Временная сложность
O(nlogn) в худшем, среднем и лучшем случае, где n — количество элементов в массиве:
- Алгоритм делит массив пополам на каждом уровне рекурсии, что дает логарифмическую составляющую logn.
- На каждом уровне рекурсии происходит слияние n элементов, что дает линейную составляющую n.
Пространственная сложность
O(n), так как для слияния двух подмассивов требуется временный массив того же размера, что и исходный.
Идея
Сортировка слиянием является примером алгоритма "разделяй и властвуй":
- Разбиваем массив на подмассивы до тех пор, пока каждый подмассив не будет состоять из одного элемента или будет пустым.
- Рекурсивно сливаем подмассивы вместе таким образом, чтобы они были отсортированы.
Функция sort
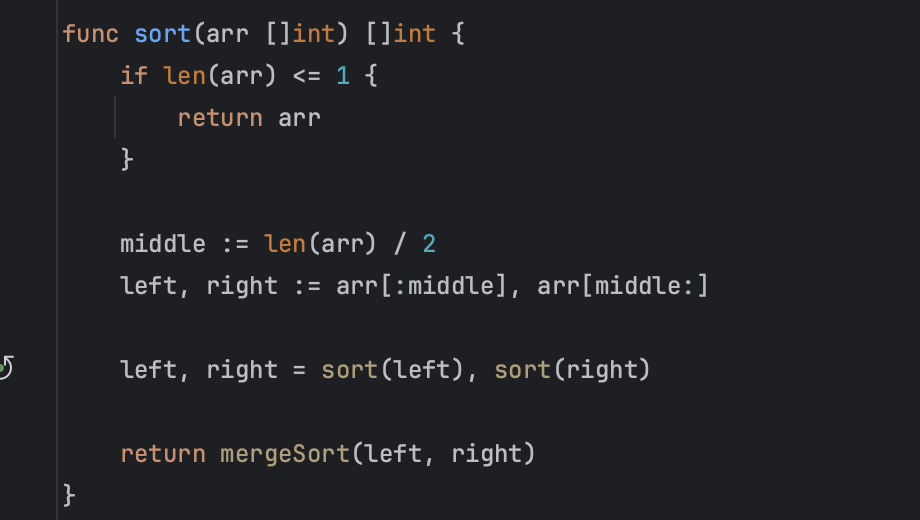
1. Условие выхода из рекурсии: если массив содержит ноль или один элемент, он уже отсортирован, возвращаем его.
2. Находим середину массива и делим его на два подмассива: left и right.
3. Рекурсивно вызываем функцию sort для сортировки подмассивов.
4. Используем функцию mergeSort для слияния отсортированных подмассивов в один результирующий отсортированный массив.
Функция mergeSort
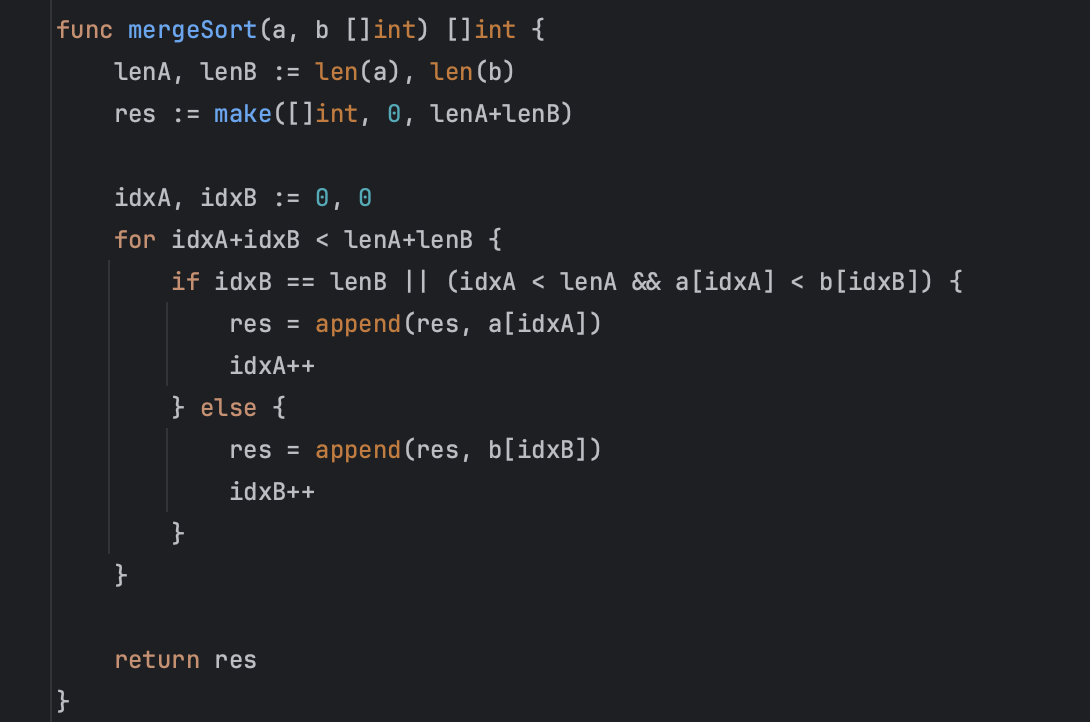
1. Создаем результирующий массив res, размер которого равен сумме длин двух входных массивов a и b.
2. Индексы idxA и idxB инициализируем нулями. Они будут использованы для итерации по элементам массивов a и b соответственно.
3. Цикл for выполняется до тех пор, пока сумма idxA и idxB меньше суммы длин lenA и lenB.
4. Внутри цикла проверяем составное условие:
- если idxB равен lenB, то все элементы из массива b уже добавлены в результат, или
- если текущий элемент из массива a меньше текущего элемента из массива b и idxA меньше lenA, то есть оставшиеся элементы в a для сравнения
5. Если предыдущее условие выполняется, то в res добавляем элемент из a и увеличиваем idxA на единицу.
6. В противном случае, в res добавляем элемент из b и увеличиваем idxB на единицу.
Когда цикл завершается, все элементы из массивов a и b слиты в res в отсортированном порядке. Возвращаем res.
Примеры использования
1. Сортировка больших объемов данных: Так как временная сложность постоянна O(nlogn), алгоритм хорошо подходит для сортировки больших объемов данных, особенно когда данные не помещаются в память и требуются алгоритмы сортировки на внешних носителях (external sorting).
2. Сортировка связных списков: Так как не требует доп. затрат памяти для перемещения элементов, как в случае с массивами.
3. Обработка данных в многопоточных и распределенных системах: Алгоритм адаптируется к параллельной обработке, позволяя выполнять сортировку подмассивов в разных потоках или на разных узлах в распределенной системе, а затем сливать результаты.
Пример: Задача MapReduce, где фаза Map выполняет локальную сортировку, а фаза Reduce сливает все локально отсортированные данные.
4. Стабильная сортировка: В отличие от, например, быстрой сортировки сортировка слиянием стабильная и сохраняет относительный порядок равных элементов.
Пример: Есть база данных с записями о сотрудниках, где каждый сотрудник имеет атрибуты, такие как отдел и стаж работы. Нужно отсортировать сотрудников по отделу и затем по стажу работы, сохраняя относительный порядок сотрудников внутри каждого отдела. Сортировка слиянием гарантирует, что если два сотрудника имеют одинаковый стаж работы, они останутся в том же порядке относительно друг друга, в каком были до сортировки.
5. Сортировка списков с неизвестной длиной: Когда длина массива неизвестна или он представлен потоком данных, сортировка слиянием может быть адаптирована для работы в таких условиях.
Пример: Данные поступают в потоковом режиме, например, показания с датчиков в реальном времени. Нужно отсортировать их по мере поступления, но мы не знаем общее количество данных заранее. Сортировка слиянием обрабатывает данные по мере поступления и сливает новые данные с уже отсортированной последовательностью, сохраняя эффективность алгоритма.