Собирал на днях семантику для одного проекта и решил поделиться с вами получшившейся красотой) ссылка
посмотрите и если вам тоже нравится то, что вы видите то обязательно ознакомьтесь с этой статьей!
Ни для кого не секрет, что качественная проработка семантики это важный аспект не только в сео, но также и в директе, да где угодно, это сегментация вашей аудитории и полученные кластеры могут быть полезны в разных случаях будь то рекламные объявления или страницы на сайте
Но все также знают, что процесс сбора семантики максимально трудозатратный, а заказчик как обычно результат хочет сразу, так как быть? как быстро и качественно собрать семантику, чтобы дать результат в течение нескольких месяцев после начала работ?
Давайте я покажу вам как это делаю я
- Я выгружаю всю семантику из метрики: Отчеты → Источники → Поисковые запросы, тут смотрите как на ваше усмотрение брать год или весь диапазон
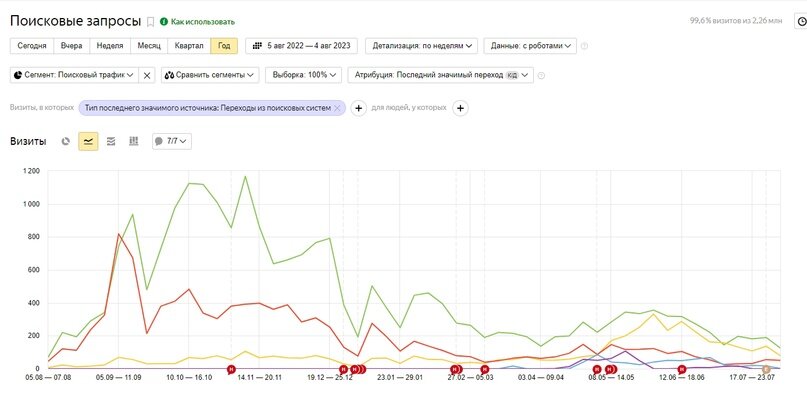
Нажимаю выгрузить данные таблицы
- Иду в вебмастер выбираю Статистика запросов → Популярные запросы, а потом избранные запросы
Также выгружаем
- Идем в Google Search Console
Экспортируем также, жалко, что Google позволяет лишь 1000 строк выгружать, но можно создать доп. фильтры по кликам или показам и выгружать диапазонами пока все не выгрузим
- Можно выгрузить данные из Google Analytics, но я обычно этого делаю.
- И заключительное это выгрузка по видимости из Keyso, но сервис платный! на кворке можно попросить за 500р выгрузить
Вбиваем ваш сайт
Потом собираем все эти запросы в один столбик Excel и удаляем дубликаты
Или через Google Excel
Дубли удалили, теперь нужно прогнать всю эту массу семантики через что-то что соберет частоты в вашем регионе, я обычно пользуюсь KeyCollector'om (программа платная) или Word-keeper'om (сервис тоже платный)
Через keyCollector как собирать частотки я думаю показывать нет смысла) те кто им пользуются и так знают как это сделать, а вот для Word-keeper покажу:
Регистрируемся, заходим, нажимаем
Вставляем наши фразы в окно слева, выбираем нужный нам регион, потом выбираем нужную нам частотность
если хотите сэкономить выберите сначала частотку в кавычках, прогоните ее, удалите все нули и пустые значения, а затем прогоните оставшиеся 2 вида частот
И запускаем
В итоге мы получим запросы с частотками
Затем я загружаю ее в KK4 да, к сожалению, без него все равно не обойтись
но если у вас его нет не расстраивайтесь в конце я напишу о способе как можно все это сделать без него.
Прогоняем запросы через поисковую выдачу 1, собираем позиции 2, и проставляем url позиции и релевантные url нашим запросам
Потом экспортируем все это дело в KeyAssort
Можно конечно сделать кластеризацию и внутри KK4, но для кластеризации мне больше нравится KeyAssort
Выбираем нужную нам силу кластеризации 1
Перетаскиваем запросы вправо 2
Экспортируем 3
Зачем я открываю все это дело в Excel и если у меня нету каких-то данных подгружаю их через функцию ВПР из других таблиц, если все есть то
Сортирую столбики с частотностями по убываю, а столбик с категорией по возрастанию, потом выделяю все CTR+A у удаляю все цвета с таблицы, перехожу во вкладку SEO-EXCEL если у вас ее еще нет то очень рекомендую!
И выбрав столбец С нажимаю красить все столбцы и получается что вверху у нас наиболее частотный запрос по «!» и он покрашен как начальный у кластера
Затем делаю еще один столбец
и ввожу туда =суммесли это сумма кластера, выбираю 2 раза столбец А, затем столбец G с самой точной частоткой и потом протягиваю на всю длинну и сортирую все кластеры по уменьшению этой частотки
В итоге мы получаем вот такую красоту ↓↓↓
https://docs.google.com/spreadsheets/d/1Fd5HN6CpkVgnCTCNP5e3r2mkj0mJ-bBoTWmP2lpnJRM/edit?usp=sharing
Почему это красота?) сейчас объясню
- Столбик B там ключи (фразы)
- Столбик С условное название категории (группы) этих запросов
- Стобики E, F, G частотка
- Столбик H сумма частоток кластера (группы запросов столбца С) считается по "!" частотке
- Столбик I это позиции какого-л. запроса в выдаче
- Столбик J это url этой позиции в выдаче
- Столбик K это что по запросу столбца B выводится ближайшее в выдаче по релевантности через оператор site:url
Вся таблица отсортирована от наиболее важных кластеров к менее важным сумме частот "!" в кластере
И что мы теперь можем со всем этим делать?
Во-первых, мы видим кластер самый частотный про номера автомобилей, мы видим что позиций по нему почти нету, значит нужно создать страницу под него, чтобы начать получать оттуда трафик, если он нам нужен.
Во-вторых, внутри кластера сразу есть вопросы для FAQ которые имеют частотку и будут давать доп охват по теме, например:
номер iccid автомобиля что это
iccid глонасс как узнать
что такое iccid в машине
где взять номер iccid автомобиля
iccid глонасс что это
Все это можно использовать для FAQ не только для уникализации, но и для получаения доп трафика на эту страницу
Прошу обратить внимание на вот этот кластер, все запросы в нем (столбец B) это самостоятельные кластера т.е 1 запрос один кластер им не нашлось пары
Идти прорабатывать лучше сверху вниз от наиболее важных к менее важным
В общем тут куча работы и доп трафика
Даже если это не совсем релевантный трафик (первый кластер) создав под него статью в нашем блоге мы начнем получать такой трафик и можем переводить его с блога на услуги специальными вставками типо: человек заходит читает и тут ему услуга по этой теме и какая-то часть трафика, условно 1% будет конверситироваться на услугу из этой статьи, а с учетом огромной частотки я думаю это неплохие будут цифры
Выше я сказал, что если у вас нету всех этих инструментов и вы не можете этого делать то вы можете обратиться ко мне или любому другому сео специалисту с подобной инструкцией и он вам все это сделает.
С заботой Андрей Орлов