Рассмотрим один из передовых методов кластеризации - DBSCAN. Для многих исследователей эффективность метода зачастую компенсируется сложностью его настройки, из-за чего предпочтение отдается другим алгоритмам. Давайте внесем ясность в вопрос и упростим использование DBSCAN.
Основные параметры алгоритма, которые меняются от задачи к задаче:
- eps - расстояние;
- min_samples - количество точек.
Они определяют 3 вида точек:
- ядерные (основные) - на расстоянии eps находится не менее min_samples точек;
- граничные - не ядерные, но на eps расстоянии от них есть ядерные;
- выбросы - остальные точки.
Далее формируются отдельные кластера для каждой группы достижимых на расстоянии eps ядерных точек (возможно, одной). Граничным точкам соответствует кластер ближайшей (либо для экономии времени первой найденной в ее окрестности) ядерной точки.
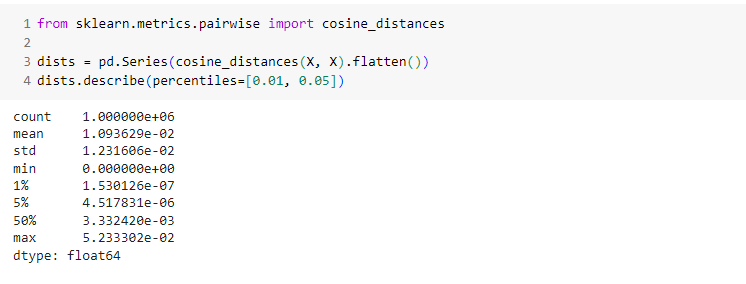
min_samples обычно задают исходя из минимального желаемого размера кластера. А для оценки eps разумно получить статистические показатели, а также гистограмму расстояний.
Для демонстрационных целей создадим набор из трех кластеров точек (о том как подробнее читай тут):
Для оценки расстояний можно вывести их квантили, вряд ли в качестве eps нам будет интересно значение более 10-20% квантили (если только не хотите получить очень малое число кластеров):
Также информативна гистограмма расстояний:
Еще удобно вывести график изменения средних расстояний от каждой точки до min_samples ближайших.
Отмечу, что при большом размере датасета, все эти статистики лучше выводить для случайной подвыборки данных:
eps разумно выбрать в точке изгиба графика.
Теперь обучим модель:
Вот как кластеризованы данные:
Розовые точки - выбросы:
Как можно заметить, алгоритм помечает выбросы "-1", то есть может использоваться не только для кластеризации, но и для обнаружения аномалий. В целом касательно параметров алгоритма и его особенностей можно сделать вывод, что для eps слишком маленьких большая часть данных не будет кластеризована, а для больших кластеры будут сливаться.
Также отмечу, что DBSCAN не сможет хорошо кластеризовать наборы данных с большой разницей в плотности, так как параметры eps и min_samples едины.