Доброго времени суток, читатели, зрители моего канала programmer's notes. Не забывайте подписываться и писать свои комментарии к моим статьям и видео.
Это приложение к видео (см. Приложение 1, Приложение 2, Приложение 3)
Python. Группировка в регулярных выражениях
Сегодня продолжаем работать с регулярными выражениями. Тема данной статьи группировка. С помощью круглых скобок можно выделить отдельные символы регулярного выражения, в результате выражение в скобках будет обрабатываться отдельно от всего выражения. Такие скобки называются ещё захватывающими.
Группировка или захватывающие скобки в регулярных выражениях на языке Python
Начнём наше рассмотрения с простого примера.
#!/usr/bin/python3
import re
pt = r'ababab'
s = 'weqwabewqeqabababerttababqqqab111'
m = re.findall(pt, s)
print(*m)
Результат выполнения
ababab
Ну это и следовало бы ожидать, ведь мы ищем конкретную подстроку и она присутствует в строке один раз.
Что в первую очередь приходит в голову. Строка 'ababab' состоит из повторений 'ab'. Их всего 3, но ведь может быть и 30. Нельзя ли сократить запись регулярного выражения? Просто напрашиваться написать так '(ab){3}'. Ну логично ведь, да?
#!/usr/bin/python3
import re
pt = r'(ab){3}'
s = 'weqwabewqeqabababerttababqqqab111'
m = re.findall(pt, s)
print(*m)
Результат выполнения
ab
Ой, что же это значит?
И вот здесь очень интересно. Показано то, что найдено в скобках. Т.е. поиск вот этой группы, которая обозначается круглыми скобками. Однако найдено один раз, что соответствует поиску 'ababab'. Т.е. поиск осуществился по 'ababab', но результат выдан по значению в скобках, т.е. по указанной группе. И наконец перепишем программу так
#!/usr/bin/python3
import re
pt = r'((ab){3})'
s = 'weqwabewqeqabababerttababqqqab111'
m = re.findall(pt, s)
print(*m)
Другими словами у нас появилась группа, которая охватывает всё выражение. Результат выполнения
('ababab', 'ab')
Т.е. мы получили результат по двум группам, но поиск осуществлялся по полному выражению.
Чтобы было ещё понятнее можно переписать программу вот так.
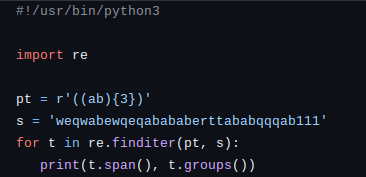
Результат выполнения
(11, 17) ('ababab', 'ab')
При этом метод span() выдаёт кортеж найденных координат, groups() результаты по всем группам, а их у нас две. По координатам понятно, что найдена именно результирующая строка.
Обратимся теперь к примеру из приложения 3.
#!/usr/bin/python3
import re
s = 'lo = 3456;qwerty lo = 3 ; fdsdlo=33;\
ot=456;'
pt = r'\blo[ ]*=[ ]*[0-9]+[ ]*;|\bot[ ]*=[ ]*[0-9]+[ ]*;'
m = re.findall(pt, s)
print(m)
Результат выполнения
['lo = 3456;', 'lo = 3 ;', 'ot=456;']
Регулярное выражение несколько длинновато. И как и раньше приходит мысль, что для сокращения выражения нужно использовать скобки. Например так
#!/usr/bin/python3
import re
s = 'lo = 3456;qwerty lo = 3 ; fdsdlo=33;\
ot=456;'
pt = r'((\blo[ ]*|\bot[ ]*)=[ ]*[0-9]+[ ]*;)'
m = re.findall(pt, s)
print(m)
Результат выполнения будет
[('lo = 3456;', 'lo '), ('lo = 3 ;', 'lo '), ('ot=456;', 'ot')]
Вот так здорово. Мы получили сами выражения и ключи. Это результат работы группы. А что если пойти ещё дальше
#!/usr/bin/python3
import re
s = 'lo = 3456;qwerty lo = 3 ; fdsdlo=33;\
ot=456;'
pt = r'((\blo[ ]*|\bot[ ]*)=([ ]*[0-9]+[ ]*;))'
m = re.findall(pt, s)
print(m)
Результат выполнения
[('lo = 3456;', 'lo ', ' 3456;'), ('lo = 3 ;', 'lo ', ' 3 ;'), ('ot=456;', 'ot', '456;')]
В результате мы получили и полные выражения, и ключи, и их значения. И это сделали круглые скобки, разбивающие выражение на группы.
Полезная информация, правда?
Но по группам ещё не всё.
Подавить вывод информации по группе можно используя команду '?:'. Вот так
#!/usr/bin/python3
import re
pt = r'((?:ab){3})'
s = 'weqwabewqeqabababerttababqqqab111'
m = re.findall(pt, s)
print(*m)
Результат выполнения
ababab
Объект сопоставления (match(), search(), finditer())
Функции match(), search(), finditer() возвращают так называемый объект сопоставления, у которого имеется ряд полезных методов, некоторые из которых мы уже использовали. Пришло время дать не большую справку по ним.
- Match.expand() — содержимое найденной группы;
- Match.group() — группы совпадений;
- Match.groups() — кортеж, содержащий группы совпадений;
- Match.groupdict() — словарь с именованными группами;
- Match.start(), Match.end() — начало и конец группы;
- Match.span() — кортеж с началом и концом группы, номер 0 в качестве аргумента означает, что речь идёт о всей совпадающей строке;
- Match.pos, Match.endpos — индексы начала и конца совпадений;
- Match.lastindex — индекс последней найденной группы;
- Match.lastgroup — имя последней группы захвата;
- Match.string — строка, в которой осуществляется поиск.
Пример, показывающий смысл членов объекта, показан ниже
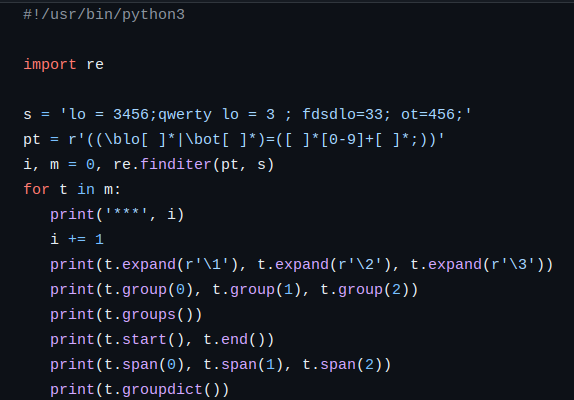
Результат выполнения программы
*** 0
lo = 3456; lo 3456;
lo = 3456; lo = 3456; lo
('lo = 3456;', 'lo ', ' 3456;')
0 10
(0, 10) (0, 10) (0, 3)
{}
*** 1
lo = 3 ; lo 3 ;
lo = 3 ; lo = 3 ; lo
('lo = 3 ;', 'lo ', ' 3 ;')
17 25
(17, 25) (17, 25) (17, 20)
{}
*** 2
ot=456; ot 456;
ot=456; ot=456; ot
('ot=456;', 'ot', '456;')
37 44
(37, 44) (37, 44) (37, 39)
{}
Пустые фигурные скобки означают, что у нас нет именованных групп. О том, как именовать группы, напишу в одном из следующих текстов.
Пожалуй теперь всё
Хорошего программирования. Оставляйте свои комментарии, не забывайте про лайки и подписывайтесь на мой канал programmer's notes.