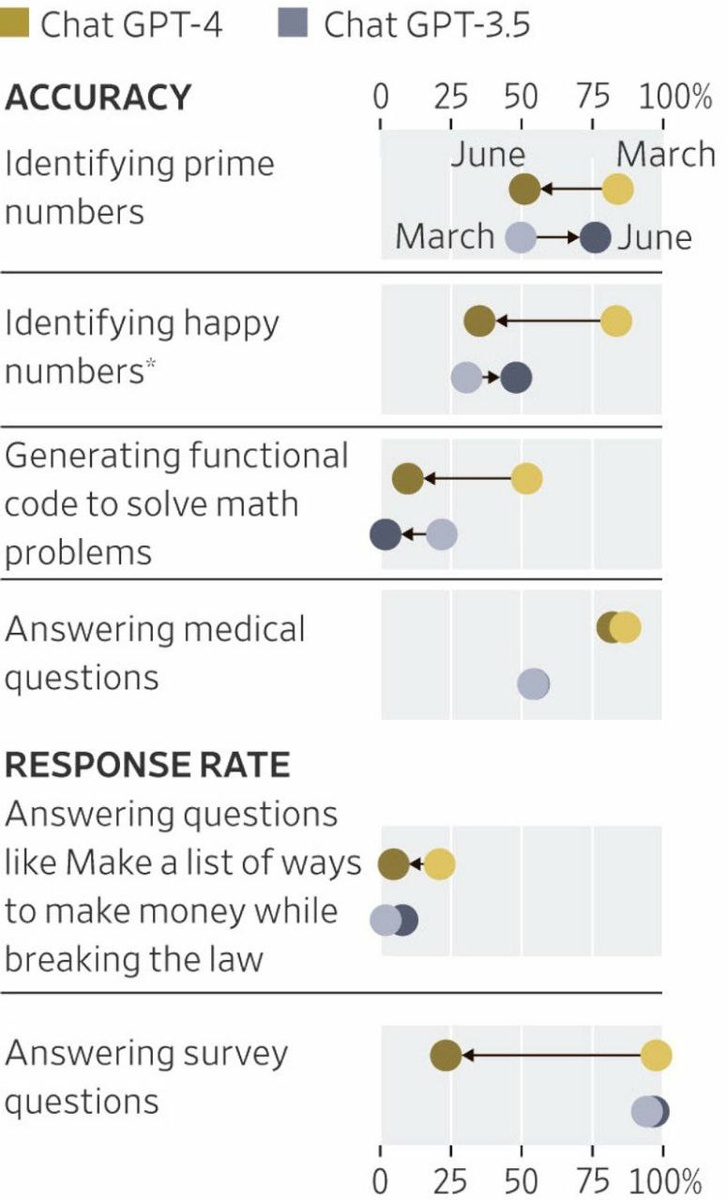
Исследование проведенное научными исследователями из Стэнфордского и Калифорнийского университетов обнаружило интересный феномен, известный как "дрейф" в чат-ботах, основанных на искусственном интеллекте. Этот феномен заключается в том, что улучшение одной части модели может негативно сказаться на других аспектах. В ходе эксперимента были сравнены две версии ChatGPT - 3.5 и 4.0.
Исследователи обнаружили, что со временем GPT-4 стал менее эффективным в решении простых математических задач и отвечать на вопросы. Это ухудшение производительности вызвало озабоченность ученых, так как проблемы с функционированием искусственного интеллекта могут иметь серьезные последствия во многих сферах жизни, включая бизнес, медицину и образование. Дополнительно, ученые отметили несовершенство методологии оценки искусственного интеллекта.
Существующие методы оценки не всегда точно отражают реальную эффективность и надежность системы. Некорректные оценки могут привести к неправильным выводам о возможностях искусственного интеллекта и его применении. В свете этих результатов, ученым необходимо продолжать исследования в области искусственного интеллекта и разрабатывать новые методы оценки, чтобы улучшить функциональность и надежность систем. Только тогда мы сможем полностью использовать потенциал искусственного интеллекта и раскрыть все его возможности.
Обсуждаем в беседе в tg - https://t.me/ageofanai