
В современном мире разрабатываемые системы становятся все сложнее и сложнее с каждым днем. Это похоже на строительство железных дорог - чем выше потребность, тем больше и разветвленнее становится дорожная сеть. Но, просто построить пути недостаточно. Чтобы все работало как часы, не задерживая доставку необходимых товаров и людей по рельсам, нужна еще и инфраструктура - узловые станции и те, кто этим всем будет управлять. Применительно к IT и разработке больших проектов с разветвленной сетью микросервисов, а также большим потоком данных для разных систем и служб, такой инфраструктурой могут считаться брокеры сообщений - как, например, RabbitMQ и Apache Kafka.
Если вернуться к примеру с железной дорогой, то можно продолжить аналогии. Так, каждая станция имеет свои особенности в управлении, свои подъездные маршруты для разных поездов и разные платформы. Так и две рассматриваемые нами системы брокеров имеют свои особенности, положительные и отрицательные стороны. Естественно, все это нужно тестировать, потому что данные “станции” являются узким местом в разработке. Здесь могут крыться различные ошибки, из-за которых “поезда” с сообщениями либо будут идти не по тем путям или же вообще будут “застревать”, мешая проезду и ломая сложную работы всей системы.
Следовательно, брокеры сообщений - это технология, обеспечивающая связь между приложениями и помогающая создать общий механизм интеграции для поддержки архитектур - облачных, микросервисных, бессерверных и гибридных. Но, в чем состоят различия и особенности тестирования брокеров сообщений? Попытаемся разобрать на примере двух распространенных представителей.
RabbitMQ.
RabbitMQ зачастую неформально называют просто “Кролик”. Это программный брокер сообщений на основе стандарта AMQP, написанный на языке Erlang и состоящий из следующих основных компонентов:
- Mnesia – распределенная СУБД реального времени для хранения сообщений, также написанная на языке Erlang – надстройка над ETS- и DETS-таблицами, предоставляющая уровень транзакций и распределенного выполнения;
- сервер;
- Различные библиотеки:
- библиотеки поддержки протоколов HTTP, XMPP и STOMP
- клиентские библиотеки AMQP для Java и .NET Framework;
- различные плагины (для мониторинга и управления через HTTP и веб-интерфейс, для передачи сообщений между брокерами и др.).
RabbitMQ поддерживает несколько языков программирования (Perl, Python, Ruby, PHP), а также обеспечивает горизонтальное масштабирование для построения кластерных решений. Поэтому RabbitMQ довольно часто применяется в различных Big Data проектах.
У двух систем имеется много общего, и под “много” в данном случае подразумевается то, из чего они обычно состоят - сервер, продюсеры и консьюмеры.
Устройство конкретно этого брокера упрощенно можно описать так:
- Есть поставщик сообщений (продюсер), отправляющий события, т.е. наши сообщения.
- Имеется очередь сообщений - своего рода почтовый ящик, где хранятся сообщения, отправленные продюсером. В очереди может храниться любое количество сообщений, которое отправили любое количество продюсеров любому количеству консьюмеров (т.е. подписчики, или получатели).
- Замыкают цикл консьюмеры (получатели) сообщений.
RabbitMQ, получая сообщения от продюсеров, отправляет им сообщение о приеме, после чего перенаправляет его консьюмерам. Те же, в свою очередь, сигнализируют либо об успешном принятии сообщения, либо об ошибке. Если все прошло успешно, то сообщение из очереди удаляется.
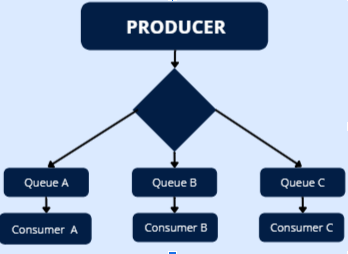
Именно эти моменты и требуют тщательного тестирования.
Для проверки очередей и сообщений в RabbitMQ можно воспользоваться инструментом RFHUtil. Это программная утилита, входящая в состав SupportPac IH03. Ее предназначение - это чтение и запись данных в очереди. RFHUtil позволяет отображать данные сообщения в различных форматах, не изменяя сами данные, а также создавать или изменять данные.
Как инструмент тестирования очередей данная утилита имеет достаточно обширный функционал, но интерес вызывает в основном возможность посмотреть, лежит ли что-то в конкретной очереди. Для этого после установки утилиты нужно ввести имя менеджера очередей и нажать “Load Names”
Исходя из выбранного менеджера, будут подгружены все имена очередей, которые можно просмотреть в выпадающем списке и выбрать интересующую.
После того, как очередь была выбрана, следует нажать кнопку “Read Q”.
После проделанных действий откроется вкладка “Data”, на которой будут отображены данные, лежащие в выбранной очереди.
Данный функционал с лихвой покрывает потребность в тестировании очередей, так как дает возможность посмотреть, что конкретно происходит в этом узловом соединении нашей маршрутной сети. Если с сообщением что-то не так, сообщение совсем не пришло или же не было должным образом прочитано, то с помощью RFHUtil можно будет понять, где именно кроется ошибка и сэкономить время команды разработки, локализовав проблему.
Данный инструмент также предлагает возможность записи сообщений в очередь. Для этого требуется подготовить и загрузить файл, сообщение из которого будет отправлено в очередь. В данном случае будет достаточно создать любой .TXT файл с сообщением.
После того как была выбрана очередь для загрузки сообщения следует:
1) Нажать “Open File”.
2) Загрузить ранее созданный файл с сообщением и нажать “Write Q”.
После этого можно увидеть, что сообщение успешно добавлено в очередь. Данная процедура может помочь в случае, если есть потребность протестировать возможность консьюмера принимать сообщения и обрабатывать их, но продюсер к этому времени еще не готов отправлять сообщения или некорректно настроен на очередь.
Apache Kafka
На первый взгляд может показаться, что Apache Kafka - это такой же брокер сообщений, как и RabbitMQ. Он состоит из тех же компонентов (продюсер, брокер и консьюмер), также пересылает сообщения от отправителя к получателю - в общем, с самого начала различия могут показаться не такими уж глобальными. Но, тем не менее, между RabbitMQ и Apache Kafka существует принципиальная разница.
Главным отличием является как способ хранения сообщений на брокере, так и процесс их потребления консьюмерами. Так, например, сообщения в Kafka не удаляются брокерами после их успешного прочтения. Они могут храниться днями и неделями, в зависимости от потребностей пользователей. Благодаря этому сообщения могут быть вычитаны множество раз. Это очень полезное свойство, так как одно и то же сообщение может предназначаться нескольким получателям, что значительно снижает потребность в отправке огромного количество сообщений от одного продюсера. При этом отличием будет являться способ получения сообщений. В отличие от RabbitMQ в Apache Kafka сообщения считываются непосредственно самими консьюмерами.
Схематично то как работает Apache Kafka можно изобразить следующим образом:
Для проверки того, как сообщения уходят и что лежит в различных топиках Kafka одним из самых распространенных инструментов остается Offset Explorer.
Для того, чтобы посмотреть сообщения, для начала следует подключиться к Kafka. Для этого в Offset Explorer нужно нажать на “Add New Cluster”, или, щелкнув правой кнопкой мыши на папке с кластерами, нажать “Add New Connection”. В любом случае окно с добавлением кластера откроется при первом запуске приложения.
В открывшемся окне добавления кластера следует добавить всю нужную информацию: имя, хост, порт и т.д.
Если ваша кафка защищена какими бы то ни было ключами доступа, то на вкладке Security можно добавить способ защиты и ключи для доступа.
Далее по нажатию кнопки “Add” можно добавить кластер и подключиться к нему. Откроется возможность посмотреть на то, какие имеются брокеры, консьюмеры, и то, что интересно в первую очередь - топики, куда пишутся отправленные сообщения.
Для просмотра самих сообщений нам нужно выбрать интересующий нас топик и нажать “Retrieve Massages”. После этого на экран будет выведен список всех сообщений, находящихся в выбранном топике, с указанием времени их записи и значениями, которые были отправлены.
В начале данные сообщения выводятся в формате Byte Array, что неудобно для чтения и понимания содержимого сообщений. Поэтому на вкладке Properties следует сменить Content Types на String. Это упростит просмотр содержимого сообщения.
Таким образом реализовано чтение сообщений в данном инструменте. Также, как и в RFHUtil имеется возможность записи сообщений в определенный топик. Для этого следует раскрыть сам топик и произвольно выбрать партицию для записи (своего рода единицу хранения сообщений).
После того как партиция была выбрана, следует перейти на вкладку “Data” и нажать “Add”, после чего будет открыто окно добавления сообщения в топик.
Таким образом можно решить проблему чтения и записи сообщений в Apache Kafka, что поможет сделать продукт, использующий данную технологию как можно качественнее.
Исходя из всего вышесказанного, можно сделать вывод, что на данный момент существует несколько распространенных брокеров сообщений для современных больших IT проектов. И в случае RabbitMQ, и в случае Apache Kafka имеются свои плюсы в использовании, а значит - обе системы могут встретиться на профессиональном пути QA. Задача при этом не меняется - необходимо предоставить как можно более качественный продукт конечному потребителю. Доступность инструментов для тестирования данных брокеров открывает возможность четкой локализации возникшей проблемы. Это положительно скажется на сроках ее решения, и тем самым повысит эффективность всей команды разработки.
Дзутцев Руслан Sr. QA-Engineer
____________________________________________________________________________________
Подпишитесь чтобы не пропустить новые статьи, впереди много интересного!
Deventica - Ускоряем цифровую трансформацию бизнеса, облегчаем переход к технологической независимости, разрабатываем, тестируем, сопровождаем. Наши контакты в шапке профиля.