Я решил сделать небольшой тур по языкам программирования, которые я когда-либо изучал, и осветить некоторые их особенности.
Начну с ассемблера, хотя он был не первый. Просто на его основе будет видно, как устроены остальные языки.
Вообще говоря, ассемблер это не язык. То есть "ассемблер" не является названием языка. Есть названия C, PHP, Java, Python, а вот именно Ассемблера нет.
Его точное название это assembly language, или язык сборки. Что это значит?
Программа состоит из машинных инструкций. Инструкции выполняются процессором. Сами инструкции выглядят как... обычные числа.
Например, мы можем сами придумать
Инструкции для вымышленного процессора
Чтобы записать какое-то значение в ячейку памяти, нам нужно иметь это самое значение и адрес ячейки. Тогда машинная инструкция может состоять из трёх чисел:
100, 1000, 5
И будет означать: 100 это код операции "запиши", 1000 это адрес памяти, 5 это значение. То есть: запиши значение 5 по адресу 1000.
Кроме ячеек памяти, есть ещё регистры процессора, которые тоже память, но у них нет адресов, а есть собственные имена для обращения напрямую. Тогда инструкция для записи в регистр может выглядеть так:
101, 5
И означать: запиши в регистр номер 1 значение 5.
Так вот язык ассемблера это просто чуть более человеческая запись машинных инструкций.
Вместо инструкции "100, 1000, 5" мы пишем на ассемблере:
mov [1000], 5
Вместо "101, 5" пишем:
mov ax, 5
Архитектуры и синтаксис
Разные процессоры имеют разные архитектуры. Например, процессоры Intel x86 не позволяют иметь в одной машинной команде два адреса памяти. Поэтому копирование значения из одного адреса в другой делается через промежуточный регистр:
mov ax, [1000]
mov [2000], ax
А вот архитектура PDP-11, к примеру, позволяет копировать из памяти в память. И если регистры у Intel называются ax, bx, cx, dx, то у PDP-11 они называются r0, r1, r2, r3...
Но и это ещё не всё. Если взять тот же x86, то инструкцию, например:
mov ax, 5
Можно написать и вот так:
mov $5, %ax
Почему? Потому что это просто другой синтаксис языка ассемблера. И обратите внимание, что теперь приёмник значения %ax стоит справа, а не слева.
Таким образом, язык ассемблера это не какой-то один язык. Это, во-первых, разные машинные архитектуры, а во-вторых, разные синтаксисы даже для одних и тех же инструкций.
Но объединяет ассемблеры то, что они не создают никаких дополнительных языковых конструкций (кроме разве что каких-то макросов для удобства). Ассемблерный синтаксис напрямую соответствует машинным инструкциям.
Память и адреса
Можно видеть, что машинная инструкция "100, 1000, 5" занимает 3 числа, а "101, 5" только 2. То есть инструкции могут быть длинными или короткими.
Процессор понимает длину инструкции по её коду. Если он видит код 100, он знает, что за ним идёт ещё адрес памяти и значение, а если видит код 101, то знает, что это работа с регистром, который уже указан в самом коде, и дальше требуется только значение.
Поэтому инструкции записываются просто подряд:
100, 1000, 5, 101, 5, ....
А процессор считывает их так же, как магнитофонная головка читает данные с движущейся магнитной ленты. Прочитав очередную инструкцию, процессор попадает на начало следующей и т.д.
А это приводит нас к интересному результату. Если мы смотрим код на высокоуровневом языке (иллюстрация для примера, вникать необязательно):
То создаётся впечатление, что он существует где-то сам по себе, как красивая абстракция.
В то время как код на языке ассемблера – это непосредственно содержимое памяти компьютера, которое мы видим, как хирург, разрезающий пациента на операционном столе.
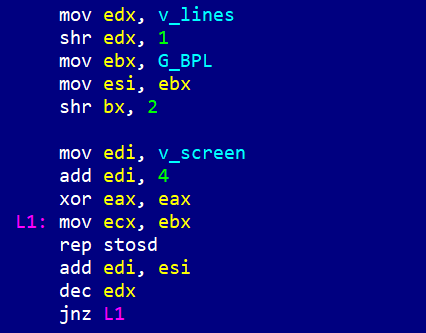
Мы можем буквально сосчитать, сколько байт находится между меткой L1 и инструкцией jnz L1.
А также понять, как происходит управление циклами в самом незамутнённом виде. Процессор всегда читает инструкции подряд, и рано или поздно он дойдёт до инструкции:
jnz L1
Она переводится как jump if not zero. То есть, прыжок на метку L1, если не было нуля. Какого нуля? Для этого надо посмотреть на предыдущую инструкцию:
dec edx
Она уменьшает регистр edx на 1. Если после этого в регистре получился 0, то будет активирован специальный флаг процессора Z, который активируется после любой операции с нулевым результатом. Соответственно, инструкция jnz будет ориентироваться на этот флаг – он 0 или не 0? Если не 0, процессор перейдёт на метку L1 и продолжит выполнение оттуда. Это равносильно тому, что магнитную ленту отмотали немного назад, и головка стала считывать те же инструкции повторно.
Так работают условия. Посудите сами: любое условие предполагает две версии кода: одна, которая должна выполниться, и другая, которая не должна. Но обе эти версии существуют в виде цепочек инструкций, которые можно расположить только последовательно. Нельзя нормальным путём попасть на вторую, если впереди находится первая. Можно только перепрыгнуть на неё, то есть перемотать ленту вперёд или назад. Это и делают инструкции прыжков. В языках высокого уровня они называются GOTO, и ими запрещено пользоваться, но в машинных кодах нет ничего, кроме них.
- jmp – просто прыжок (чистый GOTO)
- jz – прыжок если 0
- jnz – прыжок если не 0
- jg – прыжок если больше
- jl – прыжок если меньше
- jge – прыжок если больше или равно
- jle – прыжок если меньше или равно
Это лишь часть условных переходов, которыми машинные инструкции очень богаты и имеют очень специфичные условия, недоступные в языках высокого уровня – например, проверку бита чётности.
Вообще говоря, метка L1 это некий адрес. То есть для прыжка на адрес 1000 мы могли бы написать:
jmp 1000
Но очевидно, высчитывать адреса вручную неудобно, поэтому язык ассемблера позволяет ставить символические метки, которые он затем сам транслирует в нужные адреса.
То же касается и названий переменных. Мы можем зарезервировать какой-то адрес в памяти под переменную, но чтобы не писать именно адрес, мы можем дать ему какое-то условное имя.
Математика
Мы можем написать формулу вроде:
c = a * 3 + b / 2 - 1
В ассемблере каждая операция умножения, сложения и т.п. это отдельная машинная инструкция, поэтому такое выражение вычислить за один раз невозможно. Мы должны вручную разбить его на отдельные операции:
mov ax, a
mul ax, 3
Это мы вычислили a * 3 и результат остался в регистре ax.
mov bx, b
div bx, 2
Это мы вычислили b / 2 и результат остался в регистре bx.
Теперь надо всё сложить. Для этого будем использовать адрес переменной c. Сначала поместим туда результат из ax:
mov c, ax
Затем добавим результат из bx:
add c, bx
Затем отнимем 1:
sub c, 1
Но можно оптимизировать, используя как можно больше регистровых операций, так как они быстрее:
add ax, bx
dec ax
mov c, ax
Заключение
Если вы пишете на ассемблере, то
- Вам надо знать набор инструкций конкретного процессора
- Вы должны вручную резервировать память для каждой переменной
- Вы пишете машинный код в немного очеловеченном виде
- Вы видите код как непосредственное содержимое памяти компьютера
- Из управляющих конструкций у вас есть только переходы
- Математические действия надо разбивать на примитивы
- Регистры – ваши друзья
Читайте дальше: