Доброго времени суток, читатели, зрители моего канала programmer's notes. Не забывайте подписываться и писать свои комментарии к моим статьям и видео.
Это приложение к видео (см. Приложение 1, Приложение 2, Приложение 3, Приложение 4)
Примеры использования регулярных выражений на Python
В данной статье рассмотрим несколько примеров с использованием регулярных выражений. Надеюсь они помогут вам разобраться в этом интересном языке.
Первое слово в предложении
Приведу варианты получения первого слова в предложении.
Вариант 1.
#!/usr/bin/python3
import re
s = 'Съешьте еще этих вкусных булочек'
pt =r'\w+'
m = re.match(pt, s)
print(m.group())
Вариант 2.
#!/usr/bin/python3
import re
s = 'Съешьте еще этих вкусных булочек'
pt =r'\w+'
m = re.findall(pt, s)
print(m[0])
Вариант 3.
#!/usr/bin/python3
import re
s = 'Съешьте еще этих вкусных булочек'
pt =r'^\w+'
m = re.findall(pt, s)
print(*m)
Мне кажется никаких пояснений данные примеры не требуют.
Последнее слово в предложении
Также три варианта поиска представлены ниже
Вариант 1.
#!/usr/bin/python3
import re
s = 'Съешьте еще этих вкусных булочек'
pt =r'\w+$'
m = re.search(pt, s)
print(m.group())
Вариант 2.
#!/usr/bin/python3
import re
s = 'Съешьте еще этих вкусных булочек'
pt =r'\w+'
m = re.findall(pt, s)
print(m[-1])
Вариант 3.
#!/usr/bin/python3
import re
s = 'Съешьте еще этих вкусных булочек'
pt =r'\w+$'
m = re.findall(pt, s)
print(*m)
Также, я надеюсь, пояснений не потребуется
Выделение подстрок и слов из строки
Пример 1.
Получить домены из email-адресов.
#!/usr/bin/python3
import re
pt = r'@(\w+)\.(\w+)'
s = 'qwerty@ert.com'
m = re.search(pt, s)
print(m.group(1), m.group(2))
Результат выполнения
ert com
Довольно часто встречаемые задачи, когда нужно выявить слова из строки.
Пример 2.
Дан текст. Требуется выделить слова, состоящие из букв, цифр, а также возможно нижних подчёркиваний. Естественно вспоминаем про '\w'. И вроде бы всё просто, но есть ещё одно дополнительное условие. В слове могут быть черточки. Одна или две. Чёрточки не могут стоять рядом. Черточка не может быть первым или последним символом.
Решение представлено ниже
#!/usr/bin/python3
import re
s = 'Съе-шь-те, еще эт - их ,,, вку--сных булочек..-Пожалуйста-'
pt =r'((?:[\w]+[-]?[\w]+[-]?[\w]+)|(?:[\w]+[-]?[\w]+)|(?:[\w]+))'
m = re.findall(pt, s)
print(*m)
Результат выполнения
Съе-шь-те еще эт их вку сных булочек Пожалуйста
Напомню, что '[\w]+' это произвольная последовательность букв, цифр и подчёркиваний. В представленном выше регулярном выражении приходится описывать три варианта слов: без чёрточки, с чёрточкой и с двумя черточками. Но у нас есть связка ИЛИ и это всё решает.
Пример 3.
Задание такое же как и в примере 1. Но нужно выбрать слова, которые не входят в указанный набор слов. И тут следует сделать одно важное замечание. Не стоит ломать себе голову над тем, как написать регулярное выражение, которое бы давала точное описание искомого множества строк. Иногда это довольно сложно, а иногда и не возможно совсем. Разбейте отбор строк на два этапа. В первым для поиска вы определяете шаблон, который описывает более широкий спектр строк, но куда однозначно должны попасть искомые строки. А на втором этапе опять же с помощью регулярного выражения или средствами языка программирования (например Python) отбрасываете не нужные строки. Уверяю вас, это гораздо проще и надёжнее. В нашем же примере вообще в общем случае нельзя написать точный шаблон. Поэтому и решим задачу в два этапа.
#!/usr/bin/python3
import re
st = {'ещё', 'их'}
s = 'Съе-шь-те, ещё эт - их,,, вку--сных булочек. '
pt =r'((?:[\w]+[-]?[\w]+[-]?[\w]+)|(?:[\w]+[-]?[\w]+)|(?:[\w]+))'
m = re.finditer(pt, s)
print(*[t.group() for t in m if t.group() not in st])
Результат выполнения
Съе-шь-те эт вку сных булочек
Однобайтовые числа
Часто приходится выделять числа из текста. Ну это не так сложно, но могут быть дополнительные условия.
Пример 1.
Найти все однобайтовые числа в тексте. При этом, естественно они не могут быть частью других целых чисел.
И вот здесь следует обратиться к тому, что я написал выше. Не стоит ломать голову над тем как написать регулярное выражения для выявления таких однобайтовых чисел. Нужно выявить все целые числа, а потом проверить их величину или сравнить с ещё одним регулярным выражением, которое определяет однобайтовое число.
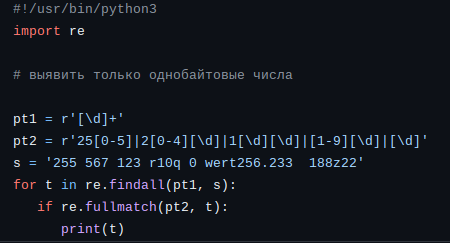
Результат выполнения
255
123
10
0
233
188
22
В данном примере pt2 является шаблоном, определяющим, что данная строка представляет из себя однобайтовое число в десятичном представлении. Конечно, можно было сделать ещё проще: проверить значение int(t), но хотелось не много поиграть в регулярные выражения, конечно.
Пример 2.
В приложении 2 мы выявляли выражения похожие на ip-адреса. Давайте усилим алгоритм и точно определим является ли данная строка ip-адресом.
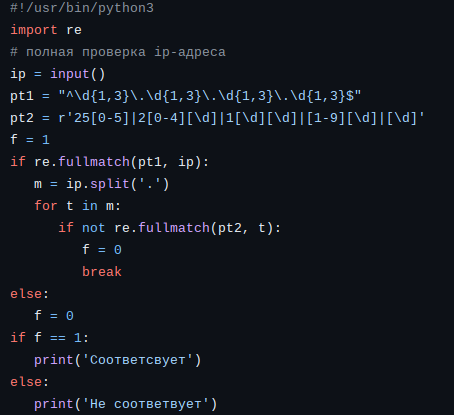
Строка - претендент на проверку вводится из командной строки. Проверка того, что строка представляет ip-адрес проводится опять же в два этапа. И опять же на втором этапе проще было проверять преобразовав строку в целое число. Но хотелось лишний раз использовать регулярное выражение, так как статья им и посвящена.
Хорошего программирования. Оставляйте свои комментарии, не забывайте про лайки и подписывайтесь на мой канал programmer's notes.