Исправлено 04.09.2023
Цель исследования – понять, как возникает и растет доходное и имущественное неравенство между людьми.
Цель данной статьи – понять, как именно изображать неравенство графически.
Эту серию я начинаю после окончательного понимания начального непонимания – в одну статью, ранее мною выложенную [1], весь необходимый для достижения цели материал впихнуть не удалось.
Как говорил Карл Генрихович, «своеобразный характер материала, с которым имеет дело политическая экономия, вызывает на арену борьбы против свободного научного исследования самые яростные, самые низменные и самые отвратительные страсти человеческой души — фурий частного интереса», поэтому начать нам придётся с самых что ни на есть исходных данных, которые «фурии» ещё не успели исказить до неузнаваемости.
1. Откуда взять данные?
Говоря о неравенстве, обычно говорят о распределении людей по доходам или имуществу – и правильно говорят. Находят эти распределения по доходам и имуществу по-разному, иногда непосредственно, например из зарплатных ведомостей и налоговых деклараций, а иногда косвенно – например по распределению цен на автомобили или недвижимость, предполагая, что эти цены распределены пропорционально доходам людей.
Естественно, можно взять уже обработанные данные о неравенстве с официальных сайтов статистических ведомств той или иной страны – в России это Росстат и gks.ru, в США это Bureau of the Census и census.gov – и мы так тоже будем делать. Но потом.
А сейчас я хочу вам показать, как обрабатывают сырые данные. Не понявши этого, вы не поймёте, где и как вас обманывают в сказках о неравенстве.
Что такое исходные, они же сырые данные? Это данные непосредственно об имуществе или доходах каждого человека в обществе целиком или же в большой (иначе репрезентативности не будет!) выборке из этого общества – у Пети рупь, у Васи два и так далее…
И да, вы можете добыть кое-какие данные самостоятельно, если захотите. Заходим на auto.ru, вводим диапазон цен, например от 0 до 50000 руб, записываем количество машин, продаваемых в этом диапазоне. Затем вводим следующий диапазон, например от 50001 до 100000 руб и опять смотрим записываем количество машин, продаваемых в этом диапазоне. Разбиение данных на диапазоны, которым мы сейчас занимаемся, называется квантованием, а сами диапазоны цен – когортами.
Так от Древнего Рима повелось, где граждан, в зависимости от уровня дохода и типа оружия, который они могли с этим доходом купить, записывали в те или иные войска, то есть в когорты – в лёгкую пехоту, тяжелую пехоту, конницу.
Вот оно, это распределение (табл.1), правда позапрошлогоднее.
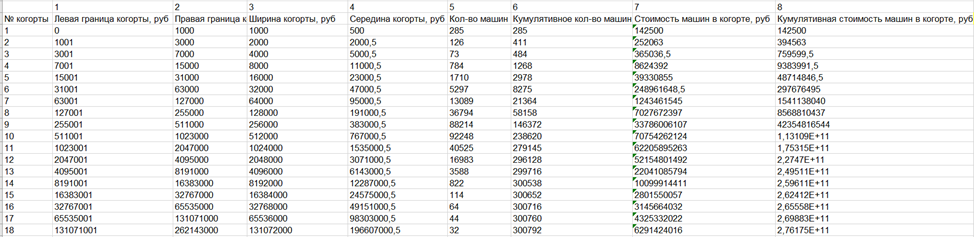
Пока смотрите на столбцы 1,2 и 4,5 и не дальше – а то запутаетесь раньше срока.
И да, я в курсе, что оценивать неравенство по машинам неправильно. Половина российских семей машин не имеет [2]. У бедных, но всё же имеющих автомобиль – это значительная доля имущества, а у богатого меньшинства – это мелочь, что-то вроде носков или трусов. Поэтому распределение цен на автомобили не пропорционально распределению доходов – доходы распределены куда неравномернее. Но начнём с этого, потому что нам нужны пока именно хоть какие-то сырые данные, а сырых данных о доходах мы самостоятельно не получим никогда.
2. Как нарисовать неравенство? Полигон частот
Самое простое, что может быть – это полигон частот, зависимость пятого столбца в табл. 1 от четвертого. Рисуют его так: по оси x откладывают средние цены машин в когортах (ну или значения цен, соответствующие серединам когорт, это примерно одно и то же), а по оси y откладывают количество машин в когортах. Первая точка – это 500 рублей и 285 машин (да, я знаю, что машину за 500 рублей не продадут даже на металлолом, но так было в источнике), вторая точка – 2000,5 рублей и 126 машин ну и так далее (рис. 1).
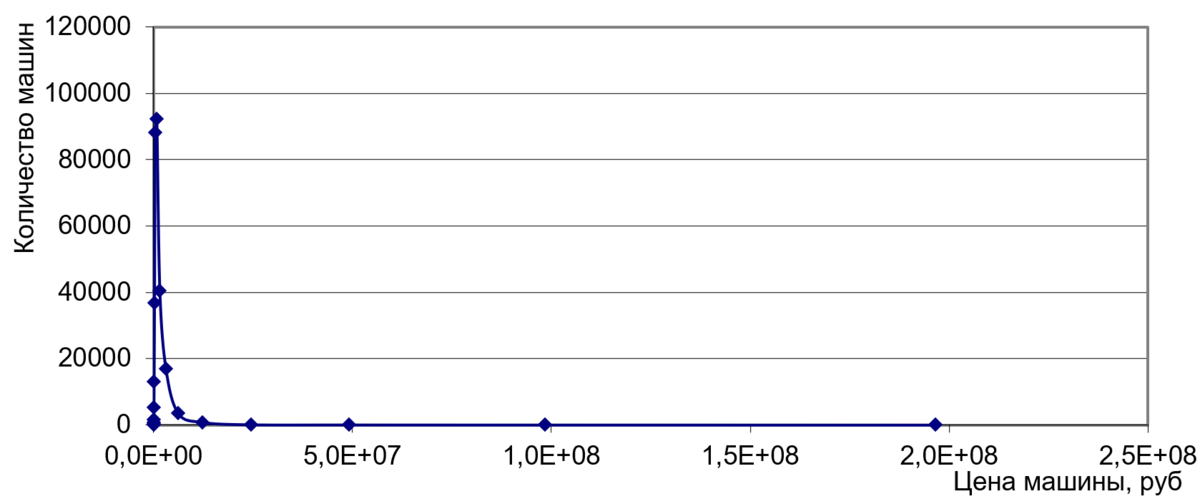
Запись цен в виде 5E7 не смущает? Это экспоненциальная форма, «пять умножить на десять в седьмой степени», то есть пятьдесят миллионов – вот что тут написано. Может это и немного непривычная форма записи, но совершенно необходимая для оценки неравенства: здесь цены, имущества и доходы отличаются в сотни тысяч и миллионы раз, если не пользоваться экспоненциальной формой, то у вас от нулей в глазах зарябит и цифры не прочитаются.
Почему эта картинка называется «полигон частот» а ещё называется «плотность распределения» или «плотность вероятности»? Потому что частоты или вероятности здесь и нарисованы. Возьмем начальный кусок графика рис. 1 – потому что внятно нарисовать эти вероятности на целиковом рисунке 1 нам масштаб не позволит - и посмотрим (рис. 2).
Посмотрите на рис. 2. А если вам, как и мне, цифры понятнее картинок, то посмотрите на табл.1. Наиболее вероятно, что первая попавшаяся машина с auto.ru попадёт в диапазон цен от 511001 до 1023000 руб. – в этот диапазон попадает больше всего машин, аж 92248 штук, это десятая когорта в табл. 1 и самый высокий столбик на рис. 2, как раз высотой в 92248 машины.
Частота попаданий в диапазон цен от 1023001 до 2047000 заметно ниже, туда попадёт всего 40525 машин. Это одиннадцатая когорта в табл. 1, вероятность попадания в неё в два с лишним раза меньше, чем в десятую, а на рис. 2 это столбик справа от самого высокого, он соответствует средней цене примерно 1,5Е6 руб.
Следующий столбик, соответствующий средней цене около 3Е6 руб – ещё ниже, вероятность попадания машины в этот ценовой диапазон ещё меньше.
Ну и так далее.
Вы с таким наверняка сталкивались, когда вам говорят «нормальное распределение похоже на колокольчик» - речь идёт именно об этом способе представления данных, речь о полигоне частот. Только вот распределение людей по доходам – вообще ни разу не нормальное, но об этом потом.
3. Как нарисовать неравенство? Функция распределения
К тому, что на что похоже, мы ещё вернёмся, а сейчас мы будем рисовать функцию распределения.
Рассчитываем кумулятивное (то есть накопленное) количество машин, соответствующее каждой когорте, оно же - количество машин нарастающим итогом - столбик 6
Первая ячейка в столбике 6 равна первой ячейке в столбике 5, вторая ячейка в столбике 6 равна первой (т.е. предыдущей) ячейке в столбике 6 плюс второй ячейке в столбике 5 ну и так далее. Получается у нас кумулятивная (то есть накопленная) стоимость машин.
Давайте нарисуем её, то есть построим зависимость столбика 6 от столбика 3, кумулятивного количества машин в когортах от средней цены машин в когортах (рис. 3).
4. Как нарисовать неравенство? Кривая Лоренца
Кривую Лоренца мы уже рисовали, когда рассчитывали индекс неравенства Джини [3].
Для того, чтобы её нарисовать по данным таблицы 1, нам нужно создать ещё один столбик - №6, кумулятивное количество машин. Как считать что бы то ни было нарастающим итогом – вы уже знаете: первая ячейка столбика 6 равна первой ячейке столбика 5, вторая ячейка столбика 6 равна первой (предыдущей) ячейке столбика 6 плюс вторая ячейка столбика 5 и так далее.
А кривая Лоренца – это зависимость столбика 8 от столбика 6, кумулятивной стоимости машин в когортах от кумулятивного количества машин в когортах, рис. 4.
Что ещё нам следует знать о кривых представления неравенства? Если мы хотим - а мы хотим! - сравнивать данные о неравенстве из разных источников – например неравенство по доходам и неравенство по ценам на машины – их придётся приводить к безразмерному виду.
Как это делается? Все доходы людей делятся на самый большой доход и все цены машин делятся на цену самой дорогой машины – и готово. Было у нас две шкалы: шкала в рублях для машин и в рублях в месяц для доходов - сравнивать данные никак нельзя. А стала одна шкала от нуля до 100% - сравнивать можно, пожалуйста.
Точно так же можно привести к безразмерному виду количество людей и количество машин в когортах, тоже шкала будет от нуля до 100%.
И да, если нам нужны кумулятивные шкалы, как для функции распределения или кривой Лоренца, то безразмерность им ничуть не мешает, величина может быть кумулятивной и безразмерной одновременно – ачётакова?
Последнее, что я хотел сказать про построение этих трёх кривых неравенства – они все друг другу родственницы. Строятся они на одних и тех же сырых данных, полигон частот (или плотность распределения) – это самое исходное изображение данных на картинке, функция распределения – это интеграл от полигона частот, а кривая Лоренца – это двойной интеграл от полигона частот и оси поменялись местами. И пусть меня простят математики за употребление такой терминологии.
5. Недостаток полигона частот
Если вы ещё не уснули – сейчас самая пора спросить: «Ну и чо?!». Зачем был весь этот корявый пересказ учебника по статистике?
Вот теперь мы переходим к главному – к недостаткам.
Власти от нас скрывают недостатки двух самых популярных способов графического представления неравенства. Шучу. Никто ни от кого ничего не скрывает, все всё давно знают, просто всем всё пофиг.
Запомните два простых принципа, которым должны соответствовать любые исследовательские методы, приёмы и инструменты.
Первый – различать то, что различается.
Второй – не различать то, что не различается.
Эти принципы звучат примитивно до тупости, не так ли?
Уж настолько простые базовые принципы никто никогда не нарушает? Ага, щаз!
Полигоны частот различают то, что не различается. Проверить это элементарно. Берем какую-нибудь базу данных, да хоть тот же сайт auto.ru. Его данные ведь тождественны самим себе, не так ли? Они ведь не отличаются сами от себя?
Погодите, сейчас вылетит птичка. Берем эти данные, квантуем, то есть разбиваем на когорты двумя любыми разными способами, строим полигоны частот и что же мы видим? (рис. 5 [4]):
А видим мы, что полигоны частот разные при разном квантовании одних и тех же данных. Это значит, что данные о неравенстве в одной и той же стране в одно и то же время, но из двух разных источников вы не сопоставите никогда в жизни. Локти будете кусать и ничего не сделаете.
Небольшое отступление о том, зачем нужны данные из двух разных источников?
«Двое свидетелей, белый листок протокола.»
(с) «Лесоповал»
Почему свидетелей двое? Издревле нормами выяснения истины занималась юриспруденция и к пониманию того, что для осуждения или оправдания нужны по крайней мере два источника юриспруденция пришла ещё в Античности. Если два более-менее независимых свидетеля повторят, что видели одно и то же - то это одно и то же скорее всего и есть правда.
Наука пришла к тому же, хоть и позже. Научные факты – это только лишь повторяющиеся факты, без сопоставления данных из разных источников вообще ничего сделать нельзя.
Полигоны частот для этого не годятся, они различают то, что не различается.
6. Недостаток кривой Лоренца
Кривая Лоренца абсолютно нечувствительна к квантованию, она может быть построена даже на вообще неквантованных данных, она не различает то, что не различается. Но на этом хорошие новости заканчиваются.
Кривая Лоренца – это то, из чего Джини вывел свой индекс неравенства и основной недостаток у кривой Лоренца тот же самый, что и у индекса Джини [3]: она требует идеально полных, а не отрывочных данных о доходах богатых. Сейчас вы в этом убедитесь.
Давайте изготовим отрывочные данные сами, добавив к таблице 1 всего одну машину. Зато какую! За 2 621 430 000 руб! Эта цена взята с потолка, она выбрана она такой, чтобы быть на порядок больше цены самой дорогой машины табл. 1.
Получилась у нас табл. 2
И теперь строим три наших кривые – полигон частот, функцию распределения и кривую Лоренца – в двух вариантах: до добавления отрывочных данных о цене самой дорогой машины и после (рис. 6, 7, 8).
На всех рисунках кривая до добавления данных – синяя, после добавления данных – желтая. Специально чтобы было сразу понятно, на что смотреть и что изменилось: на конец кривой до добавления данных указывает синяя стрелка, на конец кривой после добавления данных указывает желтая стрелка. А на начало кривых нет смысла указывать – они все из точки (0;0) выходят.
Итак, что мы видим? Полигоны частот и функции распределения действительно различают то, что различается – желтая и синяя стрелки указывают в разные места.
А вот кривые Лоренца – нет, вам не показалось и на рис. 8 нет никакой ошибки! – действительно не различают то, что различается. Для кривых Лоренца абсолютно безразлично, что самая дорогая машина за 26 миллионов, что самая дорогая машина за 2,6 миллиарда – всё равно кривые будут одинаковы, полностью совпадут, а синяя и жёлтая стрелки укажут в одну точку.
А теперь о смысле того, зачем я приделал к этому распределению ещё одну машину в десять раз дороже и зачем нужен график, способный различать такие моменты. Дело в том, что о доходах богатых мы знаем куда меньше, чем о доходах бедных. Данные о бедных полны, данные о богатых отрывочны. Мы примерно знаем, где находится правый край шкалы доходов, но не знаем, сколько там, у правого край, скопилось человек. Оно и неудивительно, если вы получаете триста долларов в месяц, то о ваших доходах всё знает ваше начальство, бухгалтерия, Росстат и Федеральная Налоговая Служба – хотите вы или нет, вы на виду.
Но вот если вы получаете триста миллионов долларов в месяц, то у вас с одной стороны больше оснований скрывать доходы, а с другой стороны больше возможностей. Поэтому данные о богатых отрывочны и неполны и это не только моё мнение [5] и [6].
А для кривых Лоренца нужны идеальные данные – полные сведения не только о диапазоне доходов, но и о наполнении богатых когорт. В стране розовых пони, где богатые не скрывают своих доходов, эти данные несомненно есть, а вот у нас как-то не очень. Поэтому если вы возьмёте полные данные Росстат с максимальным доходом 89 тыс. руб/мес, построите по ним кривую Лоренца, а потом прикрутите к полным данным Росстат отрывочные данные «Форбс» с максимальным доходом 14 млрд руб/мес, то кривая Лоренца изменится чуть менее чем никак [4].
Ещё раз, чтоб вам понятно было – кривая Лоренца никак не отличает общество с доходом в 89 тысяч рублей в месяц от общества с доходом в 14 миллиардов рублей в месяц – все данные по ссылочке есть, можно убедиться. Кривая Лоренца – это не инструмент представления неравенства, это инструмент сокрытия неравенства.
Мораль нашей басни очень проста: не хочешь проблем - работай с функцией распределения.
А теперь внимание, вопрос! Вот у нас есть три графика.
Один. Полигон частот, который различает то, что не различается, который зависит от квантования, который не позволяет сравнивать данные из разных источников.
Два. Кривая Лоренца, которая не различает то, что отличается, которая не способна отличить общество с максимальным доходом в 89 тыс. руб. от общества с максимальным доходом в 14 млрд. руб., которая требует идеально полных данных о богатых.
Три. Функция распределения, которая не страдает ни тем, ни другим.
Угадаете ли вы с одного раза, какие два графика применяются в статистике повсеместно, а какой – почти что никогда?
Update 20/09/2023
Мои читатели должны получать наилучшую доступную мне информацию, хотят они этого или нет. Пару недель назад я узнал о кривой и индексе неравенства Бонферрони [7,8].
Бонферрони разработал этот матаппарат в 1930, почему же я узнал об этом только сейчас? В своё оправдание могу сказать, что это очень непопулярные индекс и кривая, на русском про них я вообще ничего не встречал, а на английском про них пишут только итальянцы.
Чтобы не захламлять и без того длинную статью, скажу только, что кривая Бонферрони - неплохой инструмент, она может быть построена при любом квантовании данных и даже вообще без квантования.
Она различает то, что различается и реагирует на добавление отрывочных данных о богатых, на добавление в выбору одной, но очень дорогой машины.
Но она, увы различает и то, что не различается, она чувствительна к квантованию примерно как полигон частот.
Все необходимые выкладки, буде они кому-то нужны, готов предоставить.
Источники
1. https://dzen.ru/media/id/61084b162b4a2410eaf7d715/rangovyi-obmen-ili-otkuda-beretsia-neravenstvo-64e65ea22c154338cdd32e56
2. https://ria.ru/20210716/avtomobil-1741471380.html
3. https://dzen.ru/media/id/61084b162b4a2410eaf7d715/indeks-djini--ot-serdca-k-solncu-dalee-v-uchebniki-64d792f5ae41ff4d81e300ef
4. Капитанов В.А., Иванова А.А., Максимова А.Ю. Преимущества функции распределения как метода графического представления экономической структуры общества. «Статистика и экономика». Том 15, № 1 (2018). С. 4-16 https://statecon.rea.ru/jour/article/view/1188
5. Тихонова Н.Е., Лежнина Ю.П., Мареева С.В., Аникин В.А., Каравай А.В., Слободенюк Е.Д. Модель доходной стратификации российского общества: динамика, факторы, межстрановые сравнения – СПб.: Нестор-История. 2018.
6. Korinek A., Mistiaen J. A., Ravallion M. Survey Nonresponse and the Distribution of Income: World Bank Policy Research Working Paper 3543. March 2005.
7.https://www.researchgate.net/publication/273524237_The_Graphical_Representation_of_Inequalityality
8. https://www.econstor.eu/bitstream/10419/195455/1/1019667672.pdf