Я нарвался на загадку, которую описал здесь:
Программа работала со структурами, но я её упростил ещё сильнее, с тем же результатом:
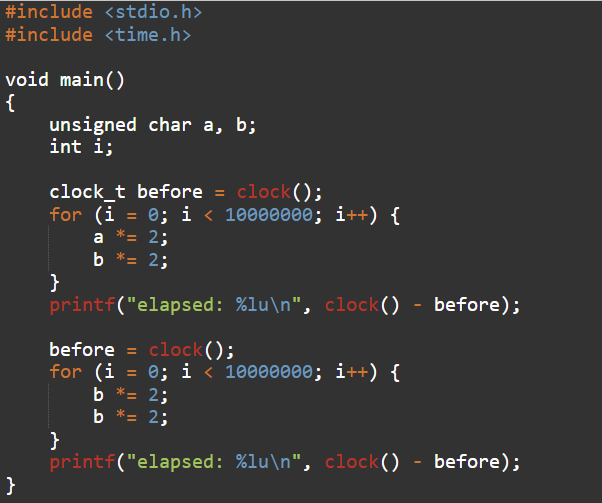
Ссылка на онлайн-компилятор языка C текстом программы
Здесь просто две переменные, которые модифицируются обе в первом цикле (характер модификации роли не играет, хоть делить, хоть умножать, что угодно). Во втором цикле точно так же модифицируется только одна переменная, но дважды.
Результат: второй цикл работает в два раза медленнее.
Чтобы исключить влияние оптимизации, проверим ассемблерный код первого цикла:
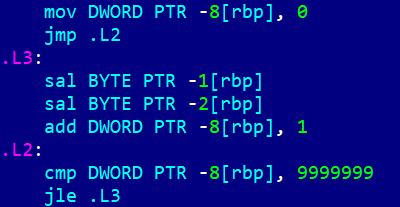
И второго цикла:
-8[rbp] это счётчик цикла i, -1[rbp] это переменная a, -2[rbp] это переменная b. Операция умножения на 2 здесь заменена битовым сдвигом влево (SAL, Shift Arithmetic Left).
Как видим, эти два цикла состоят из полностью идентичных операций. Разница лишь в том, что первый цикл обращается к -1[rbp] и -2[rbp], а второй цикл только к -2[rbp], но 2 раза.
Далее можно сделать несколько предположений. Может быть, надо поменять местами циклы? Нет, если второй цикл сделать первым, он всё равно будет медленнее в 2 раза. Может, модифицировать во втором цикле не -2[rbp], а -1[rbp]? Нет, в любом случае будет медленнее.
Инструкции одни и те же, тип адресации один и тот же, кеш не страдает, так что нет никакой разницы. Тогда что происходит?
Элементарно, Ватсон
У процессора есть т.н. конвейеры вычислений (pipelines). Они позволяют распараллеливать операции. Дальше, наверно, всё понятно :)
Когда мы выполняем две операции с разными переменными:
a *= 2;
b *= 2;
то каждая операция попадает на свой конвейер. Они выполняются параллельно. Результаты этих операций не зависят друг от друга, так как принадлежат разным переменным.
Когда мы выполняем две операции с одной переменной:
a *= 2;
a *= 2;
То процессор не может их распараллелить. Чтобы выполнить вторую операцию, он должен дождаться, когда закончится первая.
Заключение и выводы
Во-первых, это конечно искусственный случай. Программа как минимум должна быть оптимизирована хотя бы так:
a *= 4;
И тогда проблема исчезнет. Но это был специальный наглядный пример, и думаю что можно будет найти реальные примеры с такой проблемой даже при всех оптимизациях.
Во-вторых, это некоторым образом ломает мои представления о "ручной" оптимизации кода, о которой я собственно и хотел писать. Например, может получиться так, что обрабатывать данные большими порциями в некоторых случаях будет вовсе не лучше, чем маленькими. Потому что много маленьких данных могут распределиться по конвейерам и обработаться быстрее, чем одно большое.
Это повод для того, чтобы перечитать код старых программ и попытаться найти возможности для его ускорения.