Доброго времени суток, читатели, зрители моего канала programmer's notes. Не забывайте подписываться и писать свои комментарии к моим статьям и видео.
Статья является приложением к видео
Регулярные выражения и Python. Часть 1
Регулярные выражения не относятся к конкретному языку программирования. Это общий подход для написания шаблонов, которые обозначает группу строк. Если шаблон написан, то его можно использовать так, если бы это была конкретная строка, т.е. осуществлять поиск, разбиение строки на подстроки, удаление подстрок.
В регулярном выражении есть символы двух типов:
- обычные символы, которые представляют самих себя;
- специальные символы (метасимволы), которые обозначают нечто иное или меняют смысл последующих символов (определяют начало специальных последовательностей).
Например '1' это просто символ обозначающий цифру 1. А символ '.' обозначает любой символ. Особую роль играет символ '\'. Во-первых, он меняет свойства некоторых обычных символов, так что они начинают обозначать целую группу. Например '\d' обозначает любую десятичную цифру. С другой стороны '\' используется для экранирования специальных символов, чтобы они представляли в регулярном выражении самого себя. Например '\.' представляет обычную точку, а '\\d' обозначает последовательность двух обыкновенных символов: '\' и 'd'.
Заметим, что строка, в которой нет специальных символов, также является регулярным выражением.
В данном статье мы рассмотрим простые регулярные выражения и их использование.
Ниже представлена таблица основных специальных символов. Другие специальные символы будут представлены в следующих статьях по теме регулярные выражения.
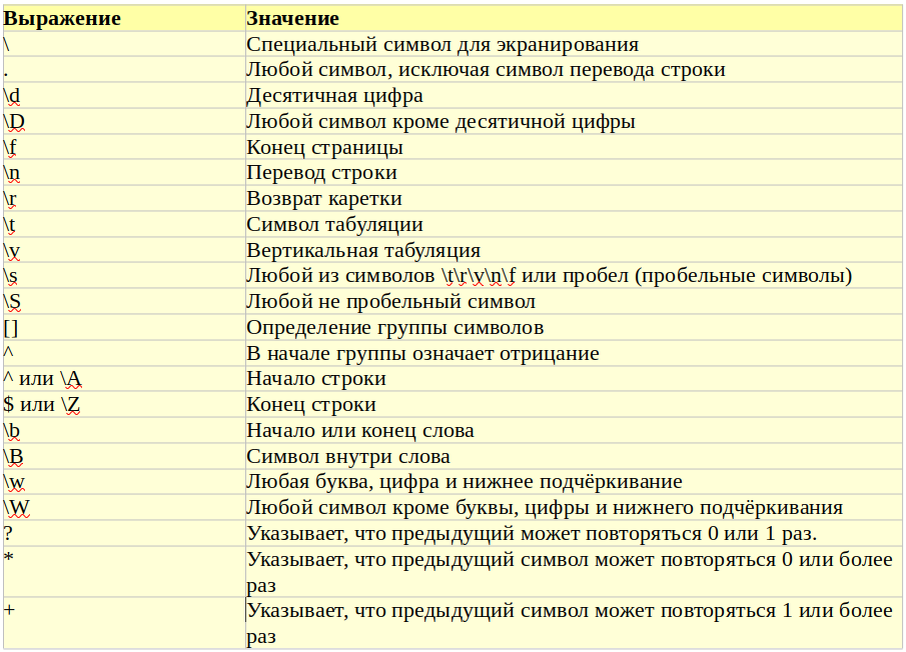
Для использования регулярных выражений имеется стандартная библиотека re, которая подключается стандартным образом import re. Ниже в таблице представлены функции библиотеки.
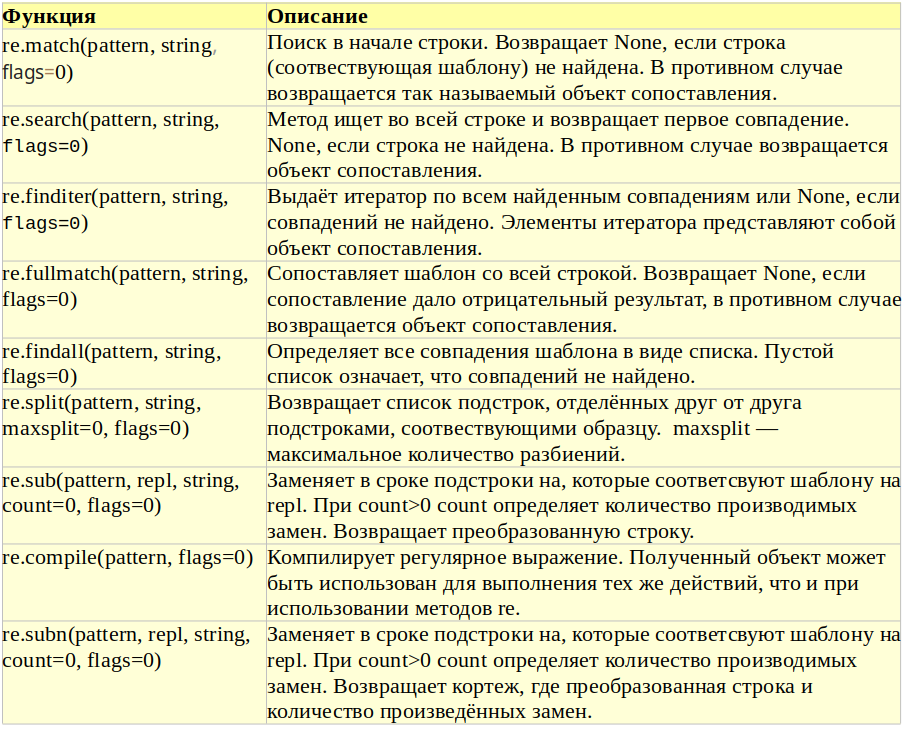
Рассмотрим ряд примеров использования регулярных выражений.
Пример 1.
Получение всех цифр в строке
#!/usr/bin/python3
import re
pt = '\d'
s = 'qw34ryge896gsd3 r5'
mt = re.findall(pt, s)
print(*mt)
Результат выполнения
3 4 8 9 6 3 5
Т.е. мы получили все цифры, содержащиеся в строке.
Как мы уже отметили '\d' обозначает любую цифру. Использую квадратные скобки можно вместо '\d' использовать '[0123456789]' или '[0-9]'. Впрочем, в данном случае это просто удлиняет выражение и не даёт никаких преимуществ.
Пример 2.
Рассмотрим вариант, когда разделитель это три возможных разных символа
#!/usr/bin/python3
import re
pt = '[abc]'
s = 'zxaqqbwwcee'
mt = re.split(pt, s)
print(*mt)
Результат выполнения
zx qq ww ee
Несколько видоизменим предыдущий пример
Пример 3.
#!/usr/bin/python3
import re
pt = '1[abc]'
s = 'zx1aqq1bwwcee1c456'
mt = re.split(pt, s)
print(*mt)
Результат выполнения
zx qq wwcee 456
Пример 4.
Разные варианты написания слова 'ха-ха'
#!/usr/bin/python3
import re
pt = '[хХ][аА]-[хХ][аА]'
s = 'ха-ха - вот мой вам ответ, ХА-ХА, Ха-Ха'
mt = re.findall(pt, s)
print(mt)
Результат выполнения
['ха-ха', 'ХА-ХА', 'Ха-Ха']
Пример 4a.
Если нужно получить координаты найденных подстрок используем удобный итератор re.finditer().
#!/usr/bin/python3
import re
pt = '[хХ][аА]-[хХ][аА]'
s = 'ха-ха - вот мой вам ответ, ХА-ХА, Ха-Ха'
print(*[t.span() for t in re.finditer(pt, s)])
Результат выполнения
(0, 5) (27, 32) (34, 39)
Т.е. мы получили кортежи начального и конечного индекса найденных подстрок. Это более удобная вещь, чем findall().
Важное замечание
По умолчанию поиск регулярных выражений касается непересекающихся подстрок. Для получения пересекающихся подстрок следует использовать специальные приёмы из регулярных выражений или использовать другую библиотеку. Но это уже совсем другая история, к которой мы обязательно обратимся в своё время.
В данной статье, мы привели очень простые примеры регулярных выражений. В следующих статьях материал будет постепенно усложняться.
Продолжение о регулярных выражениях здесь...
Хорошего программирования. Оставляйте свои комментарии, не забывайте про лайки и подписывайтесь на мой канал programmer's notes.