
Для начала, что такое парсинг, и нужен ли он нам?
Парсинг - это процесс сбора информации с сайтов для последующей обработки. Например, вы хотите создать программу "Погода" , не будете же вы следить за термометром и вписывать данные каждый час. Гораздо удобнее, чтобы программа сама брала информацию из интернета. Или вам нужно следить за изменениями данных на каком-либо сайте и, чтобы не делать всё это вручную, мы будем учиться создавать парсер. К тому же парсеры много кому нужны и на фрилансе есть куча заказов от 2000 и до бесконечности рублей ( не шучу порой цена до безобразия большая)
Кхм, я буду стараться максимально подробно рассказать о всех тонкостях кода , так что, не судите строго, если что
Ну что, интересно? Тогда начнём!
Делать всё, как вы поняли будем через питон, если у вас его всё ещё, то вся информация о том как скачать есть тут: нажми на меня!
Конечно же начнём с библиотек, и сегодня нам понадобятся requests и BeautifulSoup
Вводим в терминале:
pip install beautifulsoup4
pip install requests
и начинаем наш код с импорта библиотек, пишем:
import requests
from bs4 import BeautifulSoup as bs
(as bs используется для сокращения названия BeautifulSoup, чтобы не приходилось писать длинное название библиотеки в коде, а вместо этого использовать короткое bs)
Теперь определяемся с тем, что будем парсить. В моём примере я буду парсить данные о таваре "Часы" в ЯндексМаркет.
Теперь создаём переменную URL_TEMPLATE , в которую поместим ссылку на сайт, с которого будем парсить, и переменную r, в которой с помощью requests и метода get запрашиваем у сайта разрешение на доступ, и выводим результат запроса:
URL_TEMPLATE = "https://market.yandex.ru/catalog--chasy/51960072/list?srnum=3339&was_redir=1&rt=9&rs=eJwzmswcwFjFwvH7BOssRo6L7Rc2XGy82H2UkYFh2k4g-WCyLZBc8MkKSCqs3Qsi5UCkA5cdkGzIA8kqJIPFJ-8BkgmqIPEFPCDxhFSQOMMesBpuEMlwczeInApiP0gBkQ2_wew7IPMP5IPUJ7wFqVHoBNviAxaZCDK54RXYJTZg8gZYTT1I_MFMG5CZiftB6hnAuhzALpEHiSfIgdgOL8Hu2Q6SPdAHEnfYBzbnvDXIhDcgkQM5YJfcAMu6g9ktYF3SYPf3g8w58Bds19LdYLvAthy3BpsJMrmhBGxmP9gW7n0gNUwg9QrHwGpMQOyG6WA3M4FDRhVEPpAD28UG1rUXbOOSvQBYfJQC&text=часы&hid=15064473&allowCollapsing=1&local-offers-first=0"
r = requests.get(URL_TEMPLATE)
print(r.status_code)
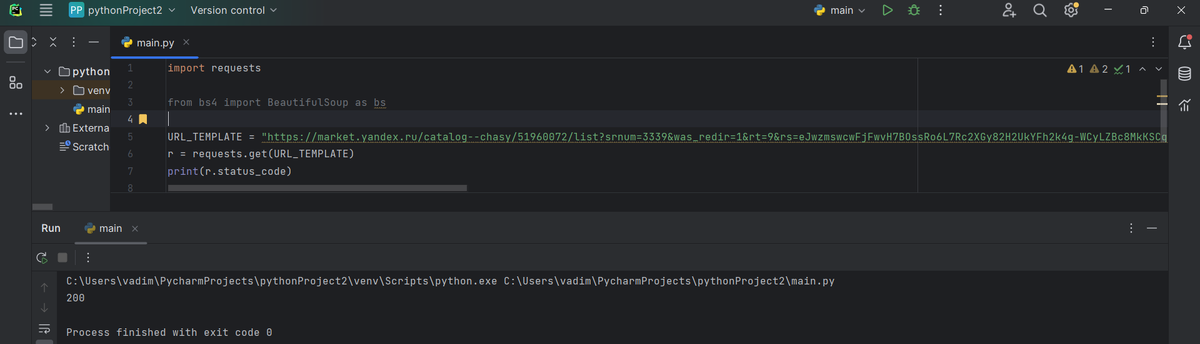
Запускаем код. Если в выводе получилось 200, то всё отлично, доступ получен, если нет, то нужно его настроить, о чём я расскажу в следующей части о парсинге. Подробно об ошибках доступа рассказано тут: тык!
Теперь нам надо взять данные с сайта, поэтому переходим на сайт и начинаем ВЕЛИКИЙ ПОИСК ИНФОРМАЦИИ. Для этого, находясь уже на странице откуда вы хотите взять данные, нажимаем кнопку F12 или Fn+F12. Откроется код странице, где есть вся информация в коде о странице. А чтобы найти нужный нам кусочек кода, придётся немного посидеть: поэтапно наводим курсор на куски кода, в этот момент на сайте периодически будут подсвечиваться различные элементы , как только видите, что подсвечивается область страницы, где нужная вам информация, то раскрываем этот кусочек кода и делаем так до тех пор, пока не будет подсвечиваться только нужная вам информация. Чтобы было чуть понятнее как это работает: представьте, что код - матрёшка, раскрывая которую слой за слоем мы приходим к нужной куколке.
Таким образом из этого:
Я добрался до этого:
Найдя нужный абзац, небходимо вычленить из него класс и тип нашего объекта, грубо говоря задать координаты поиска для нашего кода.( тип будет написан в самом начале строки, в моём случае h3, а класс после 'class =', в моём случае _2UHry _1Oi8a. Теперь развернём эту строку и посмотрим найдём в ней нужную информацию. Вот что добавится в наш код:
soup = bs(r.text, 'html.parser') - этой строкой мы считываем текст с html кода
v = soup.find_all('h3', class_='_2UHry _1Oi8a')
Увидев родную кириллицу радуемся, что наконец нашли, что искали. Теперь нам снова нужно найти тип и класс, заметим, что начинается строка с тега 'a', а описание товара принадлежит 'title', через него и будем выводить информацию. Создаём небольшой перебор и выводим всё, что входит в наши теги. Должно это выглядеть так:
for name in v:
print(name.a['title'])
Смотрим вывод:
Как видно, вывелся не 1 товар, а почти все. Но почему? Это связано с тем, что у всех товаров здесь одинаковые классы и теги, и это удобно, если нам нужно вывести все товары, но что если мы хотим вывести, например, все товары фирмы CASIO, тогда вначале программы создадим список: sp - [], строку print(name.a['title']) заменяем на sp.append(name.a['title']) и в конце программы допишем следующий оборот:
for i in sp:
if 'CASIO' in i:
print(i)
Теперь, программа сначала добавляет информацию о часах в список, а потом выводит только те элементы в которых есть CASIO. Смотрим что получилось:
Весь код:
import requests
from bs4 import BeautifulSoup as bs
sp = []
URL_TEMPLATE = "https://market.yandex.ru/catalog--chasy/51960072/list?srnum=3339&was_redir=1&rt=9&rs=eJwzmswcwFjFwvH7BOssRo6L7Rc2XGy82H2UkYFh2k4g-WCyLZBc8MkKSCqs3Qsi5UCkA5cdkGzIA8kqJIPFJ-8BkgmqIPEFPCDxhFSQOMMesBpuEMlwczeInApiP0gBkQ2_wew7IPMP5IPUJ7wFqVHoBNviAxaZCDK54RXYJTZg8gZYTT1I_MFMG5CZiftB6hnAuhzALpEHiSfIgdgOL8Hu2Q6SPdAHEnfYBzbnvDXIhDcgkQM5YJfcAMu6g9ktYF3SYPf3g8w58Bds19LdYLvAthy3BpsJMrmhBGxmP9gW7n0gNUwg9QrHwGpMQOyG6WA3M4FDRhVEPpAD28UG1rUXbOOSvQBYfJQC&text=часы&hid=15064473&allowCollapsing=1&local-offers-first=0"
r = requests.get(URL_TEMPLATE)
print(r.status_code)
data = r.text
soup = bs(data, 'html.parser')
v = soup.find_all('h3', class_='_2UHry _1Oi8a')
for name in v:
#print(name.a['title'])
sp.append(name.a['title'])
#print(sp)
for i in sp:
if 'CASIO' in i:
print(i)
Вывод:
Получилась простая программа для сбора информации, которую вы с лёгкостью можете встроить в свой проект.
Всем удачи, и лёгкого кодинга