
Nvidia ясно дает понять, что не потерпит выскочек, пытающихся пошатнуть ее финансовое благополучие. Компания объявила о том, что в ближайшие недели будет выпущена новая версия открытого программного обеспечения TensorRT-LLM, которая позволит удвоить производительность графического процессора H100 при работе с большими языковыми моделями (LLM). Это объявление компании, несомненно, будет хорошей новостью для ее клиентов в сфере искусственного интеллекта и укрепит ее уже доминирующие позиции на этом быстрорастущем рынке.
Компания анонсировала неожиданный прирост производительности в своих популярных ИИ-ускорителях, отметив, что изменения в TensorRT были добавлены в координации с ведущими игроками отрасли, включая Meta*, Grammarly и многих других. По словам компании, большие языковые модели представляют собой уникальную сложность из-за их размера и особенностей выполнения, что вдохновило Nvidia модернизировать программное обеспечение с оптимизацией под большие языковые модели. Nvidia также заявила, что компаниям, использующим более старую версию программного обеспечения, не придется переобучать свои модели при переходе на TensorRT-LLM, так что для компаний с оборудованием Nvidia это бесплатный прирост производительности.
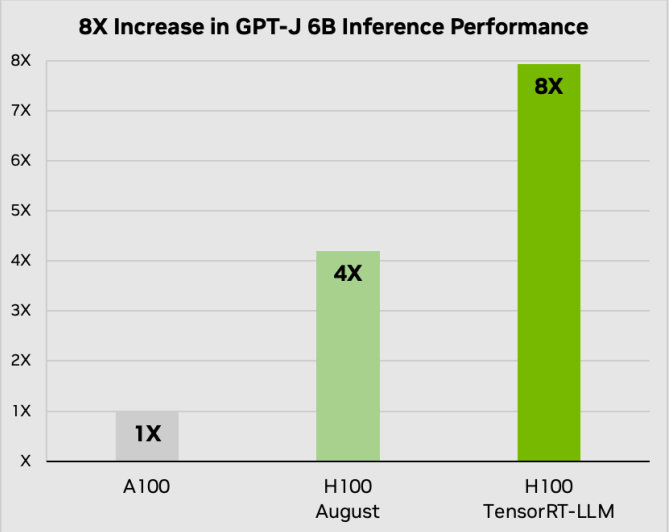
Nvidia сделала смелые заявления и если они окажутся правдивыми, то это еще больше укрепит ее статус золотого стандарта в области аппаратного обеспечения для искусственного интеллекта. Источник: Nvidia.
Nvidia утверждает, что благодаря новейшему программному обеспечению удвоила производительность своего ускорителя H100. По сравнению с одним A100 он обеспечивает прирост производительности в 8 раз и в 4 раза по сравнению с H100 без TensorRT-LLM. В качестве большой языковой модели используется GPT-J с шестью миллиардами параметров, задачей которого является обобщение статей из The Daily Mail и CNN. Nvidia сообщила, что при использовании большой языковой модели Llama 2 производства Meta*, TensorRT-LLM обеспечивает прирост в 4,6 раза по сравнению с одним A100 или 2-кратный прирост для H100 без программного обеспечения LLM.
Для таких компаний, как Meta*, которые специализируются на генеративном искусственном интеллекте, ее новое программное обеспечение предлагает двукратный прирост производительности H100.
По словам представителей Nvidia, одним из методов, обеспечивших столь значительный рост производительности вычислений, является пакетная обработка на лету. Когда пакет запросов включает в себя некоторые запросы, которые завершаются раньше других, их можно «вытеснить», чтобы графический процессор мог запускать новые запросы, а не ждать завершения всего пакета. Tom's Hardware отмечает, что по сути это высокооптимизированная система планирования, которая теоретически раскрывает весь потенциал графического процессора.
*Деятельность этой организации запрещена в России согласно Федеральному закону от 25.07.2002 № 114-ФЗ «О противодействии экстремистской деятельности».