вносим все необходимые изменения в индексы, сохраняем результат в файл, в рабочей базе открываем обработку и загружаем файл. При этом будут созданы триггер, все необходимые функции для обеспечения поддержки изменений и созданы/удалены индексы.
Для анализа индексов используется переключатель Источник данных для анализа индексов. При выборе варианта Файл становится доступно поле Имя файла данных анализа. В поле нужно указать файл с данными, предварительно полученными при нажатии кнопки Сохранить данные анализа в файл.
Статистика для анализа индексов в MSSQL и PostgreSQL обновляется при каждом перезапуске сервера. Накапливается эта статистика только в данном экземпляре сервера. Поэтому, для работы с анализом индексов предлагается такой режим работы: открываем обработку в рабочей базе, нажимаем кнопку Сохранить данные анализа в файл, сохраняем файл на диск. В тестовой базе в обработке в Источнике данных для анализа индексов указываем режим Файл. Данные статистики для работы с анализом индексов будут браться из файла.
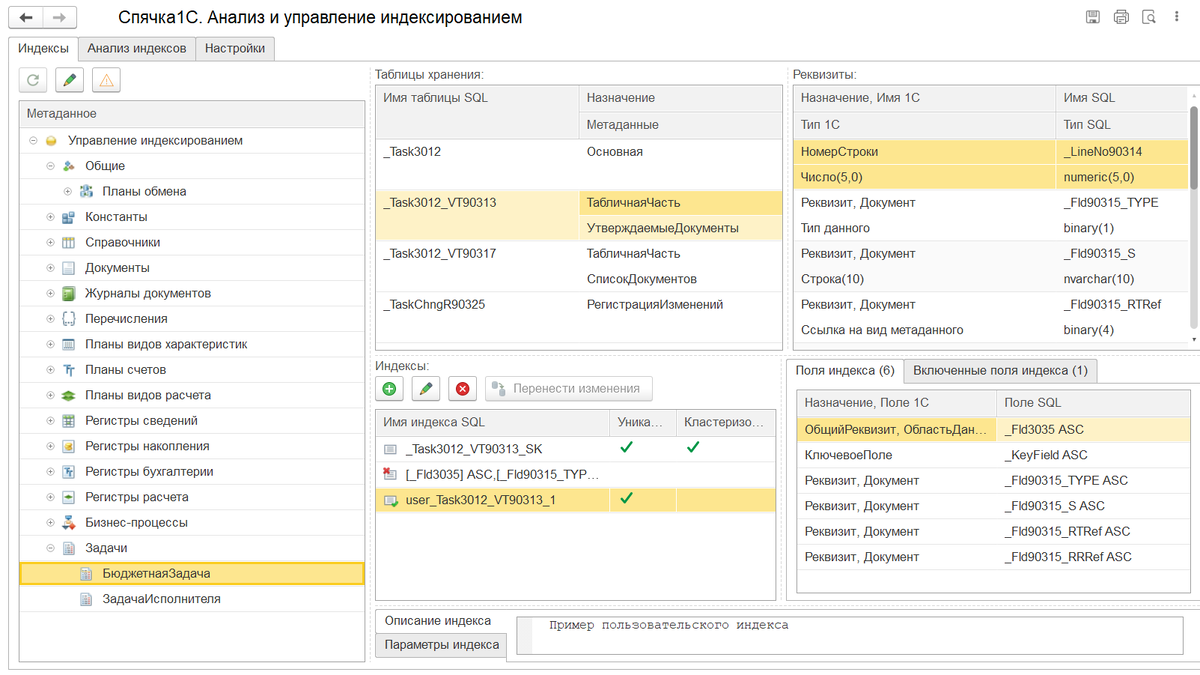
На закладке Индексы присутствуют: Дерево метаданных, Таблицы хранения, Реквизиты, Индексы, Поля индекса, Включённые поля индекса, Описание и Параметры индекса.
В Дереве метаданных отображаются только те объекты метаданных, для которых существуют индексы. В базе обычно присутствует довольно большое количество таблиц, для которых нет соответствия в метаданных, например: _DataHistoryAfterWriteQueue, и ряд таблиц, у которых нет платформенных индексов, например: _Bots (Боты). Они в Дереве метаданных не отображаются и работа с ними невозможна. Вид метаданных Последовательности размещен в разделе Общие (вот-так-вот).
Существуют три варианта отбора индексов в дереве метаданных: Все индексы, Измененные/добавленные индексы, Измененные/добавленные проблемные индексы. При выборе варианта Измененные/добавленные индексы отображаются только те метаданные, в индексах которых есть изменения, внесенные пользователем инструмента. При выборе варианта Измененные/добавленные проблемные индексы отображаются метаданные с индексами, в которых возникли проблемы: переход на расширение или обратно, отсутствие реквизита.
В Таблицах хранения колонки Назначение и Метаданные берутся из результата функции ПолучитьСтруктуруХраненияБазыДанных.
В Реквизитах указываются типы данных SQL-сервера на котором размещена база данных, то есть, для MSSQL и PostgreSQL они будут различаться, иногда весьма существенно.
В добавляемых пользователем индексах можно использовать включённые (include) поля и указывать параметры.
Платформенные индексы (кроме кластерных/первичных ключей) можно помечать на удаление и снимать эту пометку. При установке пометки на удаление индекса платформы открывается форма для ввода описания индекса. В ней можно указать причину удаления. При подтверждении индекс удаляется, но в таблице Индексы выводится строка с представлением индекса. Представление индекса состоит из перечня его полей и названия. При удалении строки представления индекса восстанавливается индекс с прежними полями и параметрами.
Платформа 1С задаёт названия индексам по шаблону – [ИмяТаблицы]_[НомерИндекса]. Для платформенного индекса название не может служить в качестве id, так как при каждом изменении основной таблицы происходит удаление всех индексов и создание новых с другими названиями (или с теми же самыми). В качестве id платформенного индекса используется набор полей с сортировкой. Таким образом, индекс с полями "A ASC, B DESC" не равен индексу с полями "A DESC, B DESC" или "B DESC, A ASC". Для индексов, созданных пользователем, в качестве id используется именно название (поэтому нужно использовать те названия, которые предлагает обработка). Если задать пользовательскому индексу название по шаблону 1С, то возможна коллизия, когда платформа на место этого индекса запишет свой собственный. Этого необходимо избегать.
Пользовательские индексы можно создавать, изменять и удалять. При создании индекса открывается форма добавления индекса.
В этой форме можно подобрать поля индекса из списка разрешённых полей таблицы (кроме nvarchar(MAX) и varbinary), включённые (include) поля, а также указать описание. Эта же форма используется для редактирования индекса.
Для добавление полей в индекс используется форма Добавление полей в индекс
При удалении пользовательского индекса задаётся вопрос, при подтверждении индекс удаляется.
На закладке Анализ индексов отображается статистика SQL-сервера по индексам: недостающим или избыточным.
На закладке Недостающие индексы можно просмотреть список таблиц с недостающими индексами и создать индекс для решения проблемы. MS SQL предоставляет статистику с обычными и включенными полями, в PostgreSQL в статистике полей нет совсем. В любом случае, создавать индексы нужно только после всестороннего анализа, анализ статистики сервера может только помочь в этом, сильно полагаться на него не стоит.
В избыточные индексы попадают те, для которых не было поиска, но были обновления. Такие индексы кнопкой Удалить индекс можно пометить на удаление.
Если источником статистики служит база данных, то при добавлении индекса происходит динамическое обновление статистики. Если же в качестве источника используется файл с предварительно сохраненной статистикой (закладка Настройки), то при добавлении индекса будет удалятся только строка статистики с точно теми же полями, что и в индексе. Изменение состава полей, их сортировки в индексе приводит к тому, что статистика из файла не изменяется. Это необходимо учитывать при работе. При удалении избыточных индексов такой проблемы нет.
Исправление проблем
ORM 1С своеобразно отражает расширения: если метаданное уже существует и добавлено в расширение при внесении различия (добавлении нового поля, изменении типа существующего поля), создаются таблицы в СУБД с постфиксом X1, в них перемещаются все данные из оригинальных таблиц и формируется набор индексов с тем же постфиксом X1. Если же в расширении для метаданного удаляются все различия, то данные перемещаются в оригинальные таблицы, а таблицы с постфиксом удаляются.
В связи с подобной работой ORM 1С возникает первая проблема: если были сделаны доработки в наборе индексов таблицы, а затем метаданное было добавлено в расширение и произведены изменения, то в новой таблице с постфиксом X1 не будет доработок в индексах, они останутся в оригинальной таблице. Для решения этой проблемы служит режим фильтра дерева метаданных Измененные/добавленные проблемные индексы. В этом режиме показываются только метаданные и таблицы с проблемами. Для переноса доработок индексов из оригинальной таблицы в новую таблицу с постфиксом X1 и обратно служит кнопка Перенести изменения в командной панели Индексов. Эта же команда переносит доработки в индексах при удалении всех изменений метаданного в расширении.
Вторая проблема возникает при удалении поля метаданного, задействованного в помеченном на удаление платформенном или в пользовательском индексах. Для отбора таких метаданных и таблиц СУБД предназначен тот же режим фильтра дерева метаданных Измененные/добавленные проблемные индексы.
Если реквизит отсутствует в помеченном на удаление индексе платформы, нужно снять с него пометку удаления, индекс будет восстановлен. Затем нужно провести анализ индексов.
Если реквизит отсутствует в пользовательском индексе - нужно открыть его для редактирования и записать. Информация об отсутствующем поле удалится автоматически.
Подобные проблемы требуют анализа набора индексов и не могут быть решены без участия разработчика.
В случае удаления таблицы СУБД с доработками в индексах, по причине удалении метаданного или его переконфигурирования, информация об этой таблице и доработанных индексах удаляется из триггера автоматически при изменении любого индекса любой таблицы СУБД обработкой.
Сравнение с другими проектами
Мне не удалось найти что-то подобное ни на Инфостарте, ни где-либо ещё. Возможно, я плохо искал.
Тестирование
Обработка тестировалась на платформе 1C 8.3.23.1739 x64, конфигурации: ERP 2.5.12.48 и SSL 3.1.8.334, СУБД: MS SQL 2019 x64 (15.0.2000.5) и PostgreSQL 14.9 x64. ОС - Windows 10. Предназначена для работы с платформой с версии 8.3.6 и с любыми конфигурациями. СУБД: MS SQL 2014 и старше, PostgreSQL - 10 и старше.
Буду благодарен за комментарии и предложения по дальнейшему развитию проекта.