1. WaveNet
WaveNet - это генеративная модель глубокого обучения, применяемая в области синтеза речи. Разработанная компанией DeepMind, WaveNet использует рекуррентные сверточные нейронные сети для создания естественного и высококачественного звука, очень близкого к настоящей человеческой речи.

Основная идея WaveNet заключается в использовании глубоких сверточных нейронных сетей, способных моделировать условные зависимости между последовательными звуковыми сигналами. В отличие от традиционных методов синтеза речи, которые работают с фонемами или звуками, WaveNet моделирует звук на уровне отдельных сэмплов, что позволяет ей генерировать более реалистичные и качественные результаты.
Одной из главных особенностей WaveNet является использование рекуррентных блоков с dilated свертками. Это позволяет модели обрабатывать бóльшие контексты звуковых сигналов, учитывая широкий контекст во время генерации новых звуков. Благодаря этому WaveNet способна создавать более естественные и плавные переходы между звуками, что приближает ее к качеству реальной человеческой речи.
WaveNet также имеет возможность управлять стилем и интонацией генерируемой речи, благодаря настройке условия или входных параметров. Это позволяет модели переносить различные особенности человеческой речи из обучающего набора данных на самостоятельно созданную речь.
2. Tacotron 2
Tacotron 2 это сеть глубокого обучения, разработанная искусственным интеллектом OpenAI. Она была создана для генерации речи с высокой естественностью и качеством, которая почти неотличима от реального человеческого голоса. Tacotron 2 представляет собой модель конечно-последовательного (end-to-end) синтеза речи, которая принимает на вход текстовые данные и производит соответствующую речевую последовательность.
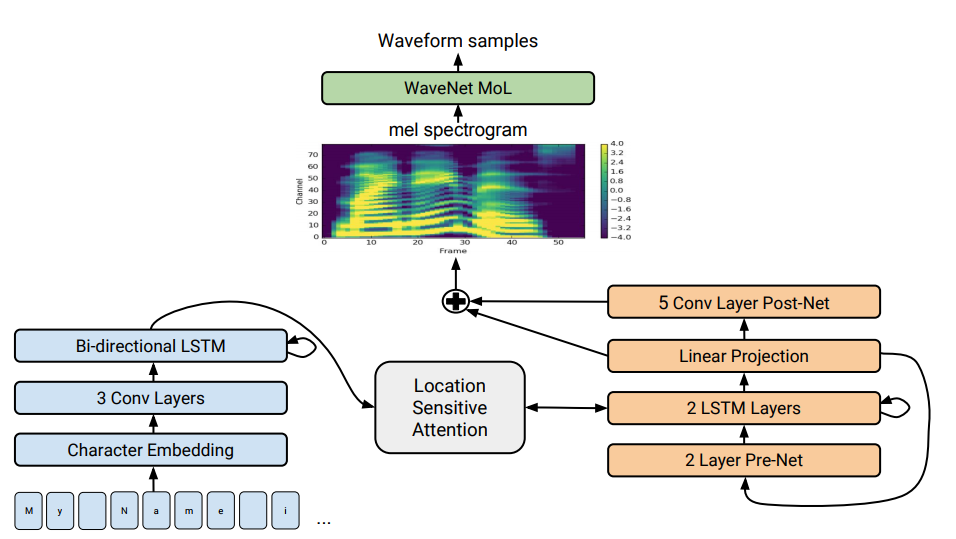
Основой Tacotron 2 является рекуррентная нейросеть, которая работает на основе долгой краткосрочной памяти (LSTM) и использует механизм внимания для выделения важных фрагментов текста. Модель обучается на большом наборе аудиоданных, чтобы понять соответствие между текстом и голосовым выражением. Она также способна учиться от корректировок, которые вносятся вручную аудиоинженерами, чтобы повысить качество и сохранить естественность речи.
Tacotron 2 имеет множество применений, включая синтез речи для роботов или виртуальных ассистентов, создание аудиокниг или подкастов, а также помощь людям с ограниченными или потерянными способностями говорить. Ее высокая точность и натуральность речи открывают новые возможности для интерактивных и голосовых интерфейсов, даже в незнакомых языках или диалектах. Tacotron 2 является прорывным инструментом в области генерации речи и продолжает улучшаться и узнавать на основе новых данных и опыта.
3. Lyrebird
Lyrebird - это глубокая нейронная сеть, разработанная для генерации высококачественной речи по текстовому вводу. Она обладает уникальной способностью обрабатывать и анализировать большие объемы аудиоматериалов для создания убедительных речевых выходов, которые почти неотличимы от реальных человеческих голосов.
Lyrebird базируется на предобученных моделях глубокого обучения и использует передовые технологии в области обработки аудио, машинного обучения и искусственного интеллекта. Для достижения высочайшего качества синтезированного голоса, нейросеть анализирует множество фонетических и мелодических характеристик вводимого текста и преобразует их в натуральную человеческую речь с интонацией, эмоциональной окраской и ритмом говорящего.
Эта передовая технология, разработанная Lyrebird, имеет широкий спектр приложений: от создания персонализированного голосового сообщения для речевого помощника и голосовой навигации до озвучивания аудиокниг, видеоигр, аудиорекламы и других мультимедийных контентов.
Lyrebird также обладает возможностью имитировать специфические голосовые характеристики различных личностей и знаменитостей, что делает ее инструментом для создания оригинального контента и широким инструментом для создания озвученных персонажей в фильмах и анимации.
Команда разработчиков Lyrebird продолжает работать над совершенствованием нейросети, стремясь к улучшению качества генерируемой речи, повышению реалистичности и улучшению функциональности для решения различных задач, связанных с обработкой речи и созданием уникального аудиоконтента.
4. Deep Voice
Deep Voice - это нейронная сеть, разработанная для синтеза речи. Она основана на глубоком обучении и способна генерировать речь, звучащую естественно и человечески. Процесс создания речи с помощью Deep Voice состоит из двух основных этапов: обучение модели и генерация речи.
На этапе обучения модели Deep Voice использует громадные наборы данных с записями голоса, чтобы научиться распознавать и анализировать различные аспекты речи, включая тон, интонацию, акцент и скорость. Модель глубокого обучения получает информацию из этих данных и строит внутреннюю представление речи, которое затем может быть использовано для генерации новых речевых сигналов.
Когда модель основательно обучена, она может генерировать голосовую речь с высокой точностью и естественностью. Пользователь может задать текст, который будет преобразован в речь, а Deep Voice интерпретирует этот текст, применяет знания, полученные в процессе обучения, и производит соответствующие речевые звуки.
Deep Voice обладает большим потенциалом и может быть использована в различных приложениях, включая голосовые помощники, аудиокниги и робототехнику. Ее способность генерировать естественную речь делает ее важным инструментом для улучшения взаимодействия между компьютером и человеком.
5. VoiceSwap
VoiceSwap - это нейросетевая система, разработанная для смены и модификации голосовых записей. С помощью передовых алгоритмов искусственного интеллекта, VoiceSwap способен изменять голосовые характеристики и тембр, а также переносить голос одного диктора на другого.
Эта инновационная технология предлагает широкий спектр возможностей в области голосового контента. Она может быть использована для усовершенствования аудио-продукции, удаляя нежелательные шумы и гарантированно создавая приятный и четкий звук.
VoiceSwap также предлагает уникальную возможность переносить голосовые характеристики из одного языка на другой, обеспечивая автоматический перевод аудиозаписей на разные языки без изменения интонации и выражения оригинального диктора.
Благодаря своей гибкости и высокой точности, VoiceSwap приобретает все большую популярность в различных сферах, таких как аудио-книги, фильмы, реклама, мультимедиа и многое другое. Она открывает новые перспективы для создания яркого и привлекательного голосового контента, сокращая время и ресурсы, ранее необходимые для записи и редактирования звука.
VoiceSwap - ваш личный помощник, который поможет вам достичь высочайшего качества голосовой продукции с минимальными усилиями и максимальным профессионализмом.