
Введение, развитие state менеджера redux
Всем привет, меня зовут Александр, я являюсь фронтенд разработчиком с 4-х летним опытом работы. В этой статье я хочу поделиться своими наблюдениями, как эволюционировали state manager и их взаимодействие по работе с апи, мой опыт работы с ними. Примечание, эта статья не является гайдом по настройке state менеджеров.
С начала моего пути в мире фронтенда я изначально попал в команду, где использовался redux, а для работы с апи использовалась redux-saga.
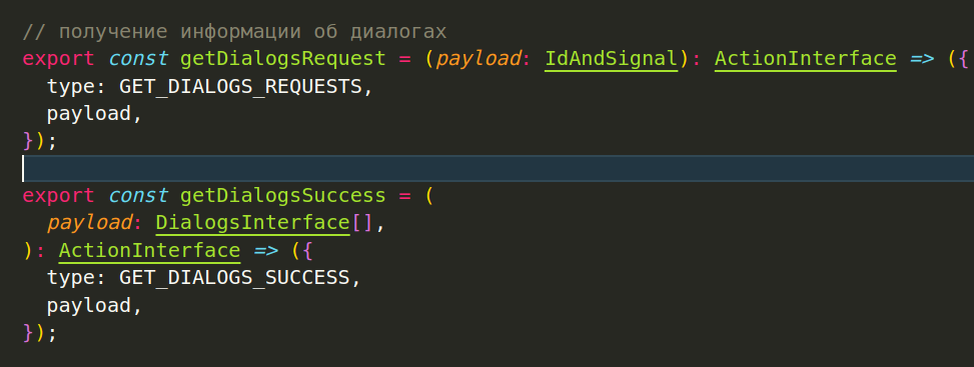
Давайте посмотрим в рамках ретроспективы, по какому принципу работал redux в то время. Сначала создавался экшн с уникальным типом в payload, пример таких экшенов можно увидеть на картинке «Пример экшена». Когда экшн был прописан, то его можно было вызвать в компоненте или хуке через dispatch. После того, как экшн вызвали, в store происходят изменения, которые отслеживаются по типу, который ранее был задан в payload. Сам глобальный storeсостоит из нескольких файлов reducer и его реализация и принцип работы до сих не поменялся и будет описан позже, а вот концепция хранения данных в файлах reducer в то время была другая и ее реализацию можно увидеть на картинке «Пример reducer». На примере в картинке видно, что в reducer поступает экшн с заданным типом, а в конструкции switch прописаны сценарии для каждого типаэкшена. В итоге получаем, что при совпадении того или иного сценария с экшеном будет отработанопрописанное действие.
Если вызываемый тип также содержался в saga, то он также отрабатывал, пример реализации saga можно увидеть на картинке «Пример саги (воркера)». На картинке можно увидеть функцию, которая экспортируется по умолчанию, ее название на практике может быть любым. В ней содержится функция takeEvery(), она принимает в себя два аргумента: тип экшена и колбек для него. То есть, когда вызывается экшен, то он отрабатывает сначала в сторе, а потом отлавливается в этом файле. В saga роль сценария отыгрывает колбек, если проводить аналогию с файлом reducer, который указывается вторым агрументом.
У этой конструкции были и минусы: много кода нужно было прописать для настройки работы и если проект был большим, то его потом было тяжело поддерживать. По первому аргументу — это была болезнь redux в тот момент, а вот второе — это мои кривые руки и недостаток опыта в то время.
Вся конструкция эксплуатировалась мной на протяжении двух лет. Мне было ее достаточно и я не хотел переезжать на новый redux toolkit, потому что лень было переучиваться.После того, как я перешел в новую компанию, то мне пришлось изучить redux toolkit, т. к. он использовался на основном проекте. Взаимодействовал я с ним в малой степени, в основном через санки. А работа с запросами происходила через функцию, которая была прописана и протестирована до меня, то есть я использовал готовое решение и не парился с этим.
В redux toolkit работа reducer была серьезно переработана.
Было время, когда использовали утилиту для redux под названием redux-actions. Суть заключалась в том, что с помощью функции createAction создавался экшн. Таких экшенов может быть как один, так и несколько. После этого в handleActions эти экшены выступают в роли ключа и описывают логику. В результате выполнения handleActions на выходе получается редюсер со своим внутренним стейтом, который необходимо добавить в глобальный стор. Есть еще combineActions, но я с ним сталкивался всего пару раз, поэтому не могу сказать, какое преимущество в работе он дает. Это первое, что я увидел после того, как ушел от использования стандартного подхода redux через switch, который был описан ранее. Одной из проблем redux-actions была плохо прописанная типизация для typescript.
Далее был обновлен redux до redux toolkit. У него появилось много своих плюшек, которые облегчали взаимодействие с ним. Одними из таких плюшек является slice и адаптары. С помощью слайса можно задать имя своему стору, начальное состояние и экшены для работы с редюсером. Адаптары, в свою очередь, очень помогаю структурировать код в однотипном порядке и генерировать однотипные экшены, чтобы каждый раз не прописывать их создание заново.
На данный момент времени я остановился на redux toolkit с его slice и адаптарами, но вопрос с работой апи для еще не закрыл до конца.
В таком темпе я проработал еще два года. За это время я не ничего нового в этом направлении не находил. Этим летом мне предложили создать новый проект, но по итогу мне пришлось передать его своему коллеге, потому что у меня был отпуск по расписанию. Когда я вернулся из отпуска, то для себя открыл rtk query, это было решение на основе redux для работы с апи и взглянуть на работу с ним с новой точки зрения. В ней мне впервые получилось познакомится с кешированием запросов на стороне клиента, зависимостью между запросами, обработка вызовов и ответа на них. Особое внимание хочу уделить зависимости между запросами и описать, как это работает. Возьмем любой рабочий пример с запросом типа post/put на создание редактирование записи из какого-то списка, в большинстве случаев после этой операции необходимо выполнить запрос на получение обновленного списка. Если раньше это нужно было делать руками, то теперь для этого достаточно прописать зависимость между двумя этими вызовами.
Такое поведение добивается за счет использования тегов. У меня в работе пока такой необходимости не было, поэтому примеров с кодом у меня на руках нет. Чтобы показать пример рабочего воспользуюсь кодом из документации.
На примере выше видно, что все используемые теги прописываются в свойстве tagTypes, далее в настройках запроса необходимо их прописать в provideTags. Таким образом получается, что если данные будут не валидны, то их можно будет обновить через теги. Указать, что информацию нужно обновить через свойство invalidatesTags в настройке вызова. Более подробно опишу в следующих статьях об этом, а пока об этом можно почитать в официальной документации.
После того, как я познакомился с работой redux и rtk query я посчитал одновременно их преимуществом и недостатком то, что они являются единой системой. По началу я воспринял это как слабость с архитектурной точки зрения, потому что думал, что лучше использовать независимые друг от друга технологии построения глобального store и запросов.
В слепую я не стал себе доверять, ведь большинство людей, как раз использует связку redux с rtk query, плюс мой аргумент об взаимозаменяемости state менеджера и функционала по работе с апи разбивается об один факт — какова возможность, что на проекте будет необходимость поменять state менеджер или функционал по работе с апи? У меня было много проектов, но я ни разу в ходе долгой разработки не был вынужден менять менять вышеупомянутые технологии.
По итогу, я для себя пощупал еще альтернативы. Неплохим вариантом была связка state менеджера zustand и функционала по работе с апи react query. Но в конечном итоге, мой выбор пал на связку redux + rtk query, даже не смотря на мои внутренние осуждения себя самого.
Описание работы state manager в моем проекте
В своем блоге я решил вынести storeи общую логику, которая связана с ним вынести в папку store, ключевым файлом является store.ts.
Описание файла store:
- rootReducer - ключевой reducer, который содержит в себе глобальны store;
- setupStore — функция инициализации redux, передается аргументом в провайдер store-а;
- RootState — типизация для глобального стора;
- AppDispatch — типизация для dispatch.
Также для более комфортной работы я создал два хука для работы с redux:
- useAppDispatch — вспомогательный хук для вызова dispatch;
- useAppSelector — вспомогательный хук для работы с глобальным стейтом.
Теперь время перейти к описанию работы с апи. Здесь я решил называть файлы, которые содержат логику работы с апи сервисами. Это именование я подсмотрел на одном из курсов на ютубе, а для себя объяснил следующим образом: сервисы на стороне бекенда занимаются обработкой информации разного рода, почему бы эту концепцию не попробовать реализовать на стороне юая?
На данный момент я очень хочу опробовать это в текущей реализации.
Описание входящий аргументов в функцию createApi:
- reducerPath — название в глобальном store;
- baseQuery — базовый урл, по которому будет происходить запрос;
- endpoints — эндпоинты, по которым будет происходить запрос данных для работы на юай.
Одной из особенностей является query и mutation. Query используется для получения данных, mutation — для запросов, которые вызывают изменение данных на стороне бека, все запросы, кроме типа get. В моем примере реализован только mutation.
Теперь перейдем к случаю, когда rtk query необходимо использовать вместе с обычными санками. У меня такой случай произошел, когда начал продумывать как переписать на redux логику работы с access и refresh токенами. В текущей реализации у меня описаны следующие сценарии:
- нет access и refresh токенов;
- нет access токена и есть refresh токен;
- есть access токен, если он просрочен, то сразу обновляем его, если актуален refresh токен;
- возвращаем отрицательный результат, если ни одно условие не сработало (это сделано для обработки ошибок, если таковые будут или ни одно условие не сработало).
Почему в этом случае я не хочу воспользоваться измененной функцией для построения запроса? Для себя я нашел следующий ответ: слишком много условий пост обработки запросов.
Также, еще одним случаем, когда нужно использовать rtk query вместе с санками — это пагинация с бесконечным скролингом. Проблема заключается в том, что между первым, вторым и последующими запросами в rtk query нет возможности объединить результаты. То есть, если после первого запроса данных сразу пошел второй, то данные из второго запроса будут перетирать данные из первого. С этим ничего нельзя сделать, поэтому в этом случае необходимо создавать отдельное хранилище в сторе, в которое будет складываться все результаты запросов, которые отдают данные для работы со списком.
Рефакторинг работы с токенами на стороне юая
На стороне юая, одним из самых функционалов для работы были токены, мне было важно выделить их из модуля блога.
Как видно на картинке выше, все запросы на сторону бека я вынес в файл TokensSerivce, а все функции распределил в отдельные файлы ducks. Если описать структуру общими словами, то получается, что всю работу с вызовами берет на себя rtk query в файле сервисов, а вспомогательный функционал прописывается в санках.
Выводы
В этой статье я затронул множество тем:
- описал свою историю взаимодействия со state менеджерами;
- поиск альтернатив redux;
- показал работу rtk query на своем примере
- привел частный случай, когда rtk query лучше использовать в связи санками, чем прямое преобразование функции для запроса.
Надеюсь все выше перечисленные темы вас затронули и вы узнали для что-то новое.
Больше статей в моем блоге. Спасибо, что дочитали и до новых встреч в следующих статьях.