Всем привет! Вот и добрались у меня руки попробовать улучшенные модели ruGPT-3.5 13B и mGPT 13B от разработчиков из Сбера.

Данные модели имеет 13 миллиардов параметров и при этом первая обучалась на множестве русскоязычных датасетов, а вторая на датасетах большинства языков существующих на просторах нашей великой и необъятной Родины. Иными словами данные модели идеально подходят для интерактивного общения с прихотливыми соотечественниками.
Для того чтобы их запустить на моей RTX 4090 пришлось приложить немало усилий для того чтобы оптимизировать конфигурацию, поэтому, сегодня мы будем разбираться с вами в том как происходит запуск оригинальной (неквантованной) модели в режиме квантизации 4 и 8 бит "на лету" с автоматическим управлением памятью, дабы с комфортом разместить этих прожорливых малюток в памяти видеокарты.
Вот ссылочка на репозиторий, в нём будут скрипты rugpt35.py (простой пример запуска модели) и prompt.sh (интерактивный чат).
Введение
Начнём с небольшого блока теории.
Модель ruGPT 3.5 стала доступна широкой общественности 20го июля 2023го года и всем интересующимся темой нейросетей стало очевидно, что для запуска данной модели нужно много оперативной памяти на видеокартах (и это не говоря уже про обучение).
Для расчета этого объема используется простая арифметика. Количество параметров модели составляет 13 миллиардов (13B). По умолчанию, модель использует 32-битный (float32) формат хранения данных в памяти, что соответствует 4 байтам (ведь 1 байт содержит 8 бит, а 4 байта умноженные на 8 бит каждый дают 32 бита).
Таким образом, для хранения всех параметров ruGPT-3.5 13B в 32-битном режиме необходимо примерно:
13 (миллиардов параметров) * 4 (байта) = 52 (миллиарда байт)
---
при этом 1 миллиард байт = 1 гигабайт, а если точнее то 931 мегабайт, то есть для 13B модели потребуется примерно 48.4 гигабайта только для запуска.
Самые доступные видеокарты с максимальным объёмом видеопамяти на сегодняшний день это RTX 3090 и RTX 4090, на каждой из них установлены чипы оперативной памяти с суммарным объёмом 24Гб (на самом деле меньше, в реальности объём ≈ 23.6 гигабайта).
Иными словами, для запуска ruGPT-3.5 13B с настройками по умолчанию необходимо иметь как минимум три таких видеокарты и это не учитывая того объёма который понадобится для инференса (то есть обработки запросов пользователя).
Оптимизируй это
Из предыдущей главы проистекает логичный вопрос: а можно ли как-то запустить данную модель используя меньший объём оперативной памяти?
И ответ на этот вопрос: да, это возможно.
Помимо float32 существует ещё три варианта запуска модели:
- для float16 потребуется как минимум 24.2Гб памяти
- для int8 - 12.1Гб
- для int4 - 6Гб
Гипотетически возможно запустить модель в 2х битном режиме, но это потребует дополнительных преобразований, о чём я могу рассказать в одной из следующих публикаций если читатели будут в данной теме заинтересованы.
На всякий случай хочу обратить ваше внимание, на то что чем сильнее квантизация модели, тем хуже будет результат её генерации.
float16
Чтобы переключить модель в режим float16 (также известный как half) необходимо после инициализации модели добавить следующее:
model.half()
Данный приём можно использовать только на неквантованных моделях в ином случае будет вызываться исключение.
Полный пример выглядит следующим образом:
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForCausalLM.from_pretrained(name, trust_remote_code=True)
model = model.half().to('cuda')
И хоть этот способ позволит вдвое сократить объём необходимой памяти, этого всё равно недостаточно для того чтобы запустить модель на одной карточке с 24Гб видеопамяти.
Поэтому рассмотрим следующий вариант.
int8 и int4
У питоновского пакета transformers в конце 2022го года был добавлен очень любопытный параметр, под названием load_in_8bit, а спустя несколько релизов был добавлен ещё и load_in_4bit.
Что же делает эти параметры такими уникальными?
Дело в том, что они включают специальную библиотеку bitsandbytes в последовательность инициализации большинства моделей, которые возможно запустить через трансформеры. На этапе загрузки модели в оперативную память происходит преобразование параметров в формат желаемой разрядности (int8 или int4, в зависимости от того какой ключ имеет значение True).
И так, попробуем проинициализировать оригинальную модель ruGPT-3.5 13B выполнив квантизацию на лету в 8bit режим (напомню, что таким образом будет занято примерно 12.1Гб памяти). Код будет выглядеть следующим образом:
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForCausalLM.from_pretrained(name, trust_remote_code=True, load_in_8bit=True)
model = model.to('cuda')
А вот версия 4bit (потребуется примерно 6Гб памяти):
tokenizer = AutoTokenizer.from_pretrained(name)
model = AutoModelForCausalLM.from_pretrained(name, trust_remote_code=True, load_in_4bit=True)
model = model.to('cuda')
Разделяй и... память
Теперь хочу поговорить про пару очень интересных параметров, которые можно передать в момент инициализации модели:
- max_memory={0: f'{int(torch.cuda.mem_get_info()[0]/1024**3)-2}GB'}
Параметр max_memory позволяет явно указать, какой объём оперативной памяти может использовать torch на устройстве 0 (в нашем случае это CUDA) для запущенной модели. Далее идёт небольшая формула, которая выбирает информацию об объёме свободной оперативной памяти (в байтах), доступной CUDA.
Если чуть подробнее, то выполняются простые арифметические операции (объём свободной памяти в байтах делится на 1024^3). Если у вас свободно скажем 23Гб памяти, то данная формула скажет, что max_memory будет равен 21Гб.
23544922112 / (1024**3) = 21.92791748046875 = 21GB
Если не указывать max_memory, то torch будет считать, что нужно использовать всю доступную на устройстве память. Это может быть плохо, если у вас всего одна видеокарта, и на ней выполняется что-то ещё, например, рендерится графический рабочий стол.
- device_map="auto"
Второй очень интересный параметр. Он заставляет torch пытаться распределить модель по всем устройствам в системе, обладающим оперативной памятью. Однако заполнение происходит последовательно, начиная с нулевого устройства.
Иными словами, комбинация этих двух параметров позволит нам запустить практически любую модель, не беспокоясь о необходимом объёме памяти.
Типичный юзкейс: у нас имеется видеокарта с объёмом VRAM равным 8Гб, есть некая модель для которой требуется, скажем, 7.9Гб чтобы загрузить все веса, но при этом не остаётся ресурсов на инференс. При включении параметра device_map="auto", пакет torch пытается использовать системную память CPU и будет выполнять инференс уже на ней. Конечно, скорость работы при этом уменьшится, но если выбирать между "медленно" и "вообще не работает", то уж лучше первое.
Попробуем соединить все вышеописанные подходы в простом примере кода:
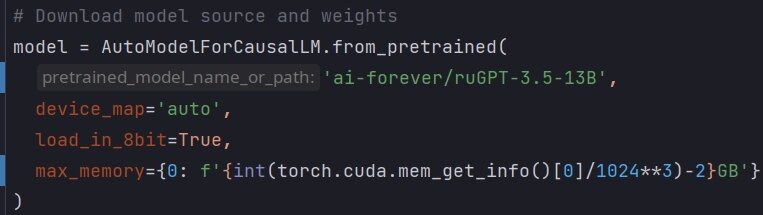
Тут видно что мы запускаем модель, заставляем трансформер выполнять квантизацию "на лету" до 8bit, далее ограничиваем объём видеопамяти до 21Гб (22Гб если видеокарта ничем не будет загружена) и заставляем torch самостоятельно управлять распределением памяти и очисткой кеша.
Ближе к делу
На данный момент нам известны все хитрости, которые могут нам пригодится для запуска модели ruGPT-3.5 13B или mGPT 13B (принципиальной разницы между этими моделями нет, они созданы на одной и той же архитектуре, разница только лишь в датасетах на которых проводилось обучение) на своём компьютере, поэтому давайте наконец приступим к написанию кода.
Нам понадобятся:
- Python 3.11
- Python VitrualEnv
- Драйвер Nvidia (535.xx или выше)
- Драйвер CUDA (11.7 или выше)
Для начала создадим пустую папку, а в ней виртуальное окружение, в котором будет выполняться вся последующая работа.
mkdir rugpt3-custom
cd rugpt3-custom
python3 -m venv venv
source venv/bin/activate
После выполнения указанных команд мы должны оказаться в контексте виртуального окружения. Установим несколько пакетов, для работы нам потребуются: torch, transformers, accelerate, bitsandbytes и scipy. Выполним следующую команду:
pip install transformers==4.32.1 torch==2.0.1 accelerate==0.22.0 bitsandbytes==0.41.1 scipy==1.11.2
Далее создадим файл rugpt35.py
touch rugpt35.py
Теперь начнём наполнять его кодом, первым делом потребуется импортировать все необходимые библиотеки, классы и функции.
Далее вынесем в переменную name название модели с которой мы хотим работать, в частности ai-forever/ruGPT-3.5-13B (в коде видно, что я ещё проводил эксперименты с mGPT-13B, вы можете её тоже попробовать, если нужна поддержка множества языков).
После этого выполним инициализацию модели (в которой используются все механизмы оптимизации), после чего инициализируем токенизатор.
На следующем шаге подготовим небольшой стартовый текст (закваску), он будет содержать инструкции для нейросети и описывать шаблон, в котором мы хотим чтобы нейросеть следовала определённому формату, а также добавим туда запрос пользователя.
Теперь создадим пайплайн, который будет работать в режиме text-generation, после чего прогоним через него закваску и выведем результат.
Полный код можно найти тут.
Разберём передаваемые параметры подробнее:
- prompt - это начальный текст (или запрос), который вы подаёте модели. Он служит отправной точкой, от которой модель начинает генерировать свой ответ или продолжение.
- max_new_tokens - максимальное количество новых токенов, которое модель может сгенерировать в ответ. Токеном может быть слово, часть слова или даже один символ, в зависимости от того, как была обучена модель. В данном случае модель сгенерирует не более 256 новых токенов.
- top_k - параметр, который ограничивает количество верхних токенов, рассматриваемых при выборе следующего токена. Модель будет выбирать из 40 наиболее вероятных токенов при генерации следующего токена.
- top_p (также известный как nucleus sampling) - это вероятностный порог. Модель будет выбирать следующий токен из подмножества, пока совокупная вероятность этого подмножества не превысит значение top_p. В данном случае порог установлен на 0.85.
- repetition_penalty - штраф за повторение. Этот параметр влияет на вероятности токенов, которые уже были использованы. Если значение больше 1, то это уменьшает вероятность повторения токенов. В данном случае значение равно 1.1, что означает, что модель будет менее склонна к повторениям.
- do_sample - если установлено значение True, модель будет генерировать текст, выбирая токены на основе их вероятностей (стохастически). Если False, модель всегда будет выбирать наиболее вероятный следующий токен (детерминированно).
- use_cache - параметр, который указывает, следует ли использовать кеширование внутренних состояний модели. Это может ускорить процесс генерации, но в некоторых случаях его лучше отключить. В данном примере кеширование отключено (False).
Сохраним изменения, после чего выполним скрипт:
python rugpt35.py
И вот, что ответила мне нейронка:
Сеть похоже решила изобразить сценку в которой бот и пользователь зачитывают куплеты стихотворения по очереди, были ещё другие занятные варианты, но не будем заострять на этом внимание.
Интерактивный чат
Теперь давайте попробуем сделать чуть более сложное решение, для его работы потребуется создать файл prompt.sh и сделать его исполняемым:
touch prompt.sh
chmod +x prompt.sh
Теперь откроем его в текстовом редакторе и наполним следующим содержимым:
Данный скрипт первым делом скачивает модифицированный мною файл generate_transformers.py, в качестве основы я взял пример из репозитория ru-gpts, но добавил поддержку опций load_in_8bit, load_in_4bit и device_map.
Далее в переменной model мы определяем название модели, которую необходимо использовать.
Следом идёт строка запуска python скрипта скачанного ранее, на вход ему передаются следующие параметры:
- --model_type=gpt2 - указывает тип модели (в данном случае GPT-2).
- --model_name_or_path=${model} - путь или имя модели. Здесь используется ранее созданная переменная model.
- --repetition_penalty=1.1 - штраф за повторение.
- --k=40 - параметр, который ограничивает количество верхних токенов, рассматриваемых при выборе следующего токена.
- --p=0.85 - вероятностный порог.
- --length=256 - максимальная длина генерируемого текста (в токенах).
- --stop_token='<|endoftext|>' - токен, при появлении которого генерация текста прекращается.
- --load_in_8bit - флаг, который указывает на загрузку модели в 8-битном формате. (вместо него можно использовать флаг --load_in_4bit)
Теперь запустим этот скрипт и посмотрим, что получилось:
./prompt.sh
По выводу консоли видно, что модель выполнила инициализацию после чего запустился бесконечный цикл интерактивной оболочки. Поэтому можно вводить какие-нибудь тексты, а нейросеть будет пытаться их продолжить (потому как, к сожалению, ruGPT-3.5 13B только это и умеет делать).
Попробуем немного поиграть с нейросетью:
В целом нейросеть ruGPT-3.5 13B генерирует хоть и не плохие ответы, но я бы не назвал их прям очень хорошими. По моим наблюдениям и с учётом тех экспериментов, которые я над ней проводил ей не помешало бы хорошее дообучение, но к сожалению для того чтобы выполнить это с оригинальной моделью (используя веса в формате float32) понадобится очень много видеопамяти, по разным прикидкам от 80 до 160 гигабайт VRAM.
Однако, есть способы выполнять дообучение по аналогии с запуском модели в формате 8bit (или 4bit) квантизации, данный метод называется QLoRA, но это уже тема одной из следующих публикаций.
Ну вот в целом и всё, что я хотел рассказать на сегодня.
Завершение
Довольно объёмная статья получилась, потому что мне хотелось максимально подробно рассказать про методы и принципы запуска больших языковых моделей на бюджетных видеокартах, но сделать это так, чтобы даже начинающий специалист понял что к чему.
Надеюсь мне удалось достигнуть желаемого результата и у вас получилось повторить данную процедуру без особых сложностей :)
Не забудьте поставить лайк, подписаться на канал, а также приглашаю ко мне на Telegram-канал на котором я публикую свои размышления, рассказываю о разных интересных новостях, а также делюсь своими наработками и опытом.
К тому же, если вы хотите поддержать мои усилия и вклад в развитие общества знаний, вы можете сделать пожертвование на CloudTips. Ваша поддержка поможет мне продолжать свою работу и делиться новыми открытиями с вами.