Доброго времени суток, читатели, зрители моего канала programmer's notes. Не забывайте подписываться и писать свои комментарии к моим статьям и видео.
Статья является приложением к видео (см. Приложение 1)
Использование регулярных выражений в Python. Квантификаторы
Продолжаем заниматься регулярными выражениями. Сегодня речь пойдёт о квантификаторах. Ну и не только о них.
Квантификаторы позволяют указывать повторения конкретного символа или символа из группы. Давайте рассмотрим какие есть квантификаторы.
- {n} — повторять ровно n раз;
- {n, m} — от n до m повторений;
- {m,} — продублировать не менее m раз, {0,} — повторять от 0 и более;
- {,n} — продублировать не более n раз;
- * — синоним для {0,};
- + — синоним {1,};
- ? — 0 или один раз.
Пример 1
Очень простой пример выделения в тексте подстрок, похожих на дату типа День:Месяц:Год.
#!/usr/bin/python3
import re
pt = '[0-9]{1,2}:[0-9]{1,2}:[0-9]{4}'
s = 'ADAsd12:11:2003fssa9:2:1999'
print(*re.findall(pt, s))
Результат
12:11:2003 9:2:1999
Данный пример регулярного выражения несовершенен. Его можно подкорректировать, несколько удлинив. Но хотел бы заметить, уважаемые читатели, что не всегда удаётся чётко описать класс, описывающий нужные подстроки, так чтобы туда не попадали лишние значения. Но это абсолютно не страшно так как полученные результаты можно подвергнуть дополнительной фильтрации. В нашем случае легко потом отбросить даты с '00' днём и месяцем и годом с первой цифрой '0' (например). С другой стороны, представленное выше регулярное выражение можно и упростить, если заменить '[0-9]' на '\d'.
Пример 2
Простая проверка, что данная строка представляет собой (похожа) ip-адрес.
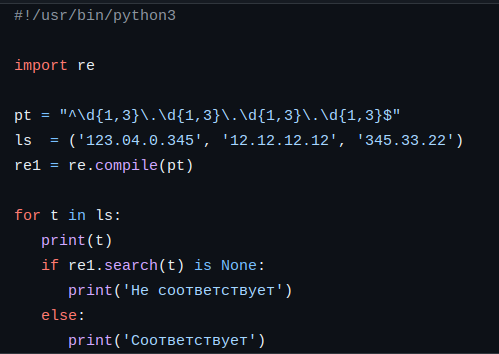
Результат выполнения
123.04.0.345
Соответствует
12.12.12.12
Соответствует
345.33.22
Не соответствует
Обратим внимание, что мы использовали символы '^' и '$' начала и конца строки (см. Приложение 1). Ну можно было просто использовать метод match().
И опять, конечно же, добавлю, что в данный класс попадут и строки, не соответствующие ip-адресам, например, 300.200.123.123. Но зато сюда попадут и реальные ip-адреса, которые мы потом сможем вычленить путем дополнительного анализа.
Добавлю также, что в последнем примере мы откомпилировали регулярное выражение и получили объект, который потом использовали, а можно было как и раньше использовать, например, re.search().
Пример 3.
Следует иметь в виду, Python может интерпретировать строку в связи с тем, что там могут быть управляющие символы для строк Python. Чтобы не думать о таких проблемах следует использовать известным нам префикс r (r-строки).
Рассмотрим следующую программу. Найти в тексте все слова, начинающиеся на определённую букву.
#!/usr/bin/python3
import re
pattern = r'\b[Bb]\w+'
s = "j;k sdfd bdfg dfdg Bdddd bdd"
wd = re.findall(pattern, s)
print(*wd)
Результат выполнения
bdfg Bdddd bdd
Правильный, но если мы уберём префикс r, то результата не будет. Так что продолжим наше изучение регулярных выражений, но уже используя "правильные" строки.
Напомню в связи с последним примером, что '\b' обозначает границу слова, а '\w' любую букву, цифру или знак подчёркивания.
Пример 4.
Найти все слова в строке
#!/usr/bin/python3
import re
s = 'После своего объяснения с женой Пьер поехал в Петербург. \
В Торжке на станции не было лошадей, или не хотел их дать \
смотритель. Пьер должен был ждать.'
pt = r'[а-яА-Яa-zA-Z0-9]+'
f = re.findall(pt, s)
print(f)
Результат выполнения
['После', 'своего', 'объяснения', 'с', 'женой', 'Пьер', 'поехал', 'в', 'Петербург', 'В', 'Торжке', 'на', 'станции', 'не', 'был
о', 'лошадей', 'или', 'не', 'хотел', 'их', 'дать', 'смотритель', 'Пьер', 'должен', 'был', 'ждать']
Можно, конечно, использовать и более простой вариант регулярного выражения
r'\w+'
Пример 5.
В программе ниже показан пример работы метода search(). В результате работы программы мы получаем начало и конец отрезка, соответствующего заданному шаблону. В программе показано получения первых двух строк.
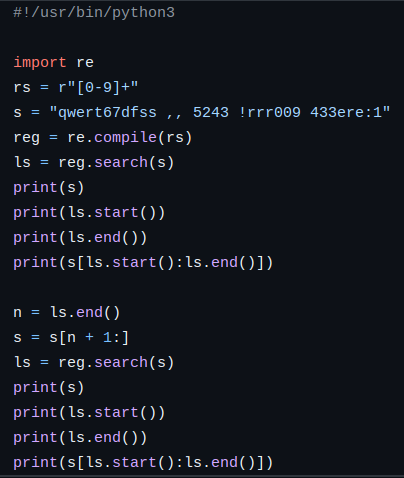
Результат выполнения программы
qwert67dfss ,, 5243 !rrr009 433ere:1
5
7
67
fss ,, 5243 !rrr009 433ere:1
7
11
5243
Обращаем внимание на методы start() и end() объекта, полученного в результате работы функции search().
Пример 6.
Приведу один из вариантов регулярного выражения для выделения в тексте email-адресов.
Пример, конечно, не идеален. Попробуйте его усовершенствовать и дайте свой вариант.
Продолжение о регулярных выражениях см. здесь...
Хорошего программирования. Оставляйте свои комментарии, не забывайте про лайки и подписывайтесь на мой канал programmer's notes.