
Введение
Нейросети проникли повсеместно в нашу жизнь, начиная с алгоритмов работы некоторых ресурсов, типа СБЕРа, заканчивая непосредственно клиентами для генерации текстового, графического и прочего контента. Не так давно вышла новая версия трансформера от Open AI – GPT4, которая потрясает своими возможностями генерации, от обычных информационных статей, до специализированного контента в виде программного кода или имитации работы операционных систем.
И вот, изучая этот IT–феномен, мне пришла в голову идея написать свой клиент для взаимодействия с подобной текстовой нейросетью.
Изначально, хотелось написать код для взаимодействия как раз-таки с gpt4, но, для работы с ней требуется регистрация на портале open ai, с последующим получением ключа, который прописывается в код. Т к я из РФ, с этим пока есть проблемы. Поэтому, для начала, я решил попробовать модели попроще, но с поддержкой русского языка. В итоге, выбор пал на модель нейросети от СБЕРа, на базе gpt2 (хотя они ее называют rugpt3). Точное название модели: “sberbank-ai/rugpt3large_based_on_gpt2”.
Первая часть кода (интерфейс)
В качестве оболочки я решил использовать композицию виджетов pyqt5, где на главном окне будет всего три элемента: Строка для ввода текстового запроса нейросети; кнопка, посылающая сигнал нейросети отвечать и, собственно, текстовое поле для ответа.
Приступим уже к самому коду!
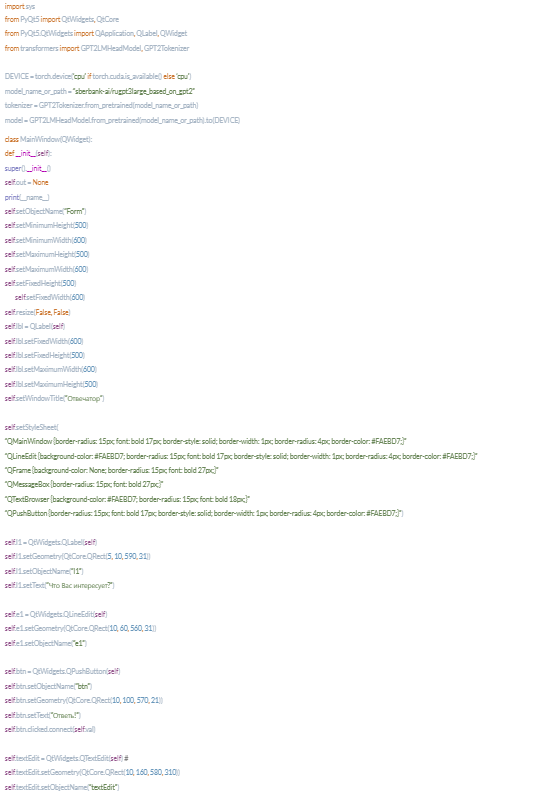
Первая часть кода включает в себя импорт необходимых модулей, прописку и инициацию нашей нейросетевой модели, ну и сам интерфейс.
Для работы с моделью нам потребуется установить модули transformers и torch. Установка этих модулей, как и прочих других происходит через pip. Модули достаточно объемные, особенно сама модель нейросети, весящая 3,2 Гб, поэтому первый запуск с установкой займет довольно длительное время.
Нейросеть может производить свои вычисления или через центральный процессор ПК (cpu), либо через видеопроцессор (cuda). Преимущество в скорости вычислений, соответственно и в выдаче ответа у видеокарт. Но, т к в процессе работы поглощается большой объем оперативной памяти (эта модель при определенных настройках генерации может поглощать более 16 Гб памяти), не каждая видеокарта может подойти. Так как у меня установлена Nvidia – 1650 с 4 Гб на борту, а ЦП работает с 16 Гб оперативы, выбор cpu был очевиден. За работу с железом ответственен torch.
Трансформер же отвечает за работу с моделью. Главные подмодули в нем это GPT2Tokenizer и GPT2LMHeadModel. Первый отвечает за токенизацию нашего запроса и последующего ответа, а второй, скажем так, приделывает модели функции ее настройки.
Касаемо интерфейса, то тут особо нового ничего нет. Это pyqt5-виджеты: QLabel, QLineEdit, QPushButton, QTextEdit. В лайнэдит мы вводим наш запрос, в текстэдите выводится ответ, при предварительном нажатии на буттон.
Вторая часть кода (настройки генерации текста)
Давайте посмотрим более интересную вторую часть кода!
Вторая часть кода, кроме «хвоста», состоит из двух функций.
Первая функция
Первая, «def val» извлекает текст нашего запроса и передает его во вторую функцию «def generate_text», где и происходит все волшебство.
Здесь стоит коротко рассказать о том, как работает нейросеть.
Лирическое отступление о моем представлении о том, как устроена нейросеть
Машинная нейросеть, по аналогии с нейросетью человеческого головного мозга, имеет возможность обучаться. Входящий текст она разбивает на токены – элементы слова, буквы, понятия и т д. Токенизация машины есть следствие ее предварительного обучения, когда модели скармливают похожие данные, содержащие условные вопрос и ответ, откуда она, в процессе обработки определяет веса, или логическую взаимосвязь, между различными элементами текста (текстовая нейросеть), текста и изображения (нейросеть – генератор изображений) и т д, которые, в дальнейшем, и формируются в токены. Таким образом, нейросеть образует словарь токенов, а также данные о том, как эти токены лучше всего сочетаются. Ну а само обучение, это такая-же статистическая обработка новой информации, сначала по шаблонам с прямой связью вопрос – ответ, а затем генерация подобного, статистически наиболее вероятного ответа. Далее нейросеть эти токены превращает в математические векторы с определенным порядковым номером, и, на основе прописанных параметров генерации и по сути тех-же весов генерирует, если можно так назвать, модель возможных вариантов ответа, из которых выбирает наиболее вероятный – подходящий.
У процесса генерации есть множество параметров, которые отвечают за различные свойства продукта генерации. В нашем коде представлена часть из них. Честно говоря, я до конца с этими параметрами еще не разобрался. Поэтому, объясню как смогу)))
Вторая функция
Вернемся к коду. Первые четыре строки это включение токенайзера на кодирование и декодирование входящего запроса. Параметр input_ids, это команда, запускающая процесс преобразования нашего текстового запроса в математический вид, т е в векторы (тензоры). Следующие три строчки (print) позволяют вам посмотреть на какие токены разбит текст запроса и как они выглядят на языке математики. Как пишут другие авторы, есть некоторые токены, которые только в определенном сочетании между собой образуют конкретное слово или сочетание слов.
Ну а далее идет закладка параметров генерации. С input_ids мы разобрались. Параметр temperature, на сколько я понял, отвечает за степень свободы в процессе раскрытия заданной темы. Это ограничение в генерации, чтобы не возникало ситуации, когда типа начали говорить про то, как приготовить борщ, а закончили тематикой про ставки на спорт. Хотя, конкретно с этой моделью я разницы особой не увидел.
Параметр num_beams, как я понял отвечает за количество рассматриваемых наиболее вероятных вариантов ответа для выбора конечного.
Параметры max_length и min_length отвечают соответственно за максимальную и минимальную длину ответа.
Ну а остальные параметры определялись методом тыка, хотя и выше описанные тоже)))
Выбор конкретных параметров зависит от конкретной конфигурации вашего ПК. Чем больше задается условная вариабельность ответа, тем сильнее нагружается ресурс ПК. Так, с моим i5 процессором и 16 Гб оперативы приведенные в коде параметры, на мой взгляд, показались наиболее оптимальными. Т к я особо в них ничего не соображаю, то, вероятно все-таки ошибаюсь и есть настройка получше. Напишите в комментах, какую бы вы посоветовали!
После того как мы задали параметры генерации и получили некий ответ в векторном виде, его необходимо перевести на человеческий. И в этом нам помогает все тот же токенайзер. Ну и в конце мы полученный текст выводим в текстовое поле.
Заключение
Вот такой у нас клиент SBER–gpt в итоге получился. Код полностью и текстом доступен по ссылке на оригинальную статью: https://sergsergius.ru/sber-gpt-na-pc/
Выдает более-менее читабельный ответ, но с довольно большим количеством бреда. Ну вы видели на первом изображении инфу кто основал рэп в России))) Или последнее про борщ...
Ну а я буду дальше изучать нейросети. Как мне кажется, за ними кроются большие перспективы в абсолютно разных областях науки, промышленности и жизни людей.