В продолжение написанного выше далее я перескажу вкратце, что предпринял автор проекта для его успешного завершения. Чтобы ускорить обработку и избежать ненужного взаимодействия с кодом Python во время выполнения, IP-блок должен самостоятельно перебирать пиксели и выводить все отрисованное изображение целиком. Есть два варианта, как этого можно достичь: либо записать массив значений итерации в память, используя IP-блок прямого доступа к памяти (AXI Direct Memory Access, DMA), перед обработкой и отображением картинки с помощью кода Python, либо передать уже полностью обработанный кадр в блок прямого доступа к памяти AXI Video (VDMA).
Для PYNQ предусмотрены библиотеки для взаимодействия с VDMA и обработки видео, включая ввод-вывод HDMI. Это открывает нам возможность потоковой передачи данных на выход HDMI, который присутствует на устройстве, сохраняя при этом возможность считывать кадры и в Jupyter notebook. Базовый оверлей доступен для скачивания вместе с названными библиотеками внутри репозитория PYNQ на странице Xilinx на GitHub. Далее будет использоваться подход, основанный на VDMA.
Основной файл Mandelbrot.cpp должен быть полностью переписан. Эти изменения, в свою очередь, должны быть отражены в файлах заголовка и тестбенча.
Библиотека hls_video.h включена в файл Mandelbrot.h, содержащий определения типов шаблонов, используемых для обработки видео. Требуемыми шаблонами являются hls::stream для определения выходных данных, hls::Mat для определения матрицы хранения выводимых данных и hls::Scalar для определения фрагмента данных в матрице.
Затем определяются новые типы, основанные на включенных типах шаблонов, с их описательными названиями, где AXI_STREAM представляет 32-разрядный потоковый интерфейс AXI, используемый для вывода изображения из синтезированного IP-блока в VMDA, RGB_IMAGE - изображение 1080p, которое может быть выведено через этот поток, а RGB_PIXEL - отдельный пиксель этого изображения, содержащий три 8-битных цветовых канала.
Функционально файл IP-блока Mandelbrot.cpp разделен на три отдельных метода, чтобы улучшить общую читаемость кода.
void mandelbrot(AXI_STREAM& OUTPUT_STREAM, Config& config)
- Функция верхнего уровня, которая обрабатывает ввод и вывод.
- Определяется новая переменная img, которая затем передается функции calculate для обработки перед выводом в OUTPUT_STREAM.
- Тип вывода AXI_STREAM вместе с pragma DATA FLOW позволяет передавать пиксели по мере готовности из IP-блока один за другим в переменную img для повышения производительности.
void calculate(Config& config, RGB_IMAGE& img)
- Содержит исходный код обработки, заключенный в два цикла for.
- Результат записывается в переменную img, предоставленную в качестве аргумента.
RGB_PIXEL getPixel(int& iteration, int& max_iteration)
- Возвращает RGB_PIXEL на основе предоставленного значения итерации.
- Цвет меняется с черного на зеленый, затем на белый и так повторяется по кругу.
- В особом случае, когда достигается значение max_iteration, выводится черный цвет.
- Эффективно выполняет интерполяцию между 512 различными оттенками зеленого.
Напоминаю, что все исходные коды приведены полностью в отчете.
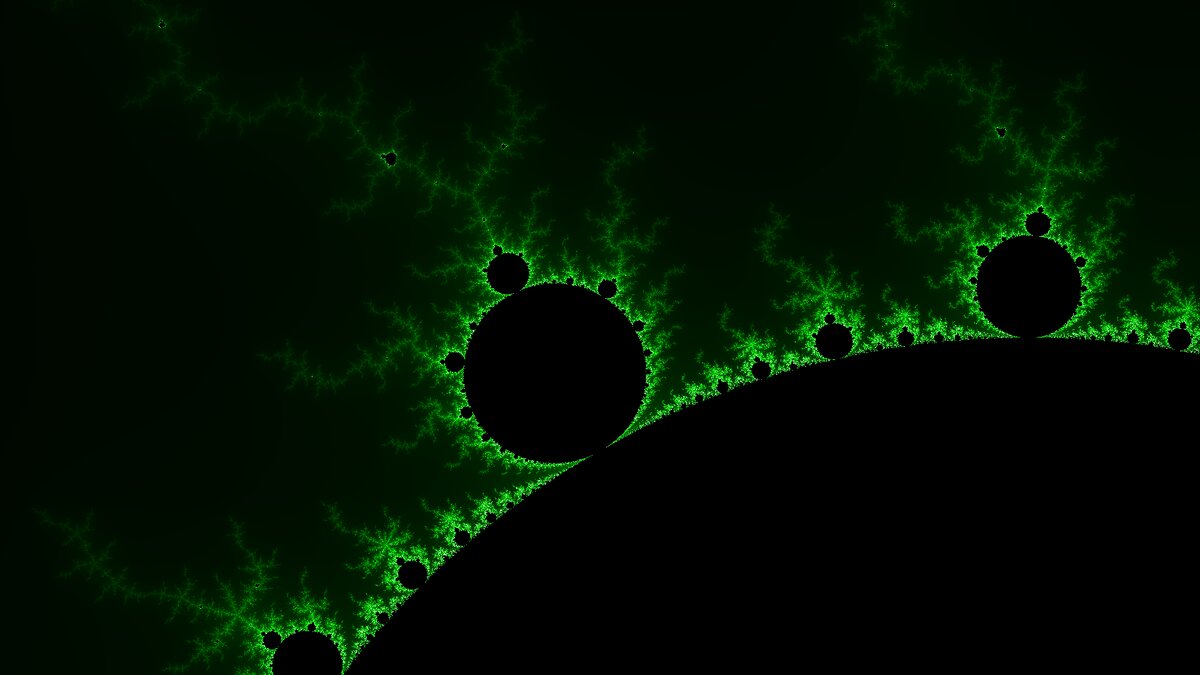
После синтеза исходных кодов в IP-блок было выполнено тестирование и получена тестовая картинка.
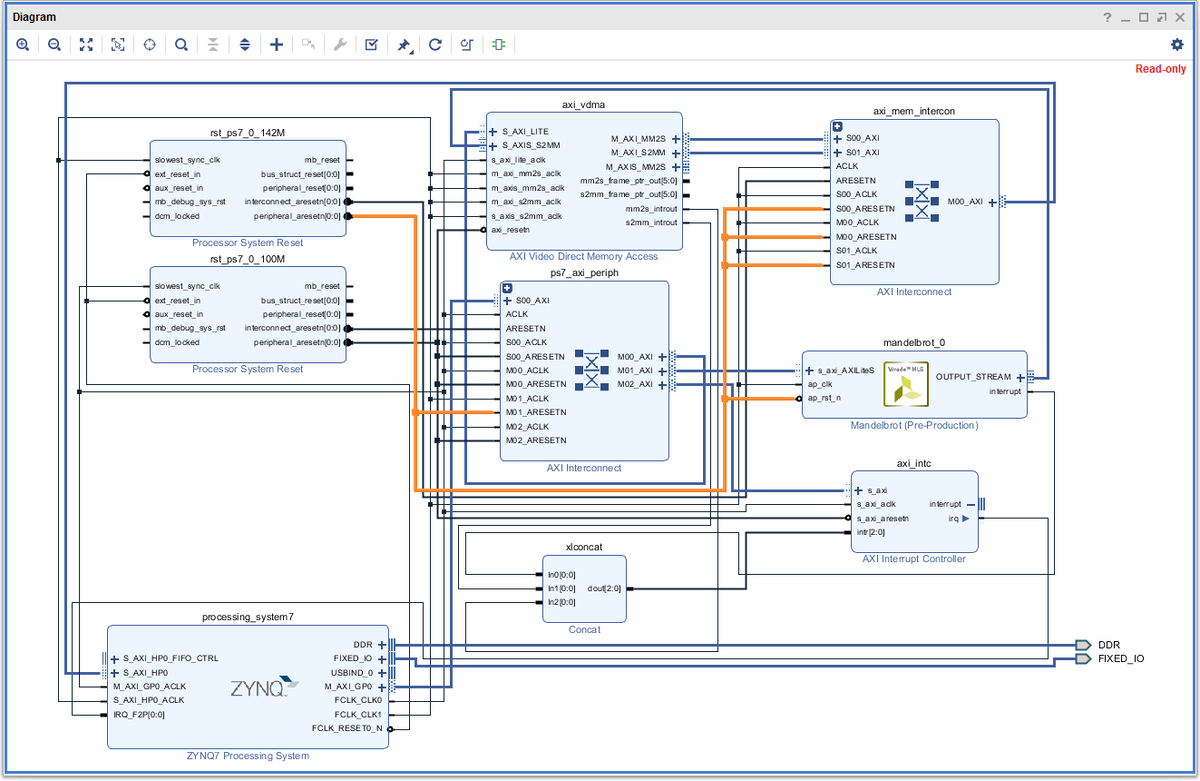
С появлением потоковых интерфейсов и добавлением блока памяти прямого доступа к видео дизайн оверлея усложняется. Потоки AXI4 работают на более высокой тактовой частоте, и поэтому в конструкцию необходимо добавить другой источник тактовой частоты наряду с собственным блоком сброса системы процессора. Это можно видеть в конструкции базового оверлея, а также в спецификации IP-блока AXI VDMA, которая определяет максимальную частоту для AXI4-Stream как 150 МГц.
В базовом оверлее для платы PYNQ-Z1 (на которую ориентирован оригинальный проект - прим. Loosegrasp) внутри иерархии видео потоки AXI передаются через иерархии HDMI. Проанализировав иерархию hdmi_out и ее компоненты, предоставленные вместе с базовым оверлеем, автор выяснил, что все они имеют свойство clk_period, указанное равным 7 нс, что соответствует примерно 142,85 МГц. Важно отметить, что даже при том, что IP-блок может быть рассчитан на частоту 100 МГц, которая является стандартной предустановкой в Vivado HLS (тактовый цикл 10 нс), он все равно может работать на частоте 142 МГц без каких-либо проблем. На этом этапе проектирования целевой тактовый период для IP-блока Mandelbrot установлен на 7 нс, чтобы позволить ему и блоку VDMA работать на более высокой тактовой частоте 142 МГц.
Далее повторяются все уже известные нам шаги: выполняется генерация битстрима, файлы Vivado копируются на microSD, для поддержки нового оверлея дописываются классы модели, отображения и контроллера, а также Jupyter Notebook (см. отчет).
И вот наступает следующий долгожданный момент! Изображение фрактала целиком (не попиксельно с передачей каждого пикселя в Python!) генерируется "железом" ПЛИС и только после этого выводится на экран. Вперед!
Сравните: 994,13 и 0,92337 секунды! Тысячекратное ускорение обеспечено программируемой логикой FPGA. Включение директивы #pragma HLS PIPELINE во внутренний цикл функции calculate позволило конвейеризовать обработку и, таким образом, увеличить пропускную способность. Благодаря этому каждое вычисление, выполняемое на любой отдельной итерации внутреннего цикла, не зависело от результатов, полученных на нескольких предыдущих итерациях, и обработка текущей итерации продолжалась без необходимости ждать завершения выполнения предыдущих итераций, все еще находящихся в конвейере.
Вот, что пишет автор в своем отчете.
"Вычисление значения итерации каждого пикселя является независимым. Это означает, что вычисление может выполняться для любого количества пикселей одновременно. Это может быть использовано для создания нескольких копий одного и того же процессингового оборудования, чтобы увеличить скорость, с которой IP-блок может выдавать изображения, не оказывая никакого влияния на вычисления. Рассматриваемый IP-блок обрабатывает полный ряд пикселей за раз. Цель состоит в том, чтобы иметь возможность обрабатывать несколько строк одновременно, в то же время позволяя разбивать отдельные строки на разделы, где каждый раздел в пределах любой строки может быть обработан собственной копией "железа". Строка пикселей достаточно длинная, и ее можно разделить на несколько секций, не нарушая согласованности конвейера, что позволяет увеличить параллелизм IP-блока без увеличения и без того высоких объемов BRAM, потребляемых массивами, что в противном случае ограничило бы количество копий процессингового оборудования, которые могли бы быть созданы, поскольку на них просто не хватит памяти".
Продолжение следует